 I participated in the 2019 Donghae University Big Data Competition. In this article, I will show waht kind of the problem we should do and how I finish the work.
I participated in the 2019 Donghae University Big Data Competition. In this article, I will show waht kind of the problem we should do and how I finish the work.
※There is contest Description:
1.訓練數據(用於建立模型) 此數據為建模用,數據為熱壓爐成化加工過程所量測的溫度數據,總共有 8 個 群組的數據。群組內的每一個檔案為同一機台在一段連續時間內所量測數據, 8 個群組共有紀錄 230 個量測數據檔案,每一個檔案包含有五個到八個溫度數據欄位。
2.測驗數據(用於產生測驗結果): 測驗數據共有 36 組,皆由量測訓練數據機台所產生,數據格式與訓練數據相 同。測驗數據分類準確度為比賽結果依據。
3.比賽方式: 經由比賽團隊所訓練出來的模型,將測驗數據當作輸入數據,進行分類。主辦 方將各團隊的 36 組測驗數據分類結果經過分類準確度計算,進行團隊排名, 做為入圍決賽之依據。
資料型態為8個資料夾,分別代表8個不同分類,資料夾內有數個機台溫度的txt檔案,其呈現方式為垂直觀測資料,故我們先以R讀入大量txt資料,再將垂直格式轉為水平格式,並且幫各比溫度資料標記其所屬的分類,以1~8的factor為代稱,以方便我們做後續分析。
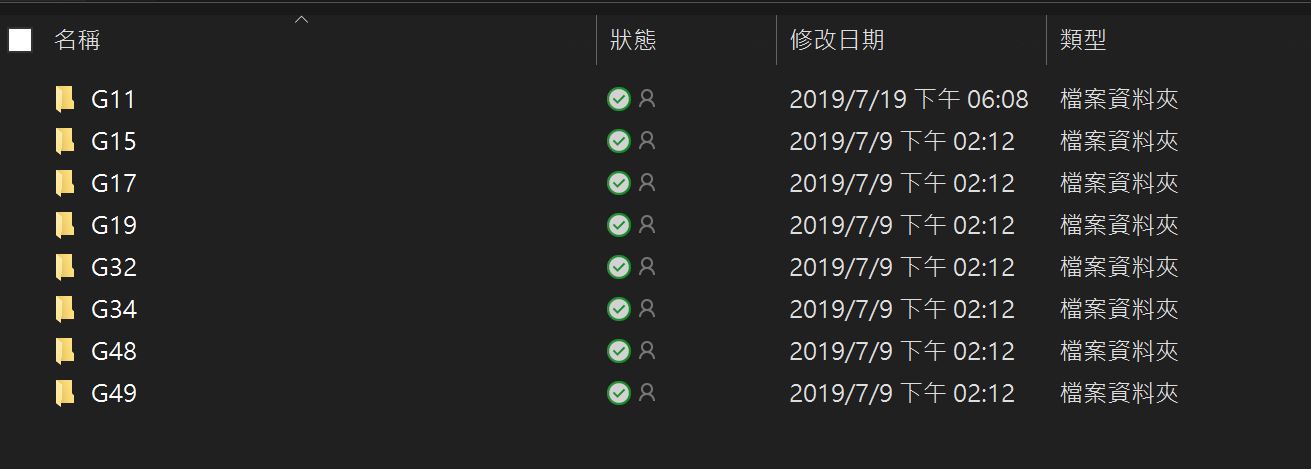 ※訓練資料圖示1:八個類別。
※訓練資料圖示1:八個類別。
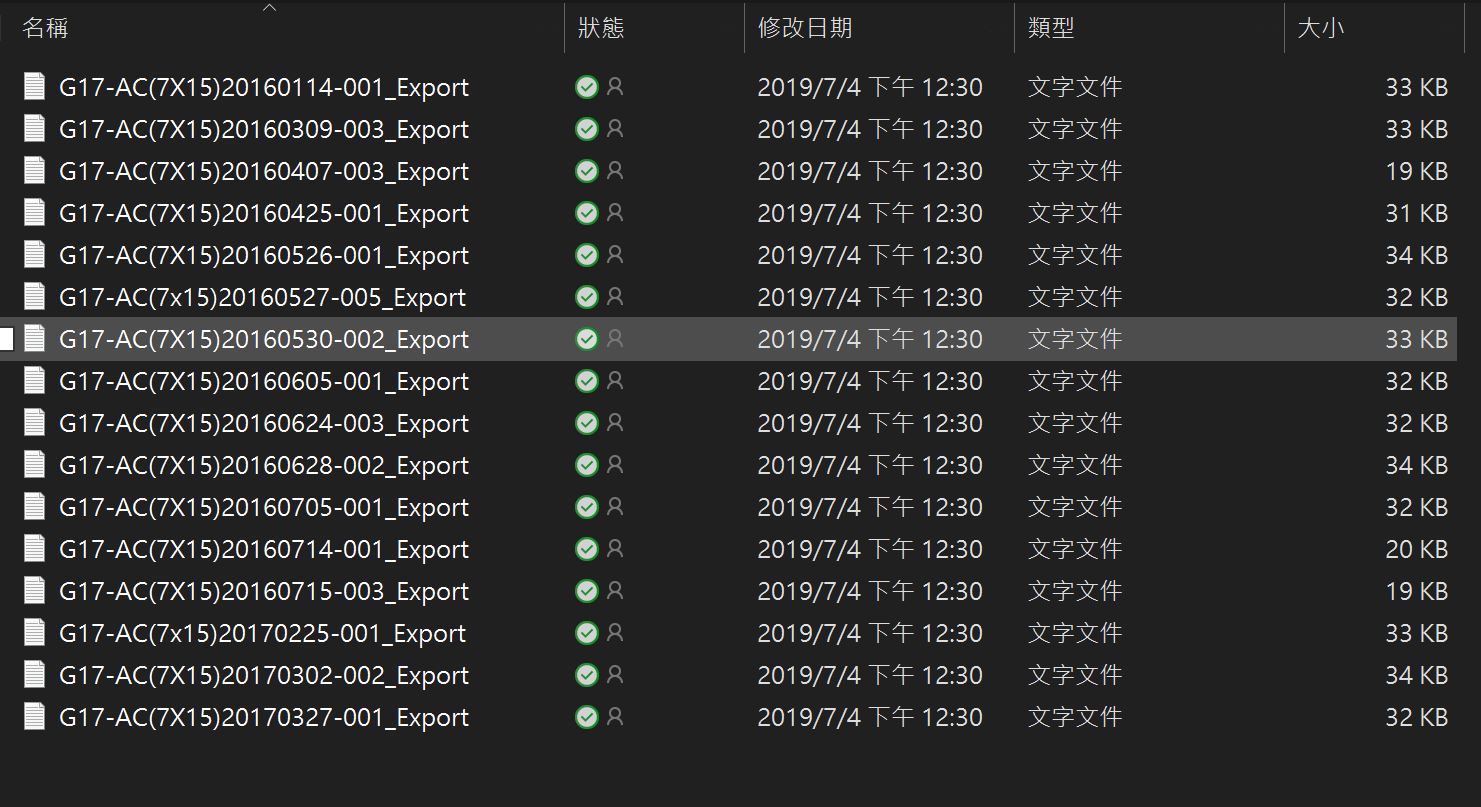 ※訓練資料圖示2:類別內各自以.txt呈現。
※訓練資料圖示2:類別內各自以.txt呈現。
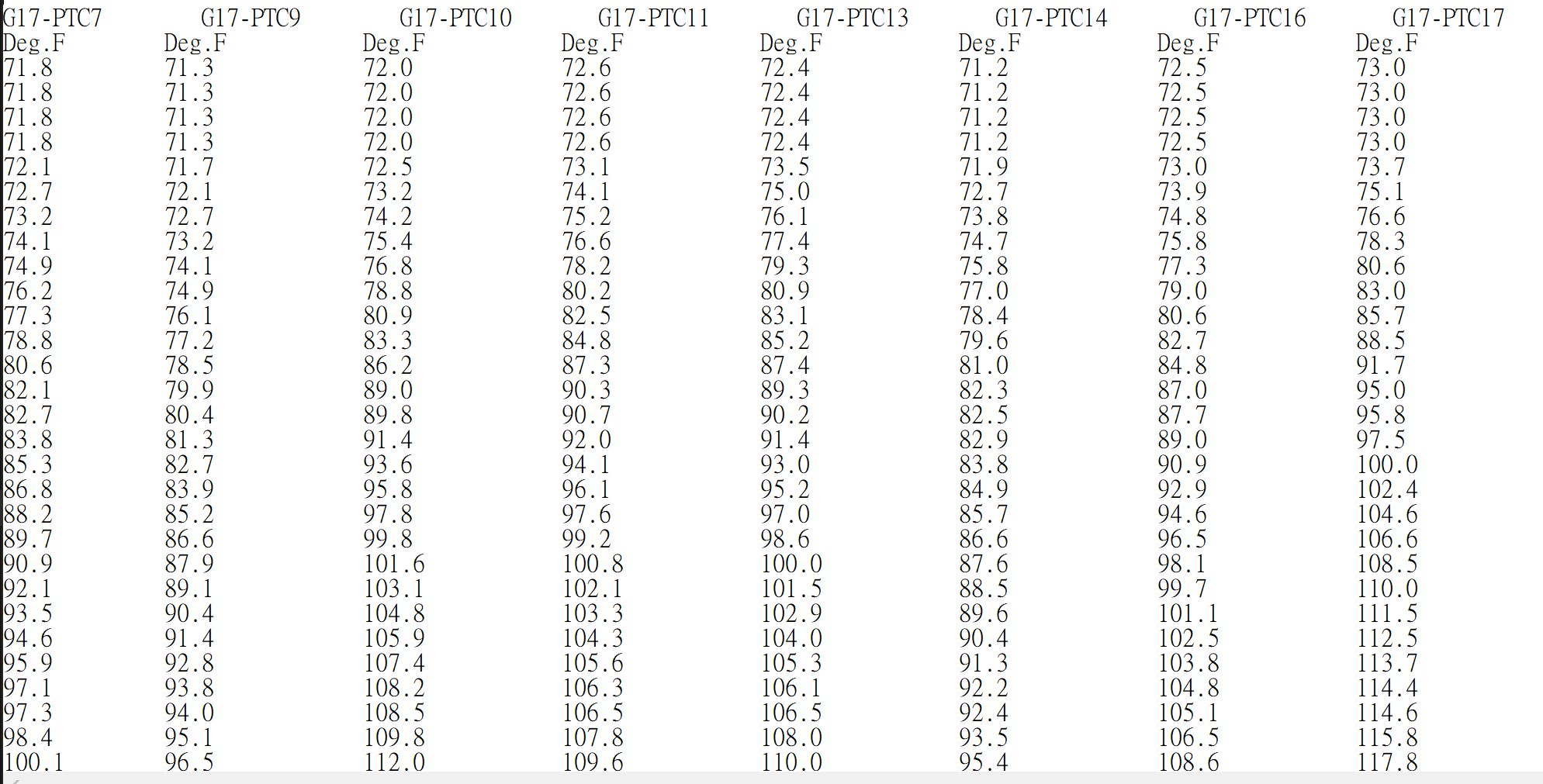
thu3
※訓練資料圖示3 :溫度以縱向的方式呈現。
Read data
說明:以下程式在資料目錄及其底下的txt檔架構不變下,只需要更改資料夾位置即可
例如:假設訓練資料「大數據競賽初賽資料(230測試數據)」位於D槽目錄下,
將path改成 path <- “D:/大數據競賽初賽資料(230測試數據)/”即可
path <- "C:\\Users\\User\\OneDrive\\Lin\\NSYSU\\thu_bigdata\\thubigdata2019training-230\\"同理,更改測試資料夾位置即可 例如:假設測試資料夾「thubigdata2019exam-722」位於C槽的user, 將pathtest改成“C:/user/thubigdata2019exam-722/”即可
