Intro: GML
這次來測試自動化機器學習套件:Ghalat Machine Learning,
主要針對回歸問題與分類問題的自動化學習。
目前套件具有以下功能:
1.自動特徵工程
2.自動選擇機器學習和神經網路模型
3.自動超參數調校
4.排序模型效果(根據交叉驗證分數)
5.推薦最佳模型
我將使用UCI breast cancer dataset(sklearn dataset)來測試此套件for分類的效果以及使用情況。
套件作者Github:https://github.com/Muhammad4hmed/Ghalat-Machine-Learning
Pypl套件說明: https://s0pypi0org.icopy.site/project/GML/2.0.2/
Colab Setting
!pip install -U -q PyDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
import pandas as pd
# Authenticate and create the PyDrive client.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
Import and Install Modules
# install some modules
!pip install GML
!pip install category_encoders
Collecting GML
Downloading https://files.pythonhosted.org/packages/b0/91/3580e3e1f4151fed64cf37840bae994ea7d1409a58a527b8fd010c31c909/GML-2.0.4-py3-none-any.whl
Collecting catboost
[?25l Downloading https://files.pythonhosted.org/packages/90/86/c3dcb600b4f9e7584ed90ea9d30a717fb5c0111574675f442c3e7bc19535/catboost-0.24.1-cp36-none-manylinux1_x86_64.whl (66.1MB)
[K |████████████████████████████████| 66.1MB 56kB/s
[?25hRequirement already satisfied: lightgbm in /usr/local/lib/python3.6/dist-packages (from GML) (2.2.3)
Requirement already satisfied: xgboost in /usr/local/lib/python3.6/dist-packages (from GML) (0.90)
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.6/dist-packages (from GML) (0.22.2.post1)
Collecting autofeat
Downloading https://files.pythonhosted.org/packages/3a/63/c5aa2e38f50c9dedb1cf1bf6e0b5ab520e2c8747627ca7318a827b618d10/autofeat-1.1.3-py3-none-any.whl
Requirement already satisfied: Keras in /usr/local/lib/python3.6/dist-packages (from GML) (2.4.3)
Requirement already satisfied: plotly in /usr/local/lib/python3.6/dist-packages (from catboost->GML) (4.4.1)
Requirement already satisfied: pandas>=0.24.0 in /usr/local/lib/python3.6/dist-packages (from catboost->GML) (1.0.5)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from catboost->GML) (1.15.0)
Requirement already satisfied: graphviz in /usr/local/lib/python3.6/dist-packages (from catboost->GML) (0.10.1)
Requirement already satisfied: numpy>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from catboost->GML) (1.18.5)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from catboost->GML) (3.2.2)
Requirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from catboost->GML) (1.4.1)
Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn->GML) (0.16.0)
Requirement already satisfied: sympy in /usr/local/lib/python3.6/dist-packages (from autofeat->GML) (1.1.1)
Requirement already satisfied: future in /usr/local/lib/python3.6/dist-packages (from autofeat->GML) (0.16.0)
Collecting pint
[?25l Downloading https://files.pythonhosted.org/packages/7f/72/4ea7d219a2d6624fd22c3d8fd5eea183af4f5ece03e3a4726c1c864bb213/Pint-0.15-py2.py3-none-any.whl (200kB)
[K |████████████████████████████████| 204kB 41.6MB/s
[?25hRequirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from Keras->GML) (2.10.0)
Requirement already satisfied: pyyaml in /usr/local/lib/python3.6/dist-packages (from Keras->GML) (3.13)
Requirement already satisfied: retrying>=1.3.3 in /usr/local/lib/python3.6/dist-packages (from plotly->catboost->GML) (1.3.3)
Requirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.24.0->catboost->GML) (2018.9)
Requirement already satisfied: python-dateutil>=2.6.1 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.24.0->catboost->GML) (2.8.1)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->catboost->GML) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->catboost->GML) (0.10.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->catboost->GML) (2.4.7)
Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.6/dist-packages (from sympy->autofeat->GML) (1.1.0)
