這次是跟上次使用相同的資料,只是變成要定義一個規定格式的function,剛好上次的code裡面logistic regression的分類器有寫錯的部分,因此可以順便趁這次的機會修改之前錯誤的地方,部分內容可參考以前那篇blog(CRE Bacteria Data Analysis: https://hermitlin.netlify.com/post/2019/04/24/cre-bacteria-data-analysis/)
一樣我會將資料先進行倒轉,並且為前46個樣本上cre的標籤,後49則上非cre的標籤。
主要差異為,這次要進行pca,因此再倒轉資料時,並未挑選重要的前50個變數,而是將1000多個變數倒轉後直接進行pca,並用數個主成分來進行分類預測。
下面這張圖為指導老師用mathematica跑完後呈現的結果,
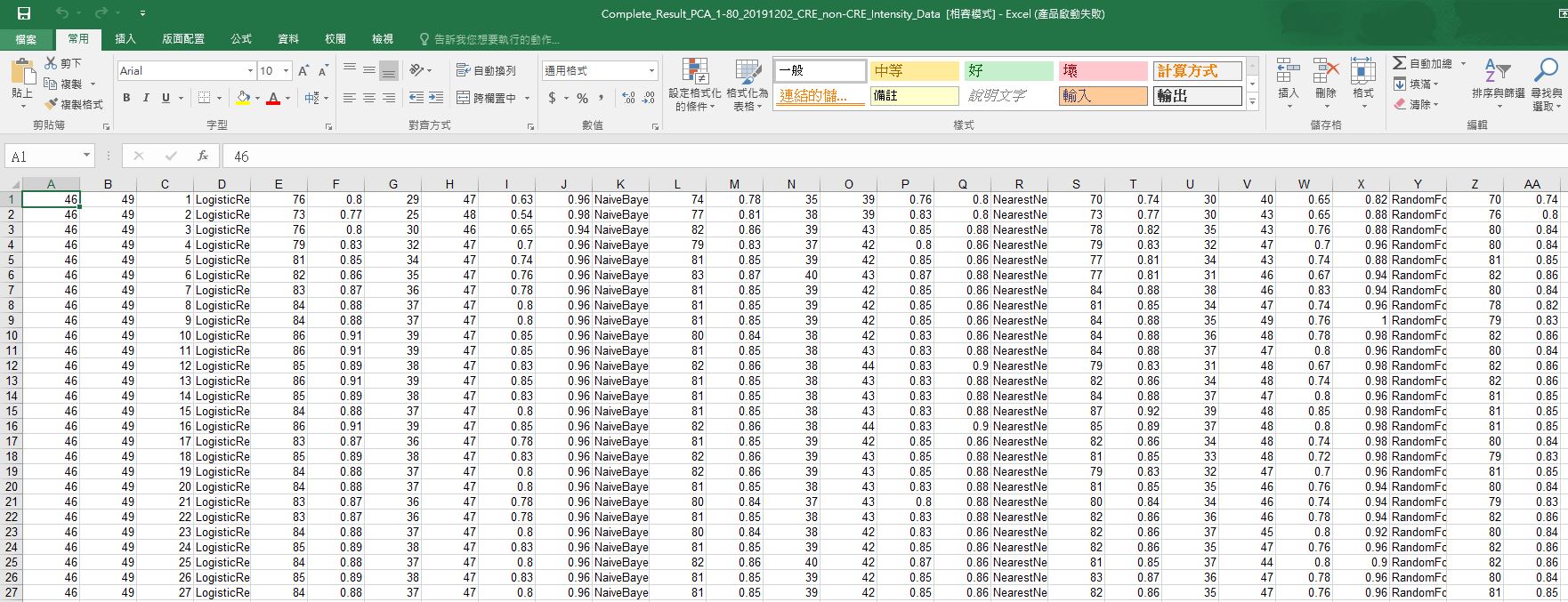
分別為CRE個數、非CRE個數、使用多少主成分、方法名稱、總體預測正確個數、總體準確率、CRE正確個數、非CRE正確個數、CRE準確率、非CRE準確率。
他希望我定義一個R function來直接建立這個形式的輸出,這也是我第一次定義一個較複雜的function,在除錯上確實花了一點時間,但最後還是完成了這隻code,下面將一一說明。
Data processing
Read data
先將資料讀入r
data_csv <- read.csv("C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/NSYSU/fu_chung/bacterial - PCA/20191202_1471_CRE_46-non-CRE_49_Intensity.csv")Rearrange
使用tidyverse將資料重新排整,主要將蛋白質的影響轉至columns,以樣本數作為rows,並在導轉後幫樣本進行labeling。
if (!require(tidyverse)) install.packages('tidyverse')
library(tidyverse)
#sort data by p.value
data_csv <- arrange(data_csv,p.value)
#transpose data
name_protein <- data_csv[,1]
data <- as.data.frame(t(data_csv))
data <- data[-c(1:3),]
#data name
name_variable <- names(data)
data_name <- data.frame(name_variable,name_protein)
data_name <- as.data.frame(t(data_name))
#label CRE as factor
data$CRE <- as.factor(c(rep(1,46),rep(0,49)))PCA
對資料(不包含Response)進行PCA,並建立新的dataframe為data_pca
pca <- prcomp(~.-CRE, data=data, center=TRUE, scale=TRUE)
data_pca <- as.data.frame(pca$x)
data_pca$CRE <- data$CRE Bulid the Classificators
在這裡我會先定義完整個function,接著使用定義好的function來輸出我們要的表格。
Def function
先在function外部切好cre以及非cre資料,這樣才不會每次run function時都做重複的事情浪費運算效率。
