在資料探勘中,異常檢測:anomaly detection對不符合預期模式或資料集中其他專案的專案、事件或觀測值的辨識。 通常異常專案會轉變成銀行欺詐、結構缺陷、醫療問題、文字錯誤等類型的問題。異常也被稱為離群值、新奇、噪聲、偏差和例外。
特別是在檢測濫用與網路入侵時,有趣性物件往往不是罕見物件,但卻是超出預料的突發活動。這種模式不遵循通常統計定義中把異常點看作是罕見物件,於是許多異常檢測方法(特別是無監督的方法)將對此類資料失效,除非進行了合適的聚集。相反,群集分析演算法可能可以檢測出這些模式形成的微群集。
有三大類異常檢測方法。在假設資料集中大多數實體都是正常的前提下,無監督異常檢測方法能通過尋找與其他資料最不匹配的實體來檢測出未標記測試資料的異常。監督式異常檢測方法需要一個已經被標記「正常」與「異常」的資料集,並涉及到訓練分類器(與許多其他的統計分類問題的關鍵區別是異常檢測的內在不均衡性)。半監督式異常檢測方法根據一個給定的正常訓練資料集建立一個表示正常行為的模型,然後檢測由學習模型生成的測試實體的可能性。
###############################以上出自於維基百科###################################
One Class Learning則為非監督式學習的異常檢測,此方法也可用於高度不平衡資料,將極少數組類別作為異常值處理,但因為單分類學習方法為非監督式學習,因此在有異常標籤的情況下,效果不比監督式學習來的更好,但若是該資料無異常標籤,抑或是分類點標籤不明確,則這類演算法便成為首選。
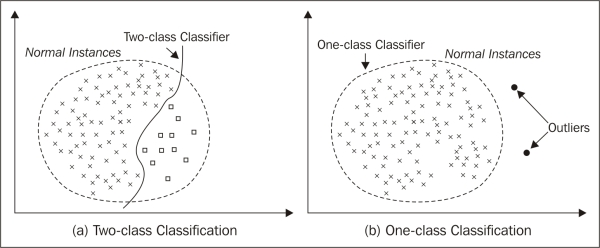
上圖比較單分類與二元分類的概念性差異。
One Class Learning裡幾個常見的方法有: one class SVM、Isolation Forest、one-class neural networks等等。這裡就簡介one class SVM、Isolation Forest以及實際做一次異常檢測。
1.One Class Support Vector Machine
1.1 One Class SVM Algorithm
One Class SVM也是屬於支持向量機大家族的,但是它和傳統的基於監督學習的分類回歸支持向量機不同,它是無監督學習的方法,也就是說,它不需要我們標記訓練集的輸出標籤。
那麼沒有類別標籤,我們如何尋找劃分的超平面以及尋找支持向量機呢? One Class SVM這個問題的解決思路有很多。這裡只講解一種特別的思想SVDD,對於SVDD來說,我們期望所有不是異常的樣本都是正類別,同時它採用一個超球體而不是一個超平面來做劃分,該算法在特徵空間中獲得數據周圍的球形邊界,期望最小化這個超球體的體積,從而最小化異常點數據的影響。
假設產生的超球體參數為中心o 和對應的超球體半徑r >0,超球體體積V(r) 被最小化,中心o 是支持行了的線性組合;跟傳統SVM方法相似,可以要求所有訓練數據點xi到中心的距離嚴格小於r。但是同時構造一個懲罰係數為 C 的鬆弛變量 ζi ,優化問題入下所示:
