𝔏ℑ𝔑'𝔖 𝔅𝔏𝔒𝔊
small talk
2020-08-28
2 / 2
deep-learning
Generative Adversarial Network Practice
Hermit
/
2019-10-23
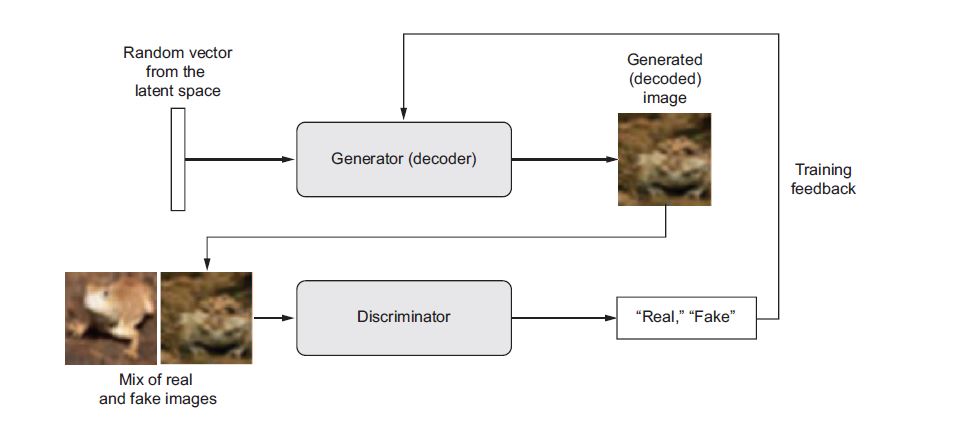
由Goodfellow等人在2014年推出的生成對抗神經網路適用於學習圖像空間VAE的替代方法。藉由強制讓聲稱ˊ圖像與真實圖片在統計上幾乎無法分別的條件下,生成相當逼真的合成圖像。 若要以直覺的方式來理解GAN,可以想像一個偽造者試圖創造衣服偽造的畢卡索畫作。起先,偽造者的偽造作品非常糟糕。然後他將依些假貨與真正的畫作混合在一起,並給鑑定師鑑定。鑑定師對每幅畫進行真實性評估,並給予位作者意見回饋。接著偽造者根據意見回饋再準備一些新的假貨,隨時間的推移偽造者跟鑑定師也越來越專業,到最後便能產出一個專業偽造者與鑑定師。 這就是GAN的運作原理:為偽造神經網路以及專家神經網路。因此由兩部分組成:…
deep-learning
Dropout
Hermit
/
2019-10-16
Drop 是由Geoff Hinton與多倫多大學的學生所開發的神經網路常規化技術之一。神經網路層的丟棄法,主要是在訓練期間隨機丟棄layer的一些輸出特徵。假設某個輸出向量為[0.2,0.5,1.3,0.8,1.1]的向量,在使用丟棄法後將隨機幾個向量的特徵歸零:[0.2,0,1.3,0,1.1],而控制丟失多少值一般是採用丟失率來計算,大約0.2~0.5的一個數值。而在test階段不會丟棄任何值,而是按照丟棄率去比例縮小,以平衡被歸零的影響。 實務上,我們可以在訓練時執行dropout然後把輸出值同比例放大,這樣做就不用再測試做任何變動了。 這個看似隨興的方法為何可以有效降…
machine-learning
Imbalanced Data Binary Classification
Hermit
/
2019-09-25
不平衡資料 (Imbalanced Data)是很常見於結構化資料的情境之一。比如說我們有一筆保險客戶的資料,有非常多的客戶基本資料(如:居住地、學歷等等),以及一個對應的反應變數:是否有投保,而這個變量有極大的可能多數為非投保狀態,這種情況就稱為Imbalanced Data,因為最近遇到這個類型的資料分析問題,因此從數篇文章中整理幾個常見的解決方法,這裡主要針對反應變數為binary classificaion的狀態。 […] 因為極度不平衡的資料,將導致我們在訓練分類模型的時候 有過度去預測某一類的情況。比如說上述的保險資料,我們持有10萬筆客戶訓練資料,但僅有2000筆資…
Python
How to compose a python(or R) script on linux commander.