function的input總共有8個,分別為CRE樣本個數、非CRE樣本個數、是否要運算Logistic Regression、是否要運算Naive Bayes、是否要運算K-NearestNeighbors、是否要運算Random Forest、是否要運算Support Vector Machine以及要幾個主成分作為變數,但分類器都已預設為執行,因此僅需輸入其餘三者即可運行。
function內部前面以重組資料至df為主,會先重組新的樣本數資料至df1,在依據需要的pca個數切入df,後續分類器則都以df進行分析,這次一樣是使用LOOCV的方式進行運算分析,因此最終也皆會以LOOCV的結果呈現,至於方法的超參數皆可在function內部進行調整。這裡有一些預設值:
1.random forest, n = 150
2.knn, k = 10
3.logistic regression, div p in 0.5
4.svm & naive bayes all default
#filter cre $ non-cre
cre = data_pca[which(data_pca$CRE == 1),]
non = data_pca[which(data_pca$CRE == 0),]
#classification function
pca.clf <- function(num_cre,num_ncre,lgr = TRUE,nb = TRUE,knn = TRUE,rf = TRUE,svm = TRUE,pca){
#merge the data by num
df1 = rbind(cre[sample(dim(cre)[1],num_cre),],non[sample(dim(non)[1], num_ncre),])
#filter pca num
df = as.data.frame(df1[,c(1:pca)])
names(df) = names(df1[c(1:pca)])
df$CRE = df1$CRE
#ml model training
#svm
if(svm){
if (!require(e1071))install.packages('e1071')
library(e1071)
test.pred <- vector()
for(i in c(1:dim(df)[1])){
train = df[-i, ]
test = df[i, ]
svm_model = svm(formula = CRE ~ .,data = train)
test.pred[i] = as.integer(predict(svm_model, test))-1
}
#result present
confus.matrix = table(test.pred,df$CRE)
svm <- c("SupportVectorMachine",sum(diag(confus.matrix)),sum(diag(confus.matrix))/sum(confus.matrix),confus.matrix[2,2],as.integer(confus.matrix[1,1]),sum(confus.matrix[2,2])/sum(confus.matrix[,2]),sum(confus.matrix[1,1])/sum(confus.matrix[,1]))
}
#rf
if(rf){
if (!require(randomForest)) install.packages('randomForest')
library(randomForest)
test.pred <- vector()
for(i in c(1:dim(df)[1])){
train = df[-i, ]