pathtest <- "C:\\Users\\User\\OneDrive\\Lin\\NSYSU\\thu_bigdata\\test_model\\"注意: 1.須將位置中的斜線「」改成反斜線「/」,或是改成「\」也可以。 2.資料夾位置最後記得加上反斜線「/」。
Part2:Install packages
準備後續幾個會使用到的package:
necessary = c("readr","dplyr","plyr","randomForest")
installed = necessary %in% installed.packages()[, 'Package']
if (length(necessary[!installed]) >=1)
install.packages(necessary[!installed])
library(readr)
library(plyr)
library(randomForest)## randomForest 4.6-14## Type rfNews() to see new features/changes/bug fixes.Part3:Data processing
Train data
txt= function(txt){
read_delim(txt,delim = "\t",col_names = TRUE)[-1,]
}
site = c("G11","G15","G17","G19","G32","G34","G48","G49")
for(i in 1:length(site)){
g11data = lapply(paste0(path = paste0(path,site[i],"/"),list.files(path = paste0(path,site[i],"/"), pattern = "*.txt"),sep=""),txt)
#G11
if(site[i]=="G11"){
for(k in 1:length(g11data)){
g11data[[k]] = apply(g11data[[k]],2,as.numeric)
for(j in 1 : length(colnames(g11data[[i]]))){
num = nchar(colnames(g11data[[i]])[j])
colnames(g11data[[i]])[j] = substr(colnames(g11data[[i]])[j],5,num-2)
}
}
data = rbind.fill(as.data.frame(t(g11data[[1]][,-dim(g11data[[1]])[2]])))
for(l in c (2:23)){
data <- rbind.fill(data,as.data.frame(t(g11data[[l]][,-dim(g11data[[l]])[2]])))