Requirement already satisfied: packaging in /usr/local/lib/python3.6/dist-packages (from pint->autofeat->GML) (20.4)
Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from pint->autofeat->GML) (49.6.0)
Requirement already satisfied: importlib-metadata; python_version < "3.8" in /usr/local/lib/python3.6/dist-packages (from pint->autofeat->GML) (1.7.0)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.6/dist-packages (from importlib-metadata; python_version < "3.8"->pint->autofeat->GML) (3.1.0)
Installing collected packages: catboost, pint, autofeat, GML
Successfully installed GML-2.0.4 autofeat-1.1.3 catboost-0.24.1 pint-0.15
Collecting category_encoders
[?25l Downloading https://files.pythonhosted.org/packages/44/57/fcef41c248701ee62e8325026b90c432adea35555cbc870aff9cfba23727/category_encoders-2.2.2-py2.py3-none-any.whl (80kB)
[K |████████████████████████████████| 81kB 2.4MB/s
[?25hRequirement already satisfied: pandas>=0.21.1 in /usr/local/lib/python3.6/dist-packages (from category_encoders) (1.0.5)
Requirement already satisfied: numpy>=1.14.0 in /usr/local/lib/python3.6/dist-packages (from category_encoders) (1.18.5)
Requirement already satisfied: scikit-learn>=0.20.0 in /usr/local/lib/python3.6/dist-packages (from category_encoders) (0.22.2.post1)
Requirement already satisfied: patsy>=0.5.1 in /usr/local/lib/python3.6/dist-packages (from category_encoders) (0.5.1)
Requirement already satisfied: statsmodels>=0.9.0 in /usr/local/lib/python3.6/dist-packages (from category_encoders) (0.10.2)
Requirement already satisfied: scipy>=1.0.0 in /usr/local/lib/python3.6/dist-packages (from category_encoders) (1.4.1)
Requirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.21.1->category_encoders) (2018.9)
Requirement already satisfied: python-dateutil>=2.6.1 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.21.1->category_encoders) (2.8.1)
Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn>=0.20.0->category_encoders) (0.16.0)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from patsy>=0.5.1->category_encoders) (1.15.0)
Installing collected packages: category-encoders
Successfully installed category-encoders-2.2.2
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn import datasets
from GML.Ghalat_Machine_Learning import Ghalat_Machine_Learning
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
Data Analysis
Import Data
利用sklearn中的breast cancer資料來試驗看看。 我將資料30%當作訓練資料,測試資料集保留70%。
breast_cancer = datasets.load_breast_cancer()
df_x = pd.DataFrame(breast_cancer.data)
df_y = pd.DataFrame(breast_cancer.target)
df_x.columns = breast_cancer.feature_names
df_y.columns = np.array(['label'])
df = pd.concat([df_x,df_y],axis=1)
X_train, X_test, y_train, y_test = train_test_split(df_x, df_y, test_size=0.7, random_state=777)
print(X_train.shape)
print(X_test.shape)
(170, 30)
(399, 30)
Data Visualization
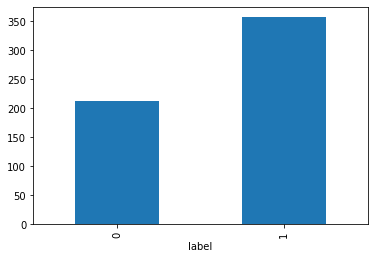
Label 為 0 的是惡性腫瘤患者,1為良性腫瘤,人數比為: 212位:357位
%matplotlib inline
by_fraud = df_y.groupby('label')
by_fraud.size().plot(kind = 'bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f000c2abb00>
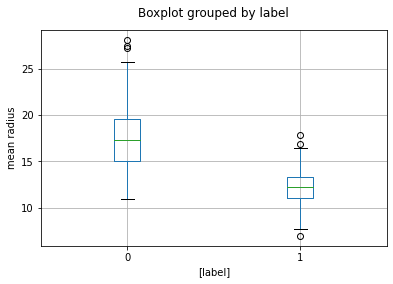
從下圖可看出,惡性腫瘤之平均半徑要比楊性腫瘤來的更大。
fig,axes = plt.subplots()
df.boxplot(column='mean radius',by=['label'],ax=axes)
axes.set_title(' ')
axes.set_ylabel('mean radius')
axes.set_figure
<bound method _AxesBase.set_figure of <matplotlib.axes._subplots.AxesSubplot object at 0x7f000c283128>>
GML:Auto Feature Engineering
自動進行特徵工程,能(簡易的)補缺失值,並新增一些交互作用項當作新的特徵。
gml = Ghalat_Machine_Learning()
# It may cost pretty long time
new_X,y,new_Test_X = gml.Auto_Feature_Engineering(X_train,y_train,type_of_task='Classification',test_data=X_test,splits=6,fill_na_='median',ratio_drop=0.2,generate_features=True,feateng_steps=2)
Welcome to Ghalat Machine Learning!