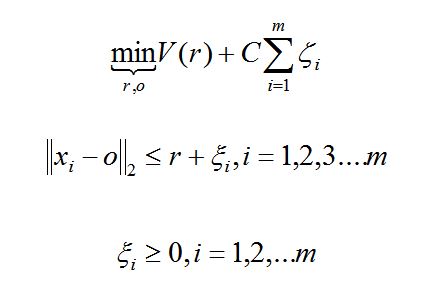
採用拉格朗日對偶求解之後,可以判斷新的數據點 z 是否在內,如果 z 到中心的距離小於或者等於半徑 r ,則不是異常點,如果在超球體以外,則是異常點。
1.2 OneClassSVM & Binary SVM difference
如果將分類算法進行劃分,根據類別個數的不同可以分為單分類,二分類,多分類。常見的分類算法主要解決二分類和多分類問題,預測一封郵件是否是垃圾郵件是一個典型的二分類問題,手寫體識別是一個典型的多分類問題,這些算法並不能很好的應用在單分類上,但是單分類問題在工業界廣泛存在,由於每個企業刻畫用戶的數據都是有限的,很多二分類問題很難找到負樣本,即使用一些排除法篩選出負樣本,負樣本也會不純,不能保證負樣本中沒有正樣本。所以在只能定義正樣本不能定義負樣本的場景中,使用單分類算法更合適。
單分類算法只關注與樣本的相似或者匹配程度,對於未知的部分不妄下結論。
典型的二類問題:識別郵件是否是垃圾郵件,一類“是”,一類“不是”。
典型的多類問題:人臉識別,每個人對應的臉就是一個類,然後把待識別的臉分到對應的類去。
而OneClassClassification,它只有一個類,屬於該類就返回結果“是”,不屬於就返回結果“不是”。
其區別就是在二分類問題中,訓練集中就由兩個類的樣本組成,訓練出的模型是一個二分類模型;而OneClassClassification中的訓練樣本只有一類,因此訓練出的分類器將不屬於該類的所有其他樣本判別為“不是”即可,而不是由於屬於另一類才返回“不是”的結果。
現實場景中的OneCLassClassification例子:現在有一堆某商品的歷史銷售數據,記錄著買該產品的用戶信息,此外還有一些沒有購買過該產品的用戶信息,想通過二分類來預測他們是否會買該產品,也就是兩個類,一類是“買”,一類是“不買”。當我們要開始訓練二分類器的時候問題來了,一般來說沒買的用戶數會遠遠大於已經買了的用戶數,當將數據不均衡的正負樣本投入訓練時,訓練出的分類器會有較大的bisa(偏向值)。因此,這時候就可以使用OneClassClassification 方法來解決,即訓練集中只有已經買過該產品的用戶數據,在識別一個新用戶是否會買該產品時,識別結果就是“會”或者“不會”。(Reference from:https://www.cnblogs.com/wj-1314/p/10701708.html)
1.3 OneClassSVM example
這次的data都是國泰資料競賽資料,主要依據131的變數去預測客戶是否投保,投保比例為98:2,因此為imbalance data,這次使用非監督式學習方法,並檢測是否使用這類方法能找出高auc的預測分類器,但單純以結果來說,並不如平衡抽樣的監督式學習模型來的好 。
import pandas as pd
import numpy as np