}
data[is.na(data)] <- 0
}
#G15
else if(site[i]=="G15"){
g15data = lapply(paste0(path = paste0(path,site[i],"/"),list.files(path = paste0(path,site[i],"/"), pattern = "*.txt"),sep=""),txt)
for(k in 1:length(g15data)){
g15data[[k]] = apply(g15data[[k]],2,as.numeric)
for(j in 1 : length(colnames(g15data[[i]]))){
num = nchar(colnames(g15data[[i]])[j])
colnames(g15data[[i]])[j] = substr(colnames(g15data[[i]])[j],5,num-2)
}
}
for(l in c (1:31)){
data <- rbind.fill(data,as.data.frame(t(g15data[[l]][,-dim(g15data[[l]])[2]])))
}
data[is.na(data)] <- 0
}
#G17
else if(site[i]=="G17"){
g17data = lapply(paste0(path = paste0(path,site[i],"/"),list.files(path = paste0(path,site[i],"/"), pattern = "*.txt"),sep=""),txt)
for(k in 1:length(g17data)){
g17data[[k]] = apply(g17data[[k]],2,as.numeric)
for(j in 1 : length(colnames(g17data[[i]]))){
num = nchar(colnames(g17data[[i]])[j])
colnames(g17data[[i]])[j] = substr(colnames(g17data[[i]])[j],5,num-2)
}
}
for(l in c (1:16)){
data <- rbind.fill(data,as.data.frame(t(g17data[[l]][,-dim(g17data[[l]])[2]])))
}
data[is.na(data)] <- 0
}
#G19
else if(site[i] == "G19"){
g19data = lapply(paste0(path = paste0(path,site[i],"/"),list.files(path = paste0(path,site[i],"/"), pattern = "*.txt"),sep=""),txt)
for(k in 1:length(g19data)){
