這禮拜也有同網站的內容要爬(https://heavenlyfood.cn/books/index.php?id=4000) ,其主要結構與上星期的篇章雷同,因此沿用上星期的code,只是在最後抓取文章文件的時候,有遇到一些問題,如下圖:
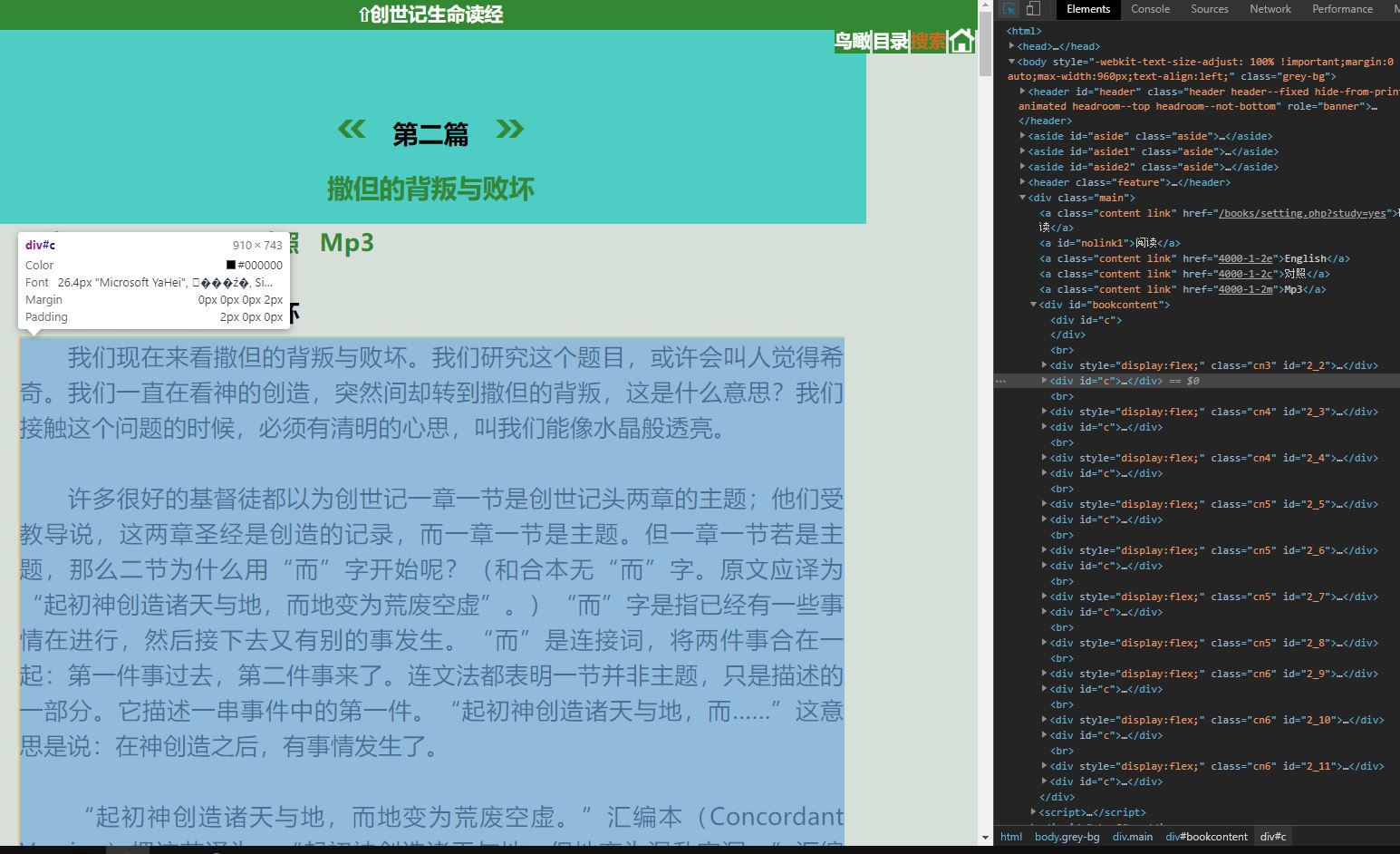
如果有爬蟲經驗的人應該可以看出他文章主要是在一個名稱叫做div#c 這個nodes下存放,而我在整頁結構確認後,便使用R去執行html_nodes去抓這些節點,但經由文字提取的函數,卻抓不到任何文字。
後來發現,文章文字的內容,並不在文章的這個連結內,而是頁面結構先載入,而後內容才進行加載,這個一般稱為delay-load的問題,主要指我們想爬取的內容並非第一時間就在網頁結構上,這會讓一般的爬蟲code失效。原先想要用python的套件來處理這個問題,後來觀察他network的情況後,發現文章載入的連結,如下圖:
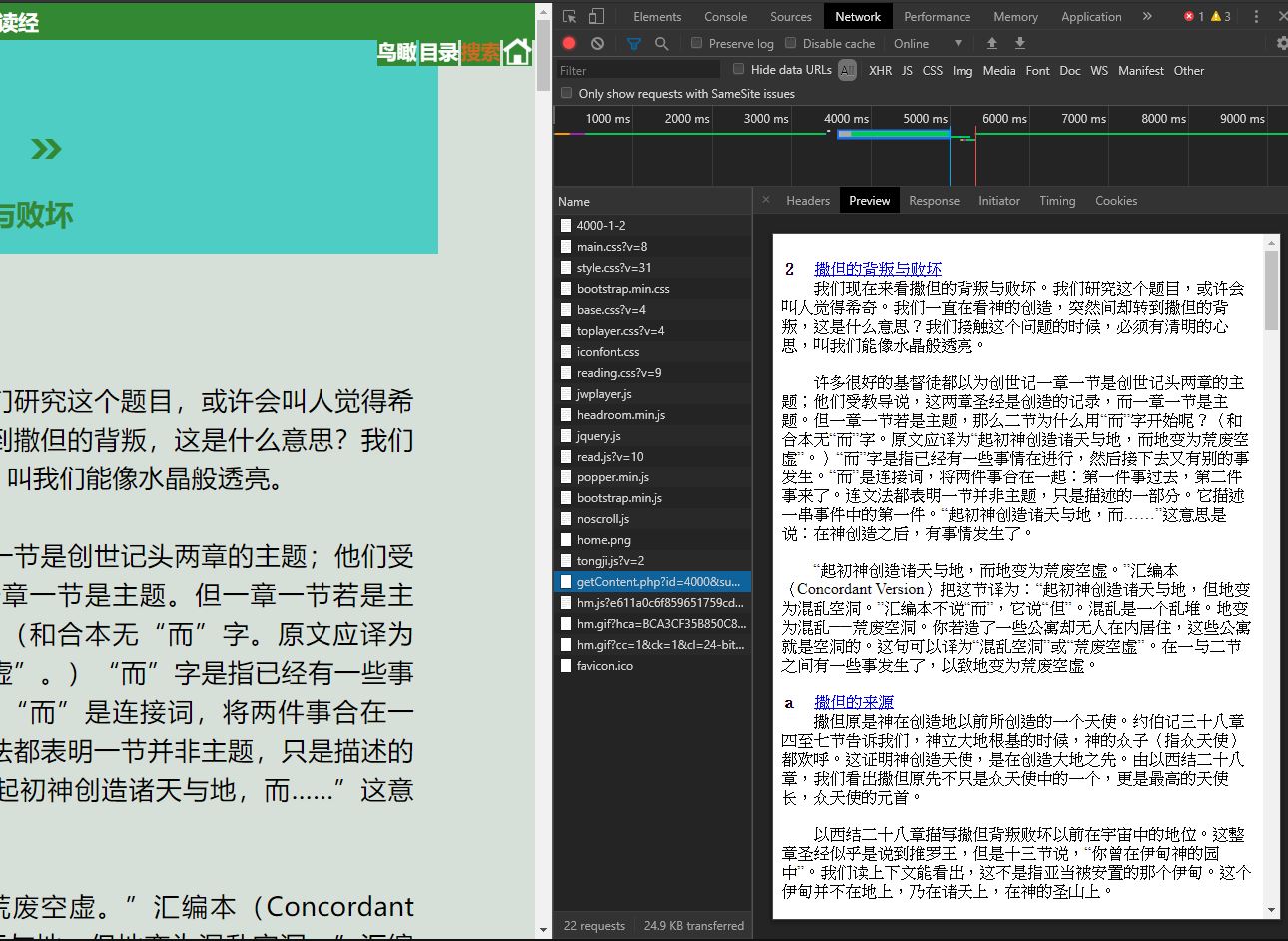
可以發現到它文章結構是在葉面開啟後接近4000毫秒才加載,因此我直接改成抓取這個連結內部的文字,便解決了這個網頁內容爬取的問題。
最終存儲的結果:
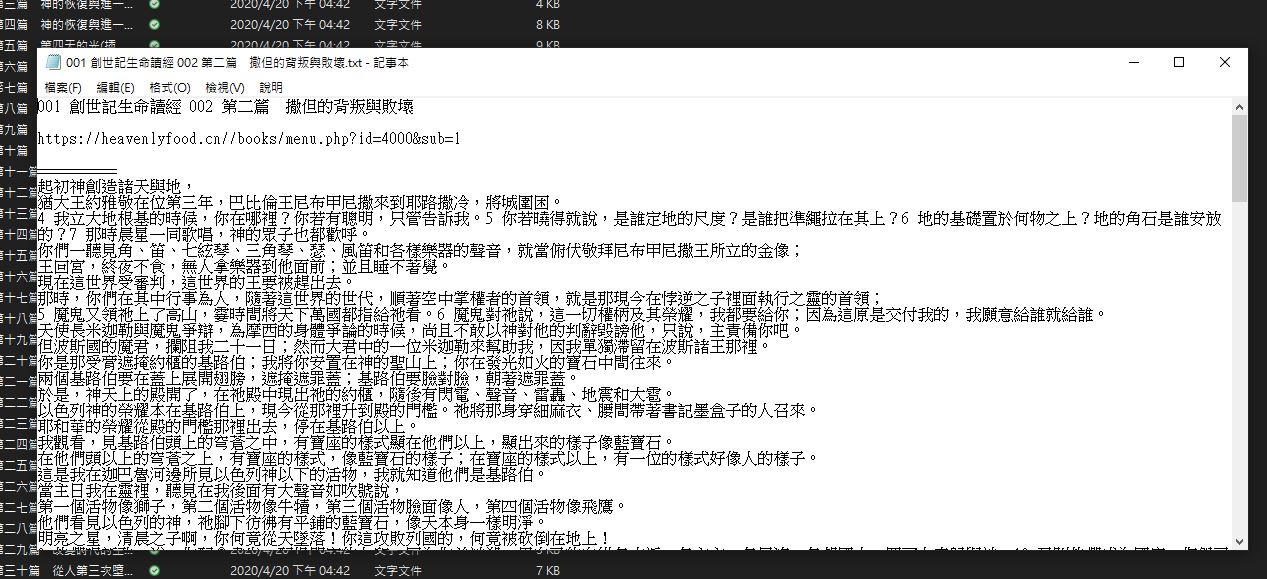
下面附上這結構的code:
import packages
if (!require(httr))install.packages("httr")
library(httr)
if (!require(rvest))install.packages("rvest")
library(rvest)
if (!require(ropencc))devtools::install_github("qinwf/ropencc")
library(ropencc)
# def simple to traditional
trans <- converter(S2TWP)
# setting a fake user agent
uastring <- "Mozilla/5.0 (Macintosh Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
Contents processing
library(stringr)
# def string replace
stringReplace <- function(txt){
txt <- str_replace_all(txt,"([。:、,])[.]+([0-9]+)\U00A0","\\1\n \\2 ")
txt <- str_replace_all(txt,"×","\n")
txt <- gsub("。,", "。", txt)
txt <- gsub("。。", "。", txt)
txt <- gsub("。:", "。:", txt)
txt <- gsub(";。", ";", txt)
txt <- gsub(",:", ",", txt)