All models are set to train
Have a tea and leave everything on us ;-)
************************************************************
Successfully dealt with missing data!
X:
mean radius mean texture ... worst symmetry worst fractal dimension
527 12.340 12.27 ... 0.3110 0.07592
43 13.280 20.28 ... 0.3739 0.10270
371 15.190 13.21 ... 0.2487 0.06766
82 25.220 24.91 ... 0.2355 0.10510
534 10.960 17.62 ... 0.2289 0.08278
.. ... ... ... ... ...
506 12.220 20.04 ... 0.2709 0.08839
423 13.660 19.13 ... 0.2744 0.08839
116 8.950 15.76 ... 0.1652 0.07722
71 8.888 14.64 ... 0.2254 0.10840
103 9.876 19.40 ... 0.2622 0.08490
[170 rows x 30 columns]
Test Data:
mean radius mean texture ... worst symmetry worst fractal dimension
416 9.405 21.70 ... 0.2872 0.08304
522 11.260 19.83 ... 0.2557 0.07613
503 23.090 19.83 ... 0.2908 0.07277
111 12.630 20.76 ... 0.2226 0.08486
132 16.160 21.54 ... 0.3480 0.07619
.. ... ... ... ... ...
105 13.110 15.56 ... 0.3147 0.14050
530 11.750 17.56 ... 0.2478 0.07757
507 11.060 17.12 ... 0.2780 0.11680
11 15.780 17.89 ... 0.3792 0.10480
319 12.430 17.00 ... 0.1901 0.05932
[399 rows x 30 columns]
************************************************************
************************************************************
Successfully encoded categorical data with Target Mean Encoding using Stratified KFolds technique!
X:
mean radius mean texture ... worst symmetry worst fractal dimension
527 12.340 12.27 ... 0.3110 0.07592
43 13.280 20.28 ... 0.3739 0.10270
371 15.190 13.21 ... 0.2487 0.06766
82 25.220 24.91 ... 0.2355 0.10510
534 10.960 17.62 ... 0.2289 0.08278
.. ... ... ... ... ...
506 12.220 20.04 ... 0.2709 0.08839
423 13.660 19.13 ... 0.2744 0.08839
116 8.950 15.76 ... 0.1652 0.07722
71 8.888 14.64 ... 0.2254 0.10840
103 9.876 19.40 ... 0.2622 0.08490
[170 rows x 30 columns]
Test Data:
mean radius mean texture ... worst symmetry worst fractal dimension
416 9.405 21.70 ... 0.2872 0.08304
522 11.260 19.83 ... 0.2557 0.07613
503 23.090 19.83 ... 0.2908 0.07277
111 12.630 20.76 ... 0.2226 0.08486
132 16.160 21.54 ... 0.3480 0.07619
.. ... ... ... ... ...
105 13.110 15.56 ... 0.3147 0.14050
530 11.750 17.56 ... 0.2478 0.07757
507 11.060 17.12 ... 0.2780 0.11680
11 15.780 17.89 ... 0.3792 0.10480
319 12.430 17.00 ... 0.1901 0.05932
[399 rows x 30 columns]
************************************************************
************************************************************
Generating new features !
************************************************************
[AutoFeat] The 2 step feature engineering process could generate up to 22155 features.