g19data[[k]] = apply(g19data[[k]],2,as.numeric)
for(j in 1 : length(colnames(g19data[[i]]))){
num = nchar(colnames(g19data[[i]])[j])
colnames(g19data[[i]])[j] = substr(colnames(g19data[[i]])[j],5,num-2)
}
}
for(l in c (1:30)){
data <- rbind.fill(data,as.data.frame(t(g19data[[l]][,-dim(g19data[[l]])[2]])))
}
data[is.na(data)] <- 0
}
#G32
else if(site[i] == "G32"){
g32data = lapply(paste0(path = paste0(path,site[i],"/"),list.files(path = paste0(path,site[i],"/"), pattern = "*.txt"),sep=""),txt)
for(k in 1:length(g32data)){
g32data[[k]] = apply(g32data[[k]],2,as.numeric)
for(j in 1 : length(colnames(g32data[[i]]))){
num = nchar(colnames(g32data[[i]])[j])
colnames(g32data[[i]])[j] = substr(colnames(g32data[[i]])[j],5,num-2)
}
}
for(l in c (1:32)){
data <- rbind.fill(data,as.data.frame(t(g32data[[l]][,-dim(g32data[[l]])[2]])))
}
data[is.na(data)] <- 0
}
#G34
else if(site[i] == "G34"){
g34data = lapply(paste0(path = paste0(path,site[i],"/"),list.files(path = paste0(path,site[i],"/"), pattern = "*.txt"),sep=""),txt)
for(k in 1:length(g34data)){
g34data[[k]] = apply(g34data[[k]],2,as.numeric)
for(j in 1 : length(colnames(g34data[[i]]))){
num = nchar(colnames(g34data[[i]])[j])
colnames(g34data[[i]])[j] = substr(colnames(g34data[[i]])[j],5,num-2)
}
}
for(l in c (1:33)){