# str_detect(text,"([0-9]+)\\1\U00A0")
txt <- gsub("\U00A0", " ", txt)
txt <- gsub("\U53C4", "叄", txt)
txt <- str_replace_all(txt,"\n+","\n\n")
return(txt)
}
id頁抓取標題& link
id = 4000
view_link <- paste0("https://heavenlyfood.cn/books/index.php?id=",id)
id_link <- read_html(html_session(view_link, user_agent(uastring)))
# 文章篇數
msg_num <- length(html_text(html_nodes(id_link,"div#menu a")))
# 抓取branch文字
#46 哥林多前書 31 (1311) 第三十一篇 變化為著建造
w1 = "TOC"## TOC
w4 = strsplit(view_link,split="id=",fixed=T)[[1]][2]
w5 = run_convert(trans, html_text(html_nodes(id_link,"div#toptitle")))
w6 = paste0(msg_num,"篇")
w = paste(w1,w4,w5,w6)
ex = paste("說明",w4,w5,w6)
bar<- "=========="
# 抓取sub章標題
id1 <- html_nodes(id_link,"div#menu a")
sub_title_list <- html_text(id1)
sub_title <- run_convert(trans, sub_title_list)
# create folder
id_name <- paste(w4,w5,w6)
folder <- paste0("./",id_name)
dir.create(folder)
# set wd
id_path = paste0(getwd(),"/",id_name)
setwd(id_path)
# 寫出id頁
id_page <- c(w,bar,view_link,sub_title,bar,bar)
write.table(id_page,paste0(w,".txt"),row.names = FALSE,col.names = FALSE,quote = FALSE,fileEncoding="UTF-8")
# 寫出id說明頁
ex_page <- c(ex,bar,view_link,sub_title,bar,bar)
write.table(ex_page,paste0(ex,".txt"),row.names = FALSE,col.names = FALSE,quote = FALSE,fileEncoding="UTF-8")