test = df[i, ]
rf_model = randomForest(CRE~.,data=train,ntree=150# num of decision Tree
)
test.pred[i] = as.integer(predict(rf_model, test))-1
}
#result present
confus.matrix = table(test.pred,df$CRE)
rf <- c("RandomForest",sum(diag(confus.matrix)),sum(diag(confus.matrix))/sum(confus.matrix),confus.matrix[2,2],as.integer(confus.matrix[1,1]),sum(confus.matrix[2,2])/sum(confus.matrix[,2]),sum(confus.matrix[1,1])/sum(confus.matrix[,1]))
}
# knn
if(knn){
if (!require(class))install.packages("class")
library(class)
test.pred <- vector()
for(i in c(1:dim(df)[1])){
train = df[-i, ]
test = df[i, ]
test.pred[i] <- knn(train = train[,-length(train)], test = test[,-length(test)], cl = train[,length(train)], k = 5) # knn distance = 5
#test.pred[i] = as.integer(predict(knn_model, test))-1
}
#result present
confus.matrix = table(test.pred,df$CRE)
knn <- c("NearestNeighbors",sum(diag(confus.matrix)),sum(diag(confus.matrix))/sum(confus.matrix),confus.matrix[2,2],as.integer(confus.matrix[1,1]),sum(confus.matrix[2,2])/sum(confus.matrix[,2]),sum(confus.matrix[1,1])/sum(confus.matrix[,1]))
}
# nb
if(nb){
test.pred <- vector()
for(i in c(1:dim(df)[1])){
train = df[-i, ]
test = df[i, ]
nb_model=naiveBayes(CRE~., data=train)
test.pred[i] = as.integer(predict(nb_model, test))-1
}
#result present
confus.matrix = table(test.pred,df$CRE)
nb <- c("NaiveBayes",sum(diag(confus.matrix)),sum(diag(confus.matrix))/sum(confus.matrix),confus.matrix[2,2],as.integer(confus.matrix[1,1]),sum(confus.matrix[2,2])/sum(confus.matrix[,2]),sum(confus.matrix[1,1])/sum(confus.matrix[,1]))
}
#lgr
if(lgr){
test.pred <- vector()