data <- rbind.fill(data,as.data.frame(t(g34data[[l]][,-dim(g34data[[l]])[2]])))
}
data[is.na(data)] <- 0
}
#G48
else if(site[i]=="G48"){
g48data = lapply(paste0(path = paste0(path,site[i],"/"),list.files(path = paste0(path,site[i],"/"), pattern = "*.txt"),sep=""),txt)
for(k in 1:length(g48data)){
g48data[[k]] = apply(g48data[[k]],2,as.numeric)
for(j in 1 : length(colnames(g48data[[i]]))){
num = nchar(colnames(g48data[[i]])[j])
colnames(g48data[[i]])[j] = substr(colnames(g48data[[i]])[j],5,num-2)
}
}
for(l in c (1:31)){
data <- rbind.fill(data,as.data.frame(t(g48data[[l]][,-dim(g48data[[l]])[2]])))
}
data[is.na(data)] <- 0
}
#G49
else{
g49data = lapply(paste0(path = paste0(path,site[i],"/"),list.files(path = paste0(path,site[i],"/"), pattern = "*.txt"),sep=""),txt)
for(k in 1:length(g49data)){
g49data[[k]] = apply(g49data[[k]],2,as.numeric)
for(j in 1 : length(colnames(g49data[[i]]))){
num = nchar(colnames(g49data[[i]])[j])
colnames(g49data[[i]])[j] = substr(colnames(g49data[[i]])[j],5,num-2)
}
}
for(l in c (1:34)){
data <- rbind.fill(data,as.data.frame(t(g49data[[l]][,-dim(g49data[[l]])[2]])))
}
data[is.na(data)] <- 0
}
}
a = rep(1,145)
b = rep(2,207)
c = rep(3,119)
d = rep(4,238)
e = rep(5,256)
f = rep(6,264)
g = rep(7,244)
h = rep(8,272)
data$y = c(a,b,c,d,e,f,g,h)Test data
測試資料與訓練資料呈現類似,以36個txt檔案呈現,並期望我們能預測36筆資料分別為哪些類別。