# 抓取sub link
url <- html_nodes(id_link,"div#menu a")
sub_links <- paste0("https://heavenlyfood.cn/",html_attr(html_nodes(id_link,"div#menu a"),"href"))
sub頁抓取標題&link&存msg
# 讀取sub頁面
for(ii in 1:length(sub_links)){
setwd(id_path)
sub_link <- sub_links[ii]
link <- sub_link
sub <- html_session(sub_link, user_agent(uastring))
sub <- read_html(sub)
# 抓取文章link
url <- html_nodes(sub,"div#title")
urls <- paste0("https://heavenlyfood.cn/view/",html_attr(html_nodes(sub,"div#title a#wtt"),"href"))
# 抓取branch文字
w1 = "TOC"## TOC
w2 = strsplit(link,split="sub=",fixed=T)[[1]][2]## 46
w3 = run_convert(trans, html_text(html_node(sub,"div#chap1 a#mainwhite")))## 哥林多前書生命讀經
w5 = run_convert(trans, html_text(html_nodes(id_link,"div#toptitle")))## 生命讀經
w6 = if(length(url)<100){w6 = paste0("0",length(url),"篇")}else{w6 = paste0(length(url),"篇")}## 篇
w = paste(w1,w2,w3,w5,w6)
bar<- "=========="
# 抓取文章標題
sub1 <- html_nodes(sub,"div#title")
book_title_list <- html_text(sub1)
book_title <- run_convert(trans, book_title_list[1:length(book_title_list)])
# 抓取文章link
sub2 <- html_nodes(sub,"div#title div a.content.link")
urls <- paste0("https://heavenlyfood.cn/books/",html_attr(sub2 ,"href"))
# create a folder
folder <- paste0("./",paste(w2,w3,w5,w6))
dir.create(folder)
# set wd
path = paste0("./",paste(w2,w3,w5,w6))