data = pd.read_csv("C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/Contests/ct_contest/train_11.csv",engine="python")
data = data.iloc[:,1:132]
from sklearn.model_selection import train_test_split
va_X = data.drop(['Y1'], axis=1)
va_y = data["Y1"]#one class svm
data1 = data.dropna(axis=1,how='any')# del NAs
va_X = data1.drop(['Y1'], axis=1)
va_y = data1["Y1"]
from sklearn import svm
clf = svm.OneClassSVM(nu=0.02, kernel='rbf', gamma=0.1)
clf.fit(va_X)
y_pred_train = pd.DataFrame(clf.predict(va_X))
ary = np.array(va_y)
for i in range(100000):
if ary[i] > 0:
ary[i] = -1
else:
ary[i] = 1
s1 = pd.concat([pd.DataFrame(ary),y_pred_train],axis=1)#AUC counting
from sklearn import metrics
test_auc = metrics.roc_auc_score(ary,y_pred_train)
print test_auc0.64562123127591072.Isolation Forest
2.1 Isolation Forest Algorithm
我們先用一個簡單的例子來說明 Isolation Forest 的基本想法。假設現有一組資料(如下圖所示),我們要對這組資料進行隨機切分,希望可以把點“星”區分出來。具體的,確定一個維度的特徵,並在最大值和最小值之間隨機選擇一個值 x ,然後按照小於 x 和 大於等於x 可以把資料分成左右兩組。然後再隨機的按某個特徵維度的取值把資料進行細分,重複上述步驟,直到無法細分,直到資料不可再分。直觀上,異常資料由於跟其他資料點較為疏離,可能需要較少幾次切分就可以將它們單獨劃分出來,而正常資料恰恰相反。這正是 Isolation Forest(IForest)的核心概念。
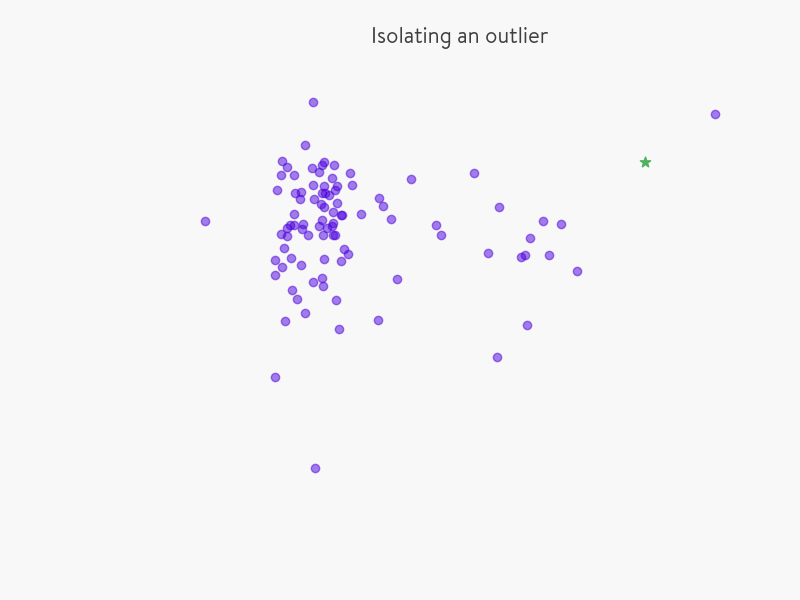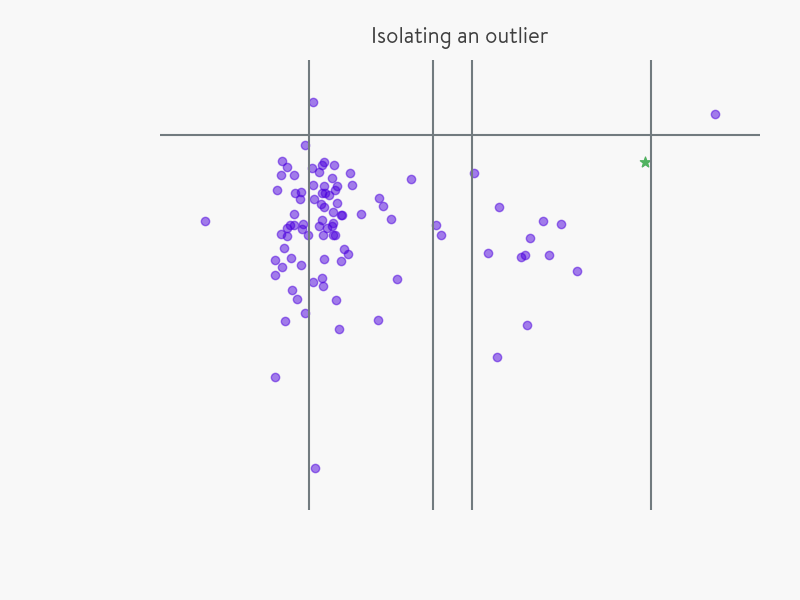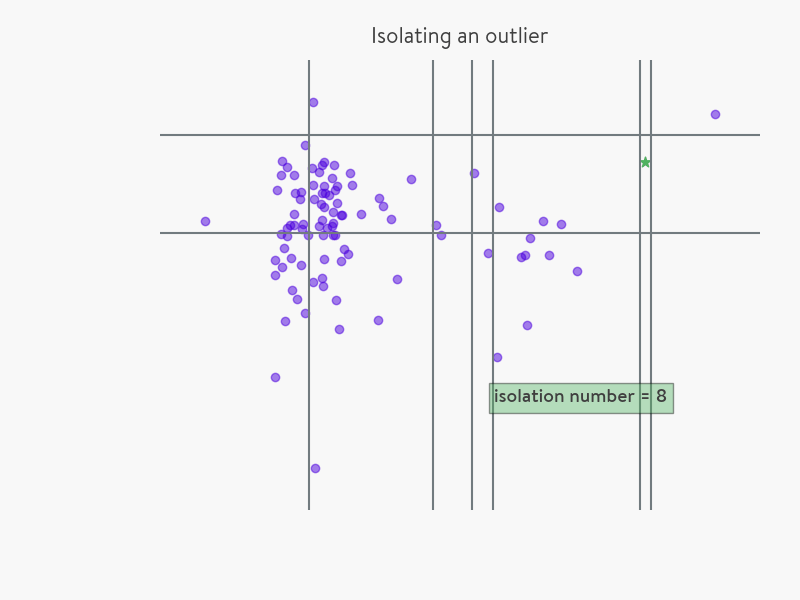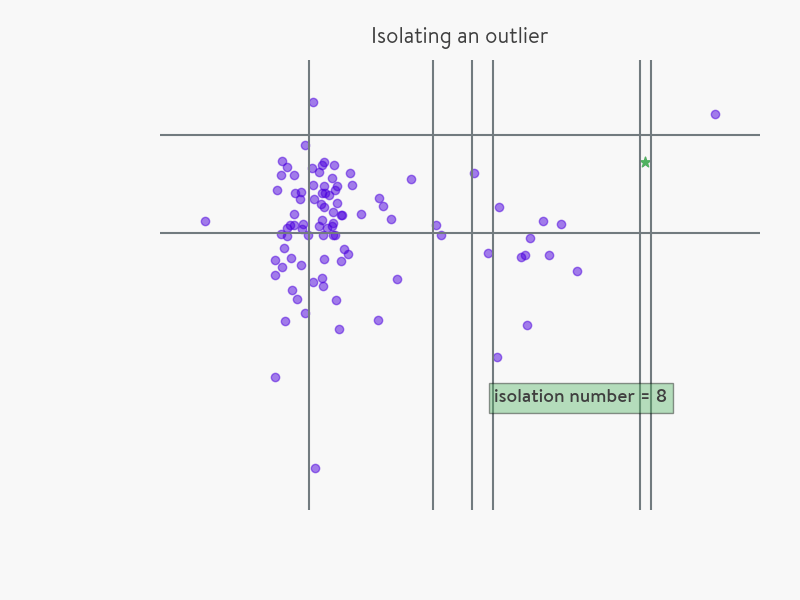