 ※測試資料圖示1
※測試資料圖示1
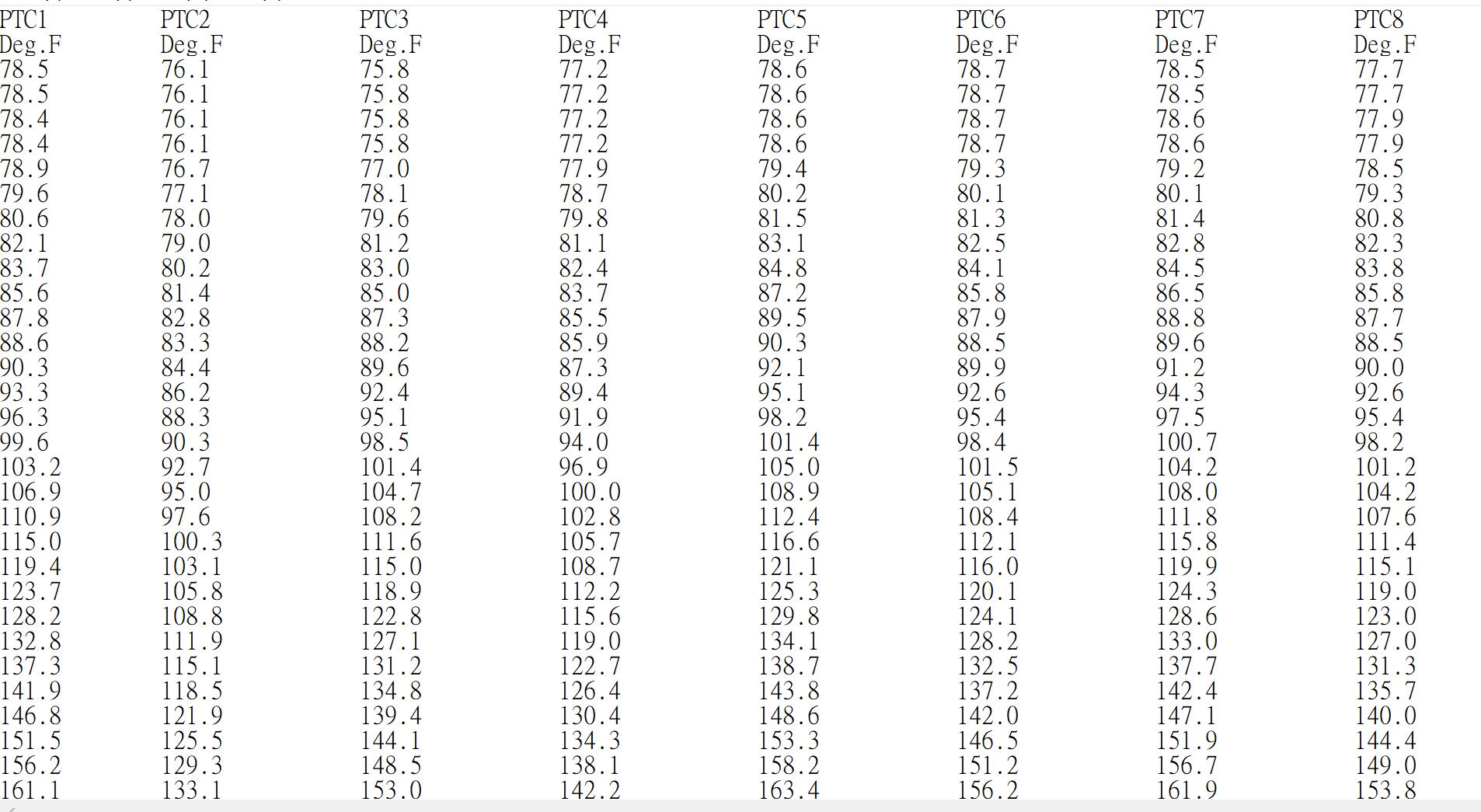 ※測試資料圖示2
※測試資料圖示2
g49 <- list.files(path = pathtest, pattern = "*.txt")
g49data = lapply(paste0(path = pathtest,g49,sep=""),txt)
for(i in 1:length(g49data)){
g49data[[i]] = apply(g49data[[i]],2,as.numeric)
for(j in 1 : length(colnames(g49data[[i]]))){
num = nchar(colnames(g49data[[i]])[j])
colnames(g49data[[i]])[j] = substr(colnames(g49data[[i]])[j],5,num-2)
}
}
data1 = rbind.fill(as.data.frame(t(g49data[[1]])))
for(i in c (2:36)){
data1 <- rbind.fill(data1,as.data.frame(t(g49data[[i]])))
}
data1[is.na(data1)] <- 0
data1 <- data1[-which(data1$V1== 0),]
test = c(rep(1,5),rep(10,8),rep(11,8),rep(12,8),rep(13,8),rep(14,8),rep(15,8),rep(16,8),rep(17,8),rep(18,8),rep(19,8),rep(2,5),rep(20,8),rep(21,8),rep(22,8),rep(23,8),rep(24,8),rep(25,8),rep(26,8),rep(27,8),rep(28,8),rep(29,8),rep(3,8),rep(30,8),rep(31,8),rep(32,8),rep(33,8),rep(34,8),rep(35,8),rep(36,8),rep(4,6),rep(5,6),rep(6,8),rep(7,6),rep(8,8),rep(9,8))
data1$test <- test
test = data1Part4:Data analyzing
我們先透過資料視覺化,並以此決定後續分析方向,因不知不同PTC是否有影響,因此我們決定先保留PTC,並找尋個機台的溫度特徵來當作其他的解釋變數。 ## Data Visualization 這是第一個類別的第一機台溫度時間變化圖,大多數的觀測溫度變化圖呈現類似的結果。我們在最開始以升溫速率當作分類特徵,但效果並不顯著。
temprature = as.numeric(data1[1,])