setwd(path)
# 寫出sub頁
sub_page <- c(w,bar,link,book_title,bar,bar)
write.table(sub_page,paste0(w,".txt"),row.names = FALSE,col.names = FALSE,quote = FALSE,fileEncoding="UTF-8")
# 寫出說明頁
ex = paste("說明",w2,w3,w5,w6)
ex_page <- c(ex,bar,link,book_title,bar,bar)
write.table(ex_page,paste0(ex,".txt"),row.names = FALSE,col.names = FALSE,quote = FALSE,fileEncoding="UTF-8")
# message 文章儲存
msg_link <- "https://heavenlyfood.cn/books/getContent.php?id=4000&sub=46&message=1&contentData=Spritualbooks&assist=&study=1&collect=&q="
for(i in 1:length(book_title_list)){
msg_link <- urls[i]
msg_link <- paste0("https://heavenlyfood.cn/books/getContent.php?id=",id,"&sub=",w2,"&message=",i,"&contentData=Spritualbooks&assist=&study=1&collect=&q=")
msg1 <- read_html(html_session(msg_link, user_agent(uastring)))
cont1 <- run_convert(trans,c(html_text(html_nodes(msg1,"div.modal-body"))))
cont1 <- stringReplace(cont1)
## 整合匯出
{if(i<10){wi = paste0("00",i)}
else if(100>i & i>10){wi = paste0("0",i)}}
{if(as.numeric(w2)<10){w22 = paste0("00",as.numeric(w2))}
else if(100>as.numeric(w2) & as.numeric(w2)>10){w22 = paste0("0",as.numeric(w2))}}
msg_w = paste(w22,w3,wi,book_title[i])
write.table(c(msg_w,"",link,"",bar,cont1,bar),paste0(msg_w,".txt"),fileEncoding="UTF-8",row.names = FALSE,col.names = FALSE,quote = FALSE)}
}