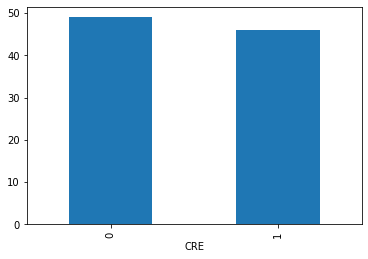𝔏ℑ𝔑'𝔖 𝔅𝔏𝔒𝔊
machine-learning
2020-08-28
1 / 4
machine-learning
Ghalat Machine Learning
Hermit
/
2020-08-28
這次來測試自動化機器學習套件:Ghalat Machine Learning, 主要針對回歸問題與分類問題的自動化學習。 目前套件具有以下功能: 1.自動特徵工程 2.自動選擇機器學習和神經網路模型 3.自動超參數調校 4.排序模型效果(根據交叉驗證分數) 5.推薦最佳模型 我將使用UCI breast cancer dataset(sklearn dataset)來測試此套件for分類的效果以及使用情況。 套件作者Github:https://github.com/Muhammad4hmed/Ghalat-Machine-Learning Pypl套件說明:…
deep-learning
Auto Encoder for Anomaly Detection
Hermit
/
2020-02-29
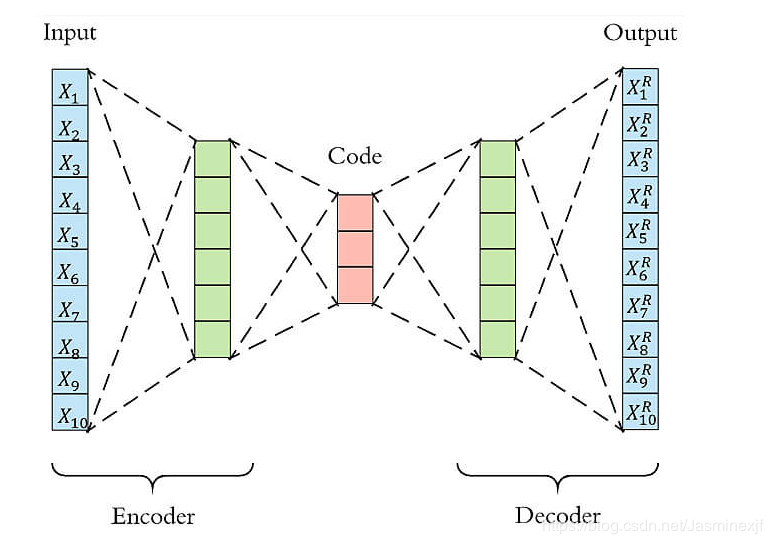
這禮拜在撰寫論文的時候,因為有一段需要更詳細說明所謂的Anomaly Detection,因而發現了一個也可以進行相同工作的方法-“Auto Encoder”,且他號稱有著更佳的分類效果,因此就看了一些介紹此方法的文章以及實作,下面我將使用breast cancer data的前一百筆當作練習範本,嘗試建立一個Auto Encoder for Anomaly Detection。 […] Autoencoder是一種無監督式學習模型。本質上它使用了一個神經網絡來產生一個高維輸入的低維表示。 Autoencoder與主成分分析PCA類似,但是Autoencoder在使用非線性激活函…
gan
Compare to OCGAN & SMOTE & ADASYN in CRE data Simulation
Hermit
/
2020-02-25
與上禮拜那篇文章一樣,只是這次將資料改為CRE data,希望也有良好的表現。 […] import pandas as pd import numpy as np from sklearn import datasets # import some data to play with df = pd.read_csv('C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/NSYSU/fu_chung/bacterial/123.csv') x = df.iloc[:,0:1471] y =…
machine-learning
2019 nCov Data Simple Analysis
Hermit
/
2020-02-21
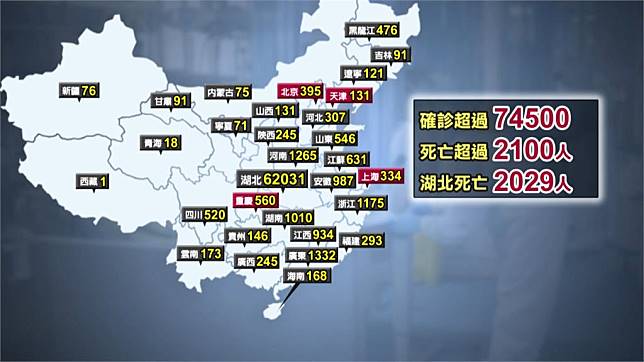
今年2020剛開始便被這個來自2019年傳出的2019n-Cov(俗稱的武漢肺炎病毒)鬧的人心惶惶,而在我們偉大的中國共產黨領導下,疫情也是如雨後春筍般的在中國甚至鄰近國家散播,而前陣子有個同學在偉大中國共產黨疫情通報網(link: http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml) 上,將疫情人數的數量做成表,並用excel繪製了一個簡單的圖表以及用Benford’s law檢查了資料是否有造假的可能,但因疫情假期還很長,因此變跟他要了這個(基本上是造假的)data,想說跑一些簡單的資料探勘看看會不會有有趣的結果。 […]…
machine-learning
Find The Special Sample in CRE data
Hermit
/
2020-02-19
上次在挑選變數並建立分類模型的loocv時(link :https://hermitlin.netlify.com/post/2020/02/14/cre-features-selection/) ,最高的準確率來自adaboost的結果,且落在使用60~70個randomforest importance的變數,但當時多個模型準確率為0.989473684,即存在一個樣本預測錯誤,因此想知道是否在這些模型中,預測錯誤的皆為同一筆樣本。本次將預測的結果先行挑出,並將錯誤的樣本index建立成表,以方便觀察多為那些樣本為容易預測失敗的樣本。 […] 先讀入資料與之前R…
gan
Compare to OCGAN & SMOTE & ADASYN in breast cancer data Simulation
Hermit
/
2020-02-18
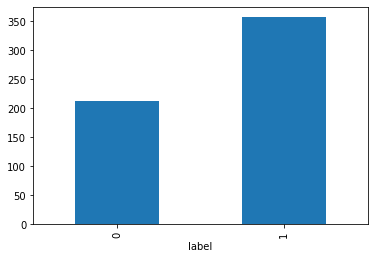
這次我使用sklearn內建的資料集breast-cancer(原始資料來源:https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)) ,先將原資料以7:3比例建立一個的資料分類器出來,之後把其中一個類別挑出,並使用各種oversampling的方法來模擬樣本,並最終將模擬後的資料套回最初的模型當中,比較各方法產生的樣本能否在分類器當中回到原本的類別當中。 […] 讀取sklearn的資料並轉為dataframe: import pandas as pd import numpy…
««
«
1
2
3
4
»
»»