Hermit
/
2019-08-27
In this article I will show how to bulid a script file on your location. And how to compose the script on Python (or R). You should bulid the Python script on your virtual environment if you want to use the keras CUDA. You should enter your server at begining. […] You can key “dir” to check…
deep-learning
What is deep learning
Hermit
/
2019-08-20
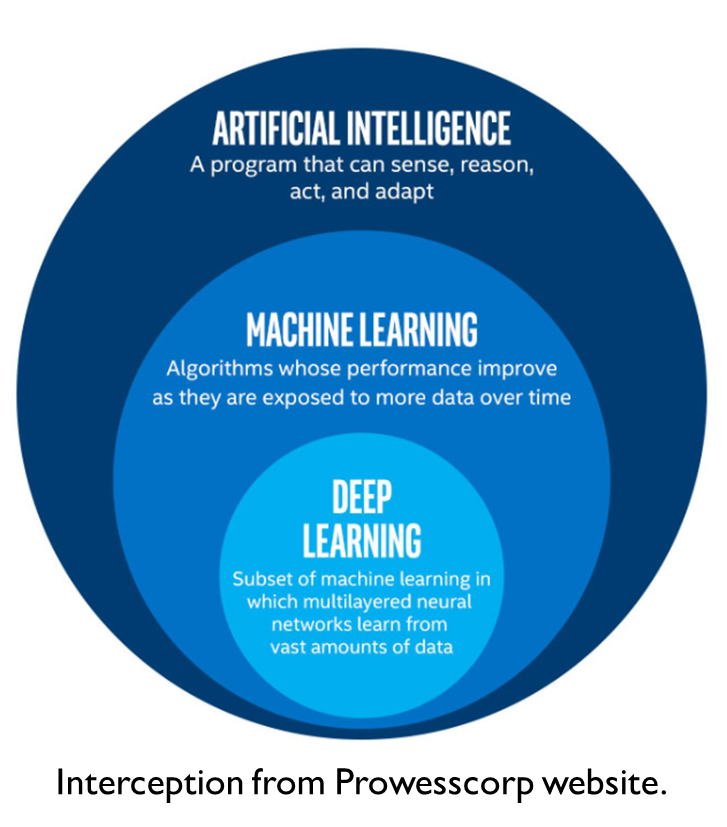
最近拜讀Keras之父-Francois Chollet所撰寫的deep learning with python。 因此想撰寫一些讀後心得筆記,以留日後自己參考。 […] 很常遇到有人在討論深度學習與機器學習的差異,以及“深度”是深在哪裡。 因此有撰寫這篇文章的想法,順便讓自己更清楚的知道這些名詞的差異。 在談論何謂深度學習之前,我們要先知道人工智慧以及機器學習、深度學習的關係。 應該許多人看過以下這張圖: 因此不免俗的,先簡介這三者,再深入探討我們所要談論的“深度”學習。 […] 人工智慧大約於1950年代,當時電腦科學領域內所電腦是否能用來“思考”,在最開始的…
machine-learning
Data Analysis Run-Down
Hermit
/
2019-06-23
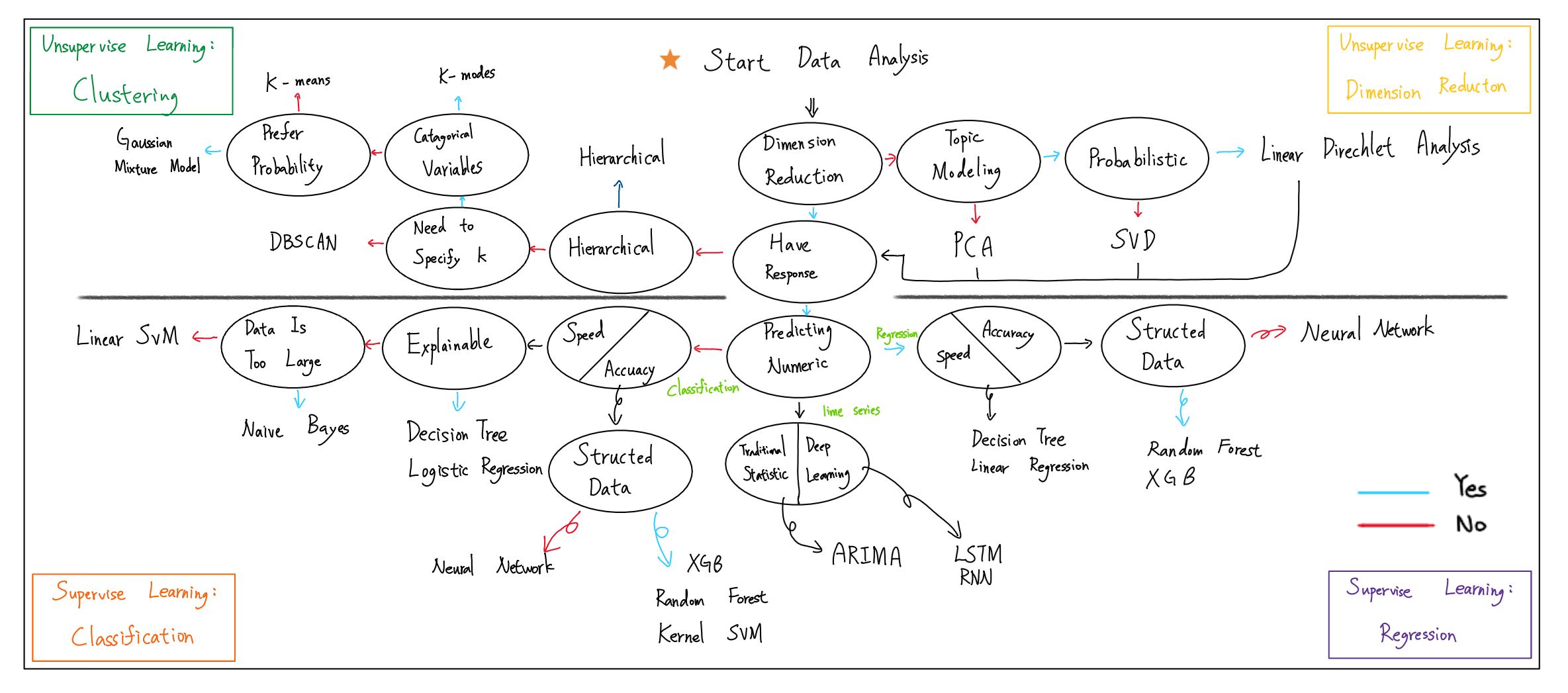
日前看到一份有關資料分析流程以及方法的圖片,但因未提及結構化資料以及時間序列等,因此我將它們增加到表上,以此來釐清各分析方法的順序。 (此表不一定正確,僅供參考)
««
«
1
2
»
»»