𝔏ℑ𝔑'𝔖 𝔅𝔏𝔒𝔊
machine-learning
2020-08-28
3 / 4
deep-learning
Practice in GAN with One Class Learning
Hermit
/
2019-11-14
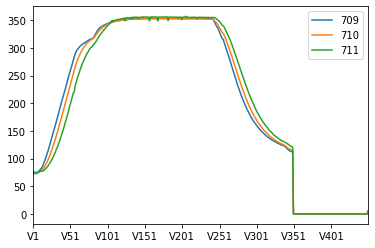
這次我將使用先前東海大學大數據競賽的初賽資料,也就是熱成化加工的數據資料,而該資料中一共有8類,我將資料的第5與8類挑選出來,並僅取3筆第5類資料與136筆第8類資料作為訓練資料,而驗證資料則為9筆第5類資料與136筆第8類資料作為測試資料,因此我們的目標是使用生成對抗網路來生成第5類資料以達到資料平衡後進行後續的分類分析。 […] import pandas as pd import numpy as np df = pd.read_csv('C:/Users/User/OneDrive -…
machine-learning
One Class Learning
Hermit
/
2019-10-02
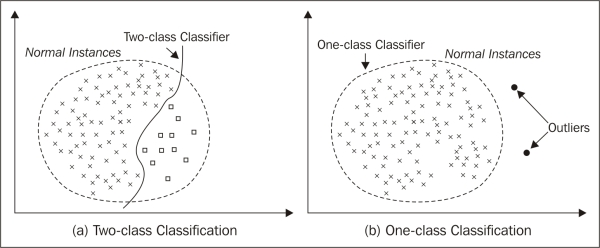
在資料探勘中,異常檢測:anomaly detection對不符合預期模式或資料集中其他專案的專案、事件或觀測值的辨識。 通常異常專案會轉變成銀行欺詐、結構缺陷、醫療問題、文字錯誤等類型的問題。異常也被稱為離群值、新奇、噪聲、偏差和例外。 特別是在檢測濫用與網路入侵時,有趣性物件往往不是罕見物件,但卻是超出預料的突發活動。這種模式不遵循通常統計定義中把異常點看作是罕見物件,於是許多異常檢測方法(特別是無監督的方法)將對此類資料失效,除非進行了合適的聚集。相反,群集分析演算法可能可以檢測出這些模式形成的微群集。 有三大類異常檢測方法。在假設資料集中大多數實體都是正常的前提下,無監督異常檢測方法能…
machine-learning
Imbalanced Data Binary Classification
Hermit
/
2019-09-25
不平衡資料 (Imbalanced Data)是很常見於結構化資料的情境之一。比如說我們有一筆保險客戶的資料,有非常多的客戶基本資料(如:居住地、學歷等等),以及一個對應的反應變數:是否有投保,而這個變量有極大的可能多數為非投保狀態,這種情況就稱為Imbalanced Data,因為最近遇到這個類型的資料分析問題,因此從數篇文章中整理幾個常見的解決方法,這裡主要針對反應變數為binary classificaion的狀態。 […] 因為極度不平衡的資料,將導致我們在訓練分類模型的時候 有過度去預測某一類的情況。比如說上述的保險資料,我們持有10萬筆客戶訓練資料,但僅有2000筆資…
deep-learning
What is deep learning
Hermit
/
2019-08-20
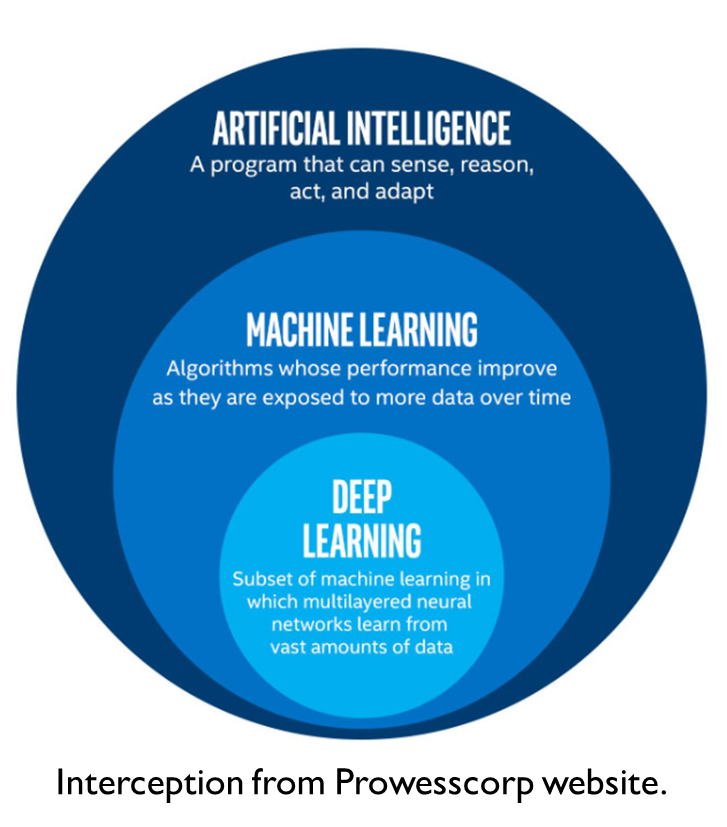
最近拜讀Keras之父-Francois Chollet所撰寫的deep learning with python。 因此想撰寫一些讀後心得筆記,以留日後自己參考。 […] 很常遇到有人在討論深度學習與機器學習的差異,以及“深度”是深在哪裡。 因此有撰寫這篇文章的想法,順便讓自己更清楚的知道這些名詞的差異。 在談論何謂深度學習之前,我們要先知道人工智慧以及機器學習、深度學習的關係。 應該許多人看過以下這張圖: 因此不免俗的,先簡介這三者,再深入探討我們所要談論的“深度”學習。 […] 人工智慧大約於1950年代,當時電腦科學領域內所電腦是否能用來“思考”,在最開始的…
Python
MLB playoff prediction with SVM & Randomforest
Hermit
/
2019-08-19
In the same theme,MLB. I will show how to use Python to train a randomforest and SVM classifier. Our target is predicting whether the team will enter the next year playoff or not. Since the playoff qualification depends on the same year’s season game win rate. If we predict the same year…
R
2019 THU Big Data Preliminary
Hermit
/
2019-08-11
I participated in the 2019 Donghae University Big Data Competition. In this article, I will show waht kind of the problem we should do and how I finish the work. ※There is contest Description: 1.訓練數據(用於建立模型) 此數據為建模用,數據為熱壓爐成化加工過程所量測的溫度數據,總共有 8 個 群組的數據。群組內的每一個檔案為同一機台在一段連續時間內所量測數據, 8 個群組共有紀錄 230 個量測數據檔…
««
«
1
2
3
4
»
»»