plot(temprature,xlab = "time", xlim = c(0,225),col="blue")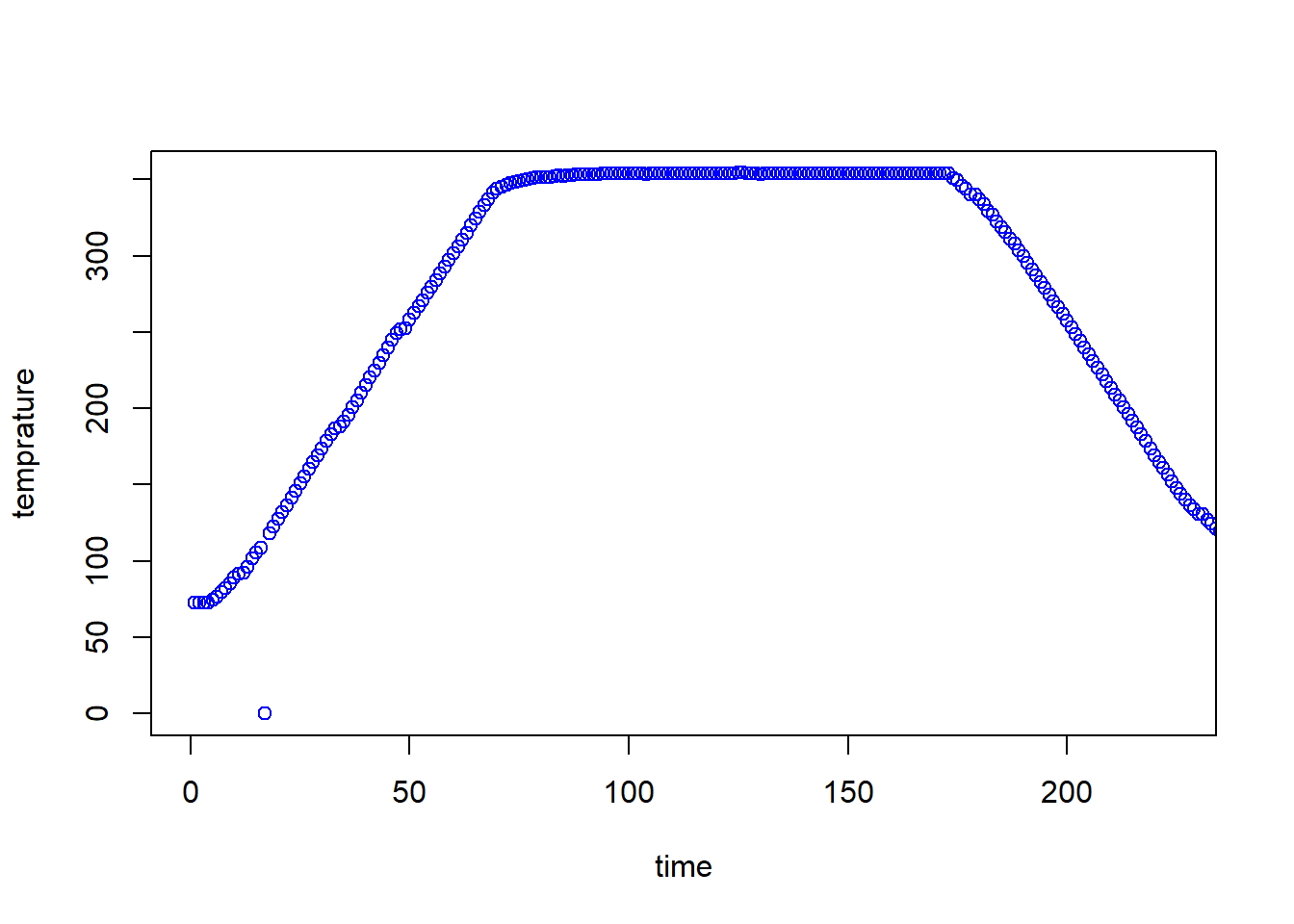
我們已知機台為持續加溫,因此其溫度變化的特徵是一個可作為類別區分的依據,因此我們在最一開始分析時,使用各串溫度資料的某些特徵進行分析,例如最大溫度、穩態溫度時間長度、溫度下降點等。但在訓練過程中,我們嘗試了多種分類方法,如常見的SVM、XGB、隨機森林等,但因各PTC差異甚小,且保留過少的溫度特徵,因此效果並不理想。後續使用集成學習(stacking)的方法,但交叉驗證的預測準確率也僅約70%左右。
 ※分析流程1
※分析流程1
後來透過分析方法推得相異PTC並無顯著影響分類結果,因此使用不考慮PTC差異的全溫度資料進行分類,在使用各類多元分類方法以及集成方法後,訓練資料的交叉驗證準確率皆高達99%,因此在最後我們決定使用不易過度擬合的分類方法:隨機森林,來當作我們這次的最終分類模型。
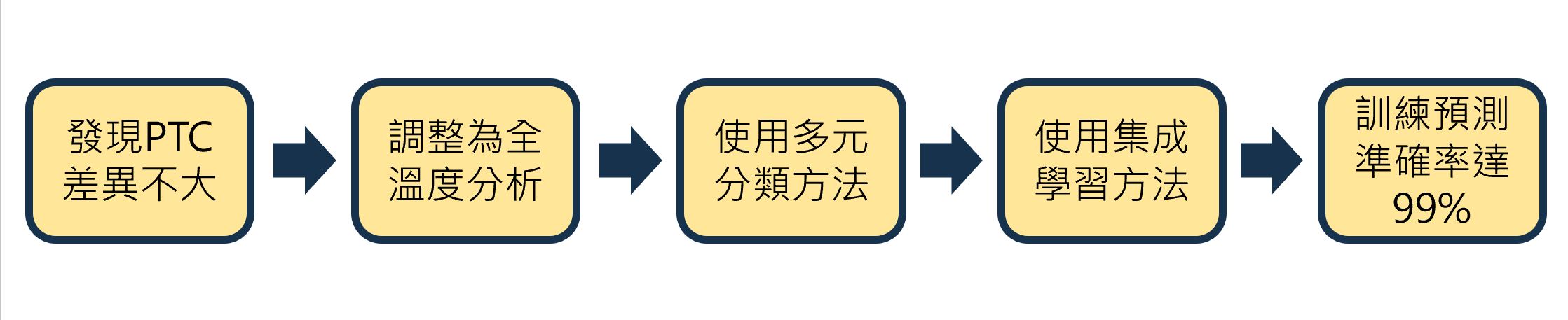 ※分析流程2
※分析流程2
RandomForest
以下是我們對最終36機台的分類預測,模型為RandomForest
zero = matrix(rep(0,42*276),ncol = 42)
test = cbind(test,zero)
colnames(test) = c(paste0("V",1:449))
data$y = as.factor(data$y)
machine = data$y
label = as.integer(data$y)-1
data$y = NULL
model = randomForest(as.factor(label)~.,data= data,boos = TRUE)
predran = predict(model,test)
predran = as.numeric(data.frame(predran)[,1])
for(i in 1:length(g49data)){
g49data[[i]] = apply(g49data[[i]],2,as.numeric)
for(j in 1 : length(colnames(g49data[[i]]))){
colnames(g49data[[i]])[j] = paste0("PTC",j)
}
if(table(is.na(g49data[[i]]))[[1]] != ncol(g49data[[i]])*nrow(g49data[[i]])){
g49data[[i]] = g49data[[i]][,-ncol(g49data[[i]])]
}
}
len = c()
len = vector()
for(i in 1:36){
len[i] = length(colnames(g49data[[i]]))
}
predran[which(predran == "1")] = "G11"
predran[which(predran == "2")] = "G15"
