𝔏ℑ𝔑'𝔖 𝔅𝔏𝔒𝔊
R
2020-08-28
1 / 3
R
Location selection research for Nursing home
Hermit
/
2020-04-21
這學期有參加一個內政部的數據競賽,主要是想做老幼托育的選址策略, 在現今台灣社會上越來越多三明治族(三明治族指得是,上有父母、下有孩子,自己又有工作在身。)的情況下,老人照護與托兒的需求也逐漸提升。目前全日本各地共有1400多家兒童老人日照中心,這類型的照顧機構在日本已遍地開花。 我們的產品即為「老幼共托,托育中心選址策略模型」,主要利用大數據分析的方式,建立一套考慮交通、環境、照護需求的預測分析模型,讓政府能找出目標受眾,並結合政府立案與民間配合,於適當的地點創造一個個適合照護兒童與老人的日照中心,並提供給目標受眾。 主要是使用內政部人口結構資料來找尋各村里托育的需求量,並…
R
Crawler for delay load web page
Hermit
/
2020-04-20
這禮拜也有同網站的內容要爬(https://heavenlyfood.cn/books/index.php?id=4000) ,其主要結構與上星期的篇章雷同,因此沿用上星期的code,只是在最後抓取文章文件的時候,有遇到一些問題,如下圖: 如果有爬蟲經驗的人應該可以看出他文章主要是在一個名稱叫做div#c 這個nodes下存放,而我在整頁結構確認後,便使用R去執行html_nodes去抓這些節點,但經由文字提取的函數,卻抓不到任何文字。 後來發現,文章文字的內容,並不在文章的這個連結內,而是頁面結構先載入,而後內容才進行加載,這個一般稱為delay-load的問題,主要指我們想爬取的內容並非第…
R
Buliding a Crawler for UserAgent website
Hermit
/
2020-04-13
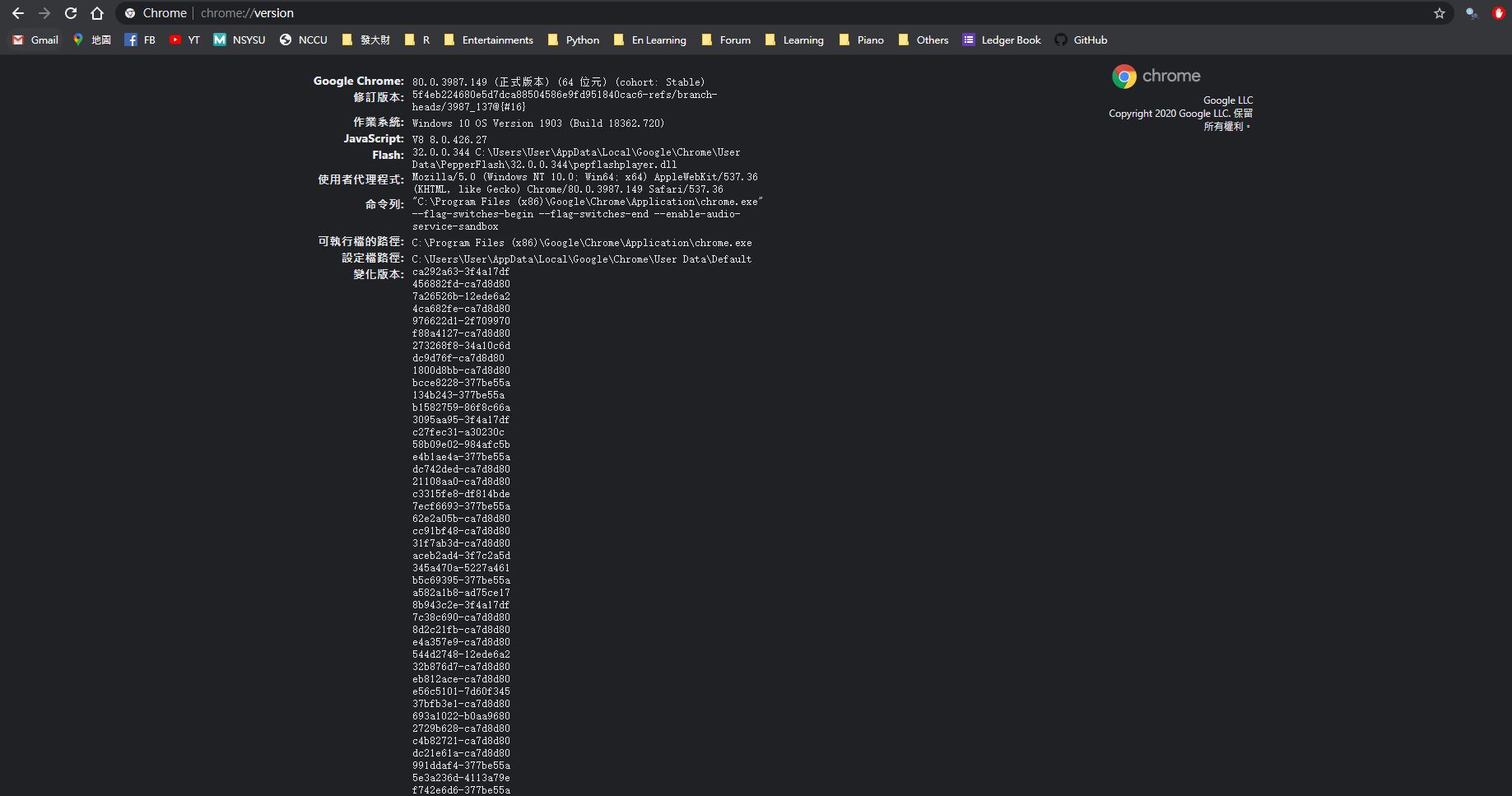
現在有許多網站使用UserAgent,主要是向用戶端發送用戶代理請求,讓用戶端提交一個特定的字串來標示自己的身份,以及相關的訊息,例如裝置、作業系統、應用程式,來表明使用的身份。而服務端一接收到這樣的身份識別後,就可以做出相對應的動作,例如為PC與mobile使用者,導向至給適合你裝置類型的網頁,進而提升使用者體驗。而在Chrome裡面,輸入chrome://version/ 就會看到類似如下代碼:使用者代理程式 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko)。 問題就…