[AutoFeat] With 170 data points this new feature matrix would use about 0.02 gb of space.
[feateng] Step 1: transformation of original features
[feateng] Generated 155 transformed features from 30 original features - done.
[feateng] Step 2: first combination of features
[feateng] Generated 16575 feature combinations from 17020 original feature tuples - done.
[feateng] Generated altogether 17103 new features in 2 steps
[feateng] Removing correlated features, as well as additions at the highest level
[feateng] Generated a total of 7659 additional features
[featsel] Scaling data...done.
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=-1)]: Done 1 tasks | elapsed: 2.9min
[Parallel(n_jobs=-1)]: Done 2 tasks | elapsed: 3.1min
[Parallel(n_jobs=-1)]: Done 3 out of 5 | elapsed: 6.3min remaining: 4.2min
[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 7.9min remaining: 0.0s
[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 7.9min finished
[featsel] 23 features after 5 feature selection runs
[featsel] 8 features after correlation filtering
[featsel] 6 features after noise filtering
[AutoFeat] Computing 6 new features.
[AutoFeat] 6/ 6 new features ...done.
[AutoFeat] Final dataframe with 36 feature columns (6 new).
[AutoFeat] Training final classification model.
[AutoFeat] Trained model: largest coefficients:
[38.95073469]
8.246416 * meanconcavepoints/meancompactness
5.199850 * sqrt(worstsmoothness)*log(worstarea)
4.653543 * log(worstcompactness)/areaerror
2.491452 * log(worstradius)*log(worsttexture)
1.975475 * worstconcavepoints**2/meancompactness
0.115434 * log(radiuserror)/worstarea
[AutoFeat] Final score: 0.9765
[AutoFeat] Computing 6 new features.
[AutoFeat] 6/ 6 new features ...done.
************************************************************
Successfully generated new features! and selected the best features
X:
mean radius ... meanconcavepoints/meancompactness
0 12.340 ... 0.419692
1 13.280 ... 0.428830
2 15.190 ... 0.383184
3 25.220 ... 0.692308
4 10.960 ... 0.285890
.. ... ... ...
165 12.220 ... 0.188021
166 13.660 ... 0.419529
167 8.950 ... 0.185680
168 8.888 ... 0.187590
169 9.876 ... 0.312365
[170 rows x 36 columns]
Test Data:
mean radius ... meanconcavepoints/meancompactness
0 9.405 ... 0.204092
1 11.260 ... 0.128348
2 23.090 ... 0.786667
3 12.630 ... 0.498015
4 16.160 ... 0.437150
.. ... ... ...
394 13.110 ... 0.543966
395 11.750 ... 0.457119
396 11.060 ... 0.398506
397 15.780 ... 0.511300
398 12.430 ... 0.491893
[399 rows x 36 columns]
************************************************************
gml.Auto_Feature_Engineering這個函數自動新增6個features於new_X與new_Test_X。
print(new_X.shape)
print(new_Test_X.shape)
(170, 36)
(399, 36)
稍微預覽一下他新增了哪些變數。
new_X.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | radius error | texture error | perimeter error | area error | smoothness error | compactness error | concavity error | concave points error | symmetry error | fractal dimension error | worst radius | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | sqrt(worstsmoothness)*log(worstarea) | worstconcavepoints**2/meancompactness | log(worstradius)*log(worsttexture) | log(radiuserror)/worstarea | log(worstcompactness)/areaerror | meanconcavepoints/meancompactness | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 12.34 | 12.27 | 78.94 | 468.5 | 0.09003 | 0.06307 | 0.02958 | 0.02647 | 0.1689 | 0.05808 | 0.1166 | 0.4957 | 0.7714 | 8.955 | 0.003681 | 0.009169 | 0.008732 | 0.005740 | 0.01129 | 0.001366 | 13.61 | 19.27 | 87.22 | 564.9 | 0.1292 | 0.2074 | 0.1791 | 0.10700 | 0.3110 | 0.07592 | 2.277670 | 0.181528 | 7.724195 | -0.003804 | -0.175668 | 0.419692 |