predran[which(predran == "3")] = "G17"
predran[which(predran == "4")] = "G19"
predran[which(predran == "5")] = "G32"
predran[which(predran == "6")] = "G34"
predran[which(predran == "7")] = "G48"
predran[which(predran == "8")] = "G49"
j = 0
l = 1
k = c(1,10:19,2,20:29,3,30:36,4:9)
for(i in len){
j = i+j
print(paste0("第",k[l],"筆測試資料是屬於",predran[j],"機台"))
l = l+1
}## [1] "第1筆測試資料是屬於G11機台"
## [1] "第10筆測試資料是屬於G17機台"
## [1] "第11筆測試資料是屬於G19機台"
## [1] "第12筆測試資料是屬於G19機台"
## [1] "第13筆測試資料是屬於G32機台"
## [1] "第14筆測試資料是屬於G32機台"
## [1] "第15筆測試資料是屬於G32機台"
## [1] "第16筆測試資料是屬於G32機台"
## [1] "第17筆測試資料是屬於G32機台"
## [1] "第18筆測試資料是屬於G32機台"
## [1] "第19筆測試資料是屬於G34機台"
## [1] "第2筆測試資料是屬於G11機台"
## [1] "第20筆測試資料是屬於G34機台"
## [1] "第21筆測試資料是屬於G34機台"
## [1] "第22筆測試資料是屬於G34機台"
## [1] "第23筆測試資料是屬於G34機台"
## [1] "第24筆測試資料是屬於G34機台"
## [1] "第25筆測試資料是屬於G48機台"
## [1] "第26筆測試資料是屬於G48機台"
## [1] "第27筆測試資料是屬於G48機台"
## [1] "第28筆測試資料是屬於G48機台"
## [1] "第29筆測試資料是屬於G48機台"
## [1] "第3筆測試資料是屬於G15機台"
## [1] "第30筆測試資料是屬於G48機台"
## [1] "第31筆測試資料是屬於G49機台"
## [1] "第32筆測試資料是屬於G49機台"
## [1] "第33筆測試資料是屬於G49機台"
## [1] "第34筆測試資料是屬於G49機台"
## [1] "第35筆測試資料是屬於G49機台"
## [1] "第36筆測試資料是屬於G49機台"
## [1] "第4筆測試資料是屬於G15機台"
## [1] "第5筆測試資料是屬於G15機台"
## [1] "第6筆測試資料是屬於G15機台"
## [1] "第7筆測試資料是屬於G15機台"
## [1] "第8筆測試資料是屬於G15機台"
## [1] "第9筆測試資料是屬於G17機台"