df$CRE = as.numeric(df$CRE)-1
for(i in c(1:dim(df)[1])){
train = df[-i, ]
test = df[i, ]
lr_model<-glm(formula=CRE~.,data=train,family=binomial)
test.pred[i] <- ifelse(predict(lr_model, test,type = "response") > 0.5, 1, 0)
}
#result present
confus.matrix = table(test.pred,df$CRE)
lgr <- c("LogisticRegression",sum(diag(confus.matrix)),sum(diag(confus.matrix))/sum(confus.matrix),confus.matrix[2,2],as.integer(confus.matrix[1,1]),sum(confus.matrix[2,2])/sum(confus.matrix[,2]),sum(confus.matrix[1,1])/sum(confus.matrix[,1]))
}
#return results
result <- c(num_cre,num_ncre,pca,lgr,nb,knn,rf,svm)
return(result)
}Generate results
如果你想要一份24:24的樣本進行主成分1個至25個的比較列表,則可執行下列的迴圈進行運算。
a = as.data.frame(t(pca.clf(24,24,pca=1)))
for(i in c(2:25)){
b = as.data.frame(t(pca.clf(24,24,pca=i)))
a = rbind(a,b)
}names columns
因資料上未取名,這裡上Columns names
names(a) = c("num_cre","num_non","num_pca","method","right_pred_num","acc","right_pred_cre_num","right_pred_ncre_num","right_pred_cre_acc","right_pred_ncre_acc","method","right_pred_num","acc","right_pred_cre_num","right_pred_ncre_num","right_pred_cre_acc","right_pred_ncre_acc","method","right_pred_num","acc","right_pred_cre_num","right_pred_ncre_num","right_pred_cre_acc","right_pred_ncre_acc","method","right_pred_num","acc","right_pred_cre_num","right_pred_ncre_num","right_pred_cre_acc","right_pred_ncre_acc","method","right_pred_num","acc","right_pred_cre_num","right_pred_ncre_num","right_pred_cre_acc","right_pred_ncre_acc")write csv
最後寫出csv
write.csv(a,file = "pca_result.csv",row.names = FALSE)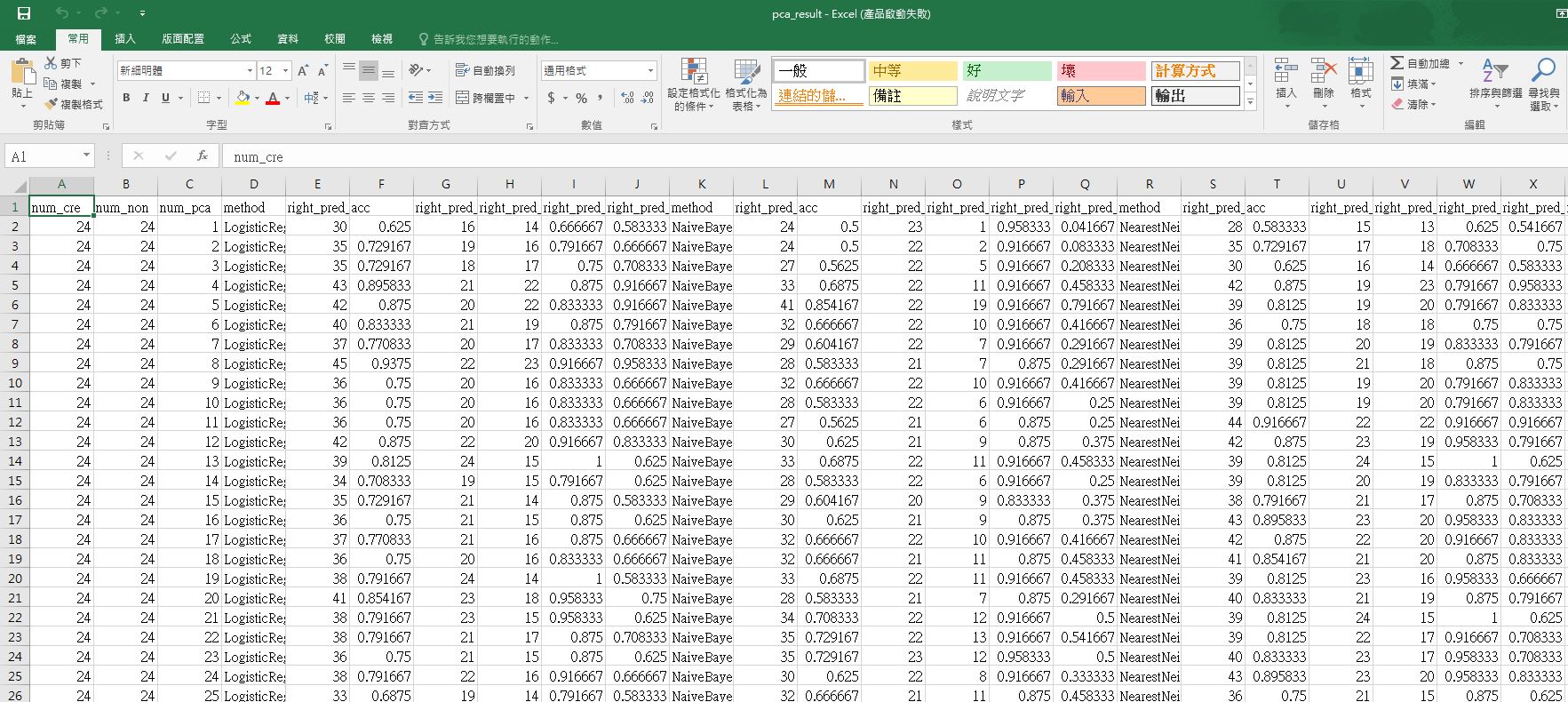
大致上是這樣,雖然function內部的迴圈感覺可以再更優化,但再看看之後有沒有時間吧…