Python
CRE data features selection
Hermit
/
2020-02-10
這次僅針對CRE data的模型變數選擇,主要以下面python的forward backward selection的方式進行挑選,主要方式為:將所有資料的百分之六十切出,進行變數篩選,並使用loocv的方式比較不同變數模型的準確度差異。 […] import pandas as pd import numpy as np df = pd.read_csv('C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/NSYSU/fu_chung/bacterial/123.csv') from…
machine-learning
Fix The R Function
Hermit
/
2019-12-12
這禮拜我做的那個function執行順序上跟老師所要求的有所不同,因此這次將結果修改為老師所要的執行方式。 原先我以為是要先將所有資料的變數進行pca轉換後再進行分類器leave one out的訓練,因此是將訓練以及測試的資料同時PCA轉換,大致流程為下圖: 因此訓練資料的正交化與測試資料的正交是同時進行的,因此與老師所要求的流程上不同。 老師是希望先將資料切分為1:ALL-1,並以ALL-1的Training Set 來進行PCA轉換、訓練分類器,最後將測試資料乘上訓練用的PCA轉換矩陣,並將其結果帶入分類器上來驗證分類預測結果,以此循環進行LOOCV,流程大致如下圖: 因此最大的差別…
R
The R Function Definition for CRE Bacteria Data Analysis
Hermit
/
2019-12-10
這次是跟上次使用相同的資料,只是變成要定義一個規定格式的function,剛好上次的code裡面logistic regression的分類器有寫錯的部分,因此可以順便趁這次的機會修改之前錯誤的地方,部分內容可參考以前那篇blog(CRE Bacteria Data Analysis: https://hermitlin.netlify.com/post/2019/04/24/cre-bacteria-data-analysis/) 一樣我會將資料先進行倒轉,並且為前46個樣本上cre的標籤,後49則上非cre的標籤。 主要差異為,這次要進行pca,因此再倒轉資料時,並未挑選重要的前50個變…
««
«
1
2
3
»
»»