iForest (Isolation Forest)孤立森林 是一個基於Ensemble的快速異常檢測方法,具有線性時間複雜度和高精準度。IF採用二叉樹去對資料進行切分,資料點在二叉樹中所處的深度反應了該條資料的“疏離”程度。整個演算法大致可以分為兩步:iForest屬於Non-parametric和unsupervised的方法,即不用定義數學模型也不需要有標記的訓練。怎麼來切這個資料空間是iForest的設計核心思想,本文僅介紹最基本的方法。由於切割是隨機的,所以需要用ensemble的方法來得到一個收斂值(蒙特卡洛方法),即反覆從頭開始切,然後平均每次切的結果。iForest 由t個iTree(Isolation Tree)孤立樹組成,每個iTree是一個二叉樹結構,其實現步驟如下:
訓練:構建一棵 iTree 時,先從全量資料中抽取一批樣本,然後隨機選擇一個特徵作為起始節點,並在該特徵的最大值和最小值之間隨機選擇一個值,將樣本中小於該取值的資料劃到左分支,大於等於該取值的劃到右分支。然後,在左右兩個分支資料中,重複上述步驟,直到滿足如下條件:
1.資料不可再分,即:只包含一條資料,或者全部資料相同。
2.二叉樹達到限定的最大深度。
2.2 Isolation Forest example
import pandas as pd
import numpy as np
data = pd.read_csv("C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/Contests/ct_contest/train_11.csv",engine="python")
data = data.iloc[:,1:132]
from sklearn.model_selection import train_test_split
va_X = data.drop(['Y1'], axis=1)
va_y = data["Y1"]# IsolationForest
data1 = data.dropna(axis=1,how='any')# del NAs
va_X = data1.drop(['Y1'], axis=1)
va_y = data1["Y1"]
from sklearn.ensemble import IsolationForest
clf = IsolationForest()
clf.fit(va_X)
y_pred_train = pd.DataFrame(clf.predict(va_X))
ary = np.array(va_y)
for i in range(100000):
if ary[i] > 0:
ary[i] = -1
else:
ary[i] = 1
s1 = pd.concat([pd.DataFrame(ary),y_pred_train],axis=1)#AUC counting
from sklearn import metrics
test_auc = metrics.roc_auc_score(ary,y_pred_train)
print (test_auc)0.5465412370819451