| 1 | 13.28 | 20.28 | 87.32 | 545.2 | 0.10410 | 0.14360 | 0.09847 | 0.06158 | 0.1974 | 0.06782 | 0.3704 | 0.8249 | 2.4270 | 31.330 | 0.005072 | 0.021470 | 0.021850 | 0.009560 | 0.01719 | 0.003317 | 17.38 | 28.00 | 113.10 | 907.2 | 0.1530 | 0.3724 | 0.3664 | 0.14920 | 0.3739 | 0.10270 | 2.663888 | 0.155018 | 9.514511 | -0.001095 | -0.031528 | 0.428830 |
| 2 | 15.19 | 13.21 | 97.65 | 711.8 | 0.07963 | 0.06934 | 0.03393 | 0.02657 | 0.1721 | 0.05544 | 0.1783 | 0.4125 | 1.3380 | 17.720 | 0.005012 | 0.014850 | 0.015510 | 0.009155 | 0.01647 | 0.001767 | 16.20 | 15.73 | 104.50 | 819.1 | 0.1126 | 0.1737 | 0.1362 | 0.08178 | 0.2487 | 0.06766 | 2.251001 | 0.096452 | 7.674293 | -0.002105 | -0.098782 | 0.383184 |
| 3 | 25.22 | 24.91 | 171.50 | 1878.0 | 0.10630 | 0.26650 | 0.33390 | 0.18450 | 0.1829 | 0.06782 | 0.8973 | 1.4740 | 7.3820 | 120.000 | 0.008166 | 0.056930 | 0.057300 | 0.020300 | 0.01065 | 0.005893 | 30.00 | 33.62 | 211.70 | 2562.0 | 0.1573 | 0.6076 | 0.6476 | 0.28670 | 0.2355 | 0.10510 | 3.112816 | 0.308431 | 11.955621 | -0.000042 | -0.004152 | 0.692308 |
| 4 | 10.96 | 17.62 | 70.79 | 365.6 | 0.09687 | 0.09752 | 0.05263 | 0.02788 | 0.1619 | 0.06408 | 0.1507 | 1.5830 | 1.1650 | 10.090 | 0.009501 | 0.033780 | 0.044010 | 0.013460 | 0.01322 | 0.003534 | 11.62 | 26.51 | 76.43 | 407.5 | 0.1428 | 0.2510 | 0.2123 | 0.09861 | 0.2289 | 0.08278 | 2.271128 | 0.099712 | 8.038869 | -0.004644 | -0.136997 | 0.285890 |
GML: Auto Machine Learning (Classification)
在AUTO Machine Learning中,將進行兩輪競爭,第一輪所有模型將利用5-folds cv的準確率爭奪前5名,第二輪競爭時,前5名的模型將再競爭一次.並最終推薦排名第一的模型。
from sklearn.neural_network import MLPClassifier
best_model = gml.GMLClassifier(new_X,y,neural_net='Yes',epochs=100,models=[MLPClassifier()],verbose=False)
Model LogisticRegressionCV got validation accuracy of 0.9411764705882353
Model LogisticRegression got validation accuracy of 0.9607843137254902
Model SVC got validation accuracy of 0.9803921568627451
Model DecisionTreeClassifier got validation accuracy of 0.9411764705882353
Model KNeighborsClassifier got validation accuracy of 1.0
Model SGDClassifier got validation accuracy of 0.9411764705882353
Model RandomForestClassifier got validation accuracy of 0.9803921568627451
Model AdaBoostClassifier got validation accuracy of 0.9607843137254902
Model ExtraTreesClassifier got validation accuracy of 1.0
Model XGBClassifier got validation accuracy of 0.9607843137254902
Model LGBMClassifier got validation accuracy of 1.0
Model CatBoostClassifier got validation accuracy of 1.0
Model GradientBoostingClassifier got validation accuracy of 0.9607843137254902
Model NaiveBayesGaussian got validation accuracy of 0.9803921568627451
Model MLPClassifier got validation accuracy of 0.9607843137254902
****************************************
Training Neural Network
****************************************
Neural Network got validation accuracy of 0.9607843137254902
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 256) 9472
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
dense_5 (Dense) (None, 128) 32896
_________________________________________________________________
dropout_3 (Dropout) (None, 128) 0
_________________________________________________________________
dense_6 (Dense) (None, 64) 8256
