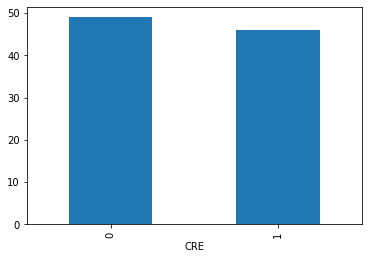𝔏ℑ𝔑'𝔖 𝔅𝔏𝔒𝔊
classification
2020-08-28
2 / 4
gan
OCGAN Pratice: CRE Bateria data
Hermit
/
2020-02-04
這次使用之前分析過的CRE資料,來嘗試使用OCGAN,但因原先資料CRE:NON比數為46:49,為了達到不平衡的效果,因此最後採用16:49的比例,從46個CRE中取隨機16個,而資料的訓練集以及驗證集比例為下: Train Set(CRE:Non): 6:19 Validation Set(CRE:Non): 10:30 接著我們將分為有使用OCGAN平衡數據集的資料以及未平衡數據集的資料進行分別建模,兩者皆使用SVM的方式建模,並且先透過LOOCV的方式在數據集Tuning模型,最後套入驗證集計算總準確率、f1 score、auc等,比較有無平衡的效果。 […]…
gan
OCGAN Tuning
Hermit
/
2020-01-16
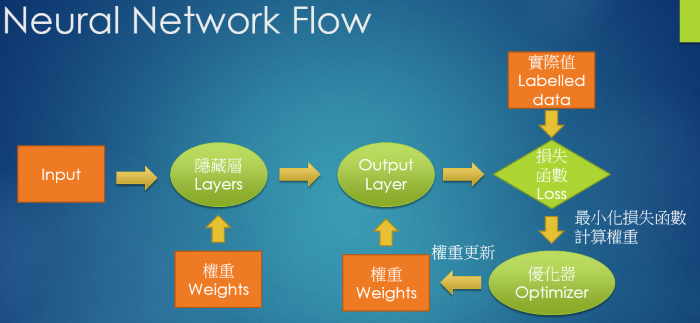
基本上生成樣本已經是可以達成的事情,目前就是調整gan各處的結構,如優化器、激活函數、損失函數等等,目前嘗試皆以randomforest(n=100)當作統一的模型。下圖是一般神經網路的結構: 而生成對抗網路則有生成器與判別器兩個神經網路的串接,因此排列組合十分多種,且echo的次數與每個組合的效果並不一定相同,不一定回傳越多次效果越好,因此想先比較完大部分組合後再從中擇優,以下是將之前信用卡資料切分為train:test為1:1後的比較結果,比較傳統oversampling、undersampling與Non Sampling的效果,結果如下圖: 接下來與gan進行比較,gan的各種組合下表…
machine-learning
Paper Review [LOTUS:Logistic Tree with Unbiased Selection]
Hermit
/
2019-12-26
因為修統計書報的關係,這次也被分配要報告一個章節,雖然那本書是工具書取向,但是發現該作者有在2004年寫了一篇有關logistic regression的演算法,他稱之為LOTUS,主要是希望可以解決當時logistic regression的一些問題。 Logistic Regression主要優勢是在他算法快、存處資源低;缺點是如果模型存在共線性、非線性、或交互作用存在,則模型並不好解釋。 為了克服以上問題,作者提出了一種模型:LOTUS(Logistic Regression with Unbiasd Selection) 通過樹狀分割數據並且fit不同的Logistic…
deep-learning
WGAN Practice On Credit Card Data
Hermit
/
2019-12-17
前幾篇我有提到WGAN在訓練過程中可以改善兩個神經網路loss很難調教的問題(很常判別器的loss下降,生成器的卻一直上升,或是情況相反),因此我將在此篇裡使用WGAN的規則來修改神經網路的一些參數,條件如下: […] The WGAN limits: 1.判別器最後一層去掉sigmoid 2.生成器和判別器的loss不取log 3.每次更新判別器的參數之後把它們的絕對值截斷到不超過一個固定常數c 4.不要用基於動量的優化算法(包括momentum和Adam),推薦RMSProp,SGD也行 […] import pandas as pd import numpy…
machine-learning
Fix The R Function
Hermit
/
2019-12-12
這禮拜我做的那個function執行順序上跟老師所要求的有所不同,因此這次將結果修改為老師所要的執行方式。 原先我以為是要先將所有資料的變數進行pca轉換後再進行分類器leave one out的訓練,因此是將訓練以及測試的資料同時PCA轉換,大致流程為下圖: 因此訓練資料的正交化與測試資料的正交是同時進行的,因此與老師所要求的流程上不同。 老師是希望先將資料切分為1:ALL-1,並以ALL-1的Training Set 來進行PCA轉換、訓練分類器,最後將測試資料乘上訓練用的PCA轉換矩陣,並將其結果帶入分類器上來驗證分類預測結果,以此循環進行LOOCV,流程大致如下圖: 因此最大的差別…
R
The R Function Definition for CRE Bacteria Data Analysis
Hermit
/
2019-12-10
這次是跟上次使用相同的資料,只是變成要定義一個規定格式的function,剛好上次的code裡面logistic regression的分類器有寫錯的部分,因此可以順便趁這次的機會修改之前錯誤的地方,部分內容可參考以前那篇blog(CRE Bacteria Data Analysis: https://hermitlin.netlify.com/post/2019/04/24/cre-bacteria-data-analysis/) 一樣我會將資料先進行倒轉,並且為前46個樣本上cre的標籤,後49則上非cre的標籤。 主要差異為,這次要進行pca,因此再倒轉資料時,並未挑選重要的前50個變…
««
«
1
2
3
4
»
»»