_________________________________________________________________
dense_7 (Dense) (None, 2) 130
=================================================================
Total params: 50,754
Trainable params: 50,754
Non-trainable params: 0
_________________________________________________________________
None
************************************************************
Round One Results
************************************************************
Model Val_Accuracy CV on 5 folds
0 SVC 0.980392 0.970588
0 MLPClassifier 0.960784 0.970588
0 LGBMClassifier 1.000000 0.964706
0 RandomForestClassifier 0.980392 0.964706
0 ExtraTreesClassifier 1.000000 0.964706
0 CatBoostClassifier 1.000000 0.964706
0 Neural Network 0.960784 0.960784
0 LogisticRegressionCV 0.941176 0.958824
0 LogisticRegression 0.960784 0.958824
0 KNeighborsClassifier 1.000000 0.958824
0 XGBClassifier 0.960784 0.952941
0 GradientBoostingClassifier 0.960784 0.947059
0 NaiveBayesGaussian 0.980392 0.935294
0 SGDClassifier 0.941176 0.929412
0 AdaBoostClassifier 0.960784 0.923529
0 DecisionTreeClassifier 0.941176 0.917647
************************************************************
Model SVC got validation accuracy of 0.9607843137254902
Model Sequential got validation accuracy of 0.9607843137254902
Model LGBMClassifier got validation accuracy of 0.9215686274509803
Model RandomForestClassifier got validation accuracy of 0.9411764705882353
Model ExtraTreesClassifier got validation accuracy of 0.9803921568627451
************************************************************
Round Two Results
************************************************************
Model Val_Accuracy CV on 5 folds
0 Sequential 0.960784 0.970588
0 SVC 0.960784 0.970588
0 LGBMClassifier 0.921569 0.964706
0 RandomForestClassifier 0.941176 0.964706
0 ExtraTreesClassifier 0.980392 0.964706
************************************************************
****************************************
Suggested Models for Stacking
****************************************
0 Sequential
0 SVC
0 LGBMClassifier
Name: Model, dtype: object
****************************************
PLEASE NOTE: these results are calculated using <function accuracy_score at 0x7f002cd11048>
最終GML推薦我們使用SVC,RandomForestClassifier,Sequential來建立stacking模型。
我們來看看最終best_model:Sequential的超參數為哪些。
best_model
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_fun=15000, max_iter=200,
momentum=0.9, n_iter_no_change=10, nesterovs_momentum=True,
power_t=0.5, random_state=None, shuffle=True, solver='adam',
tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)
GML Test
將GML新增變數後的data匯入模型中訓練,最後將測試集(也利用GML新增變數後)的資料匯入模型當中做預測,看看效果如何。
clf = best_model.fit(new_X,y)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, clf.predict(new_Test_X))
0.9423558897243107
這個準確率好像還好,試試看用原始train data或其他方法來建模看看效果如何。
# 使用GML補值後的train data
from sklearn.ensemble import RandomForestClassifier
rf_model = RandomForestClassifier(max_depth=2)
rf_clf = rf_model.fit(new_X,y)
accuracy_score(y_test, rf_clf.predict(new_Test_X))
0.9699248120300752
# 使用原始train data
rf_model = RandomForestClassifier(max_depth=2)
rf_clf = rf_model.fit(X_train,y)
accuracy_score(y_test, rf_clf.predict(X_test))
0.9448621553884712
Conclusion
因沒建立stacking模型因此難判定說推薦的best_model效果不佳,但它確實非常便利,尤其在自動特徵工程中所自動生成的交互作用項,都有不錯的效果(這次實驗內),以randomforest的情況為例,在使用new data訓練下的模型最終預測率大概比原始data的準確率高大約10%左右。
因此它可以快速處理資料、建立模型、挑選超參數、並有一定程度的預測準確率。