這禮拜在撰寫論文的時候,因為有一段需要更詳細說明所謂的Anomaly Detection,因而發現了一個也可以進行相同工作的方法-“Auto Encoder”,且他號稱有著更佳的分類效果,因此就看了一些介紹此方法的文章以及實作,下面我將使用breast cancer data的前一百筆當作練習範本,嘗試建立一個Auto Encoder for Anomaly Detection。
1.What is the Auto Encoder?
Autoencoder是一種無監督式學習模型。本質上它使用了一個神經網絡來產生一個高維輸入的低維表示。 Autoencoder與主成分分析PCA類似,但是Autoencoder在使用非線性激活函數時克服了PCA線性的限制。
Autoencoder包含兩個主要的部分,encoder(編碼器)和 decoder(解碼器)。 Encoder的作用是用來發現給定數據的壓縮表示,decoder是用來重建原始輸入。在訓練時,decoder 強迫 autoencoder 選擇最有信息量的特徵,最終保存在壓縮表示中。最終壓縮後的表示就在中間的coder層當中。
以下圖為例,原始數據的維度是10,encoder和decoder分別有兩層,中間的coder共有3個節點,也就是說原始數據被降到了只有3維。 Decoder根據降維後的數據再重建原始數據,重新得到10維的輸出。從Input到Ouptut的這個過程中,autoencoder實際上也起到了降噪的作用。
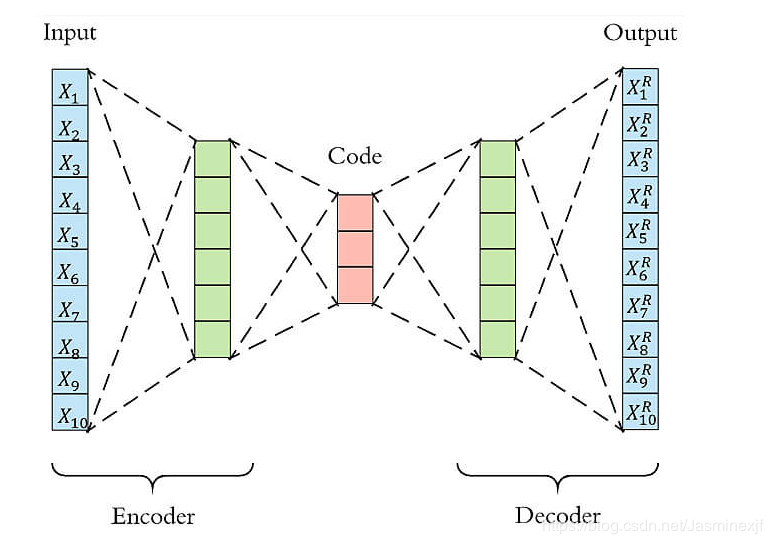
而AutoEncoder的內部構造,說白了就是把輸入資料,通過數層的神經網路並輸出一份接近的資料。聽起來就是複製而已,但典型的AE還會有內部表示層(Internal Representation),透過對一些維度限制、或加入雜訊到輸入資料,讓整個AE的結構更加複雜,整個流程就不是只有「複製輸入到輸出」,這樣單純而已了,其中最重要的就是輸出的數量(神經元)要跟輸入一樣。
另外Autoencoder要如何做到無監督異常檢測?異常檢測(anomaly detection)通常分為有監督和無監督兩種情形。在無監督的情況下,我們沒有異常樣本用來學習,而算法的基本上假設是異常點服從不同的分佈。根據正常數據訓練出來的Autoencoder,能夠將正常樣本重建還原,但是卻無法將異於正常分佈的數據點較好地還原,導致還原誤差較大。
以下假設原先資料為\(X = (X_1,X_2,X_3,X_4,X_5,X_6,X_7,X_8,X_9,X_{10})\)
經過Autoencoder重建的結果為\(X^R = (X^R_1,X^R_2,X^R_3,X^R_4,X^R_5,X^R_6,X^R_7,X^R_8,X^R_9,X^R_{10})\)
如果樣本的特徵都是數值變量,我們可以用MSE或者MAE作為還原誤差。
則還原誤差MSE為:\(\frac{1}{10} \sum_{i = 1}^{10}{(X_i-X^R_i)^2}\)
而還原誤差MAE為:\(\frac{1}{10} \sum_{i = 1}^{10}{|X_i-X^R_i|}\)
2.Import Data & Standard Scaler
這裡讀取之前用過的breast cancer資料,且抓取前100筆資料當作sample,想透過Autoencoder來檢測樣本是否為乳癌患者。
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
#d = pd.read_csv('C:/Users/User/OneDrive - student.nsysu.edu.tw/Documents/dataset/creditcard.csv')
df = datasets.load_breast_cancer()
x = pd.DataFrame(df['data'],columns = df['feature_names'])[0:100]
x = pd.DataFrame(StandardScaler().fit_transform(x))
y = pd.DataFrame(df['target'],columns = ['targets_names'])[0:100]
d = pd.concat([x,y],axis = 1)
#show the data of labels
%matplotlib inline
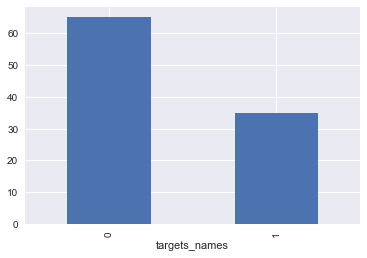
by_fraud = y.groupby('targets_names')
by_fraud.size().plot(kind = 'bar')<matplotlib.axes._subplots.AxesSubplot at 0x1d953959c88>有症狀vs無症狀樣本比例:
35:65
引入套件
import pandas as pd
import numpy as np
import pickle
import matplotlib.pyplot as plt
plt.style.use('seaborn')
import tensorflow as tf
import seaborn as sns
from sklearn.model_selection import train_test_split
from keras.models import Model, load_model
from keras.layers import Input, Dense
from keras.callbacks import ModelCheckpoint
from keras import regularizers
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_curve, auc, precision_recall_curve3.Model Setting
我將資料裡未得病的一半當作訓練集,其餘的一半未得病以及35名病患皆當作測試集。
# 查看樣本比例
num_nonfraud = np.sum(d['targets_names'] == 0)
num_fraud = np.sum(d['targets_names'] == 1)
plt.bar(['Positive', 'Negative'], [num_fraud, num_nonfraud], color='dodgerblue')
plt.show()
data = d
# 提取負樣本,並且按照1:1切成訓練集和測試集
mask = (data['targets_names'] == 0)
X_train, X_test = train_test_split(data[mask], test_size=0.5, random_state=920)
X_train = X_train.drop(['targets_names'], axis=1).values
X_test = X_test.drop(['targets_names'], axis=1).values
# 提取所有正樣本,作為測試集的一部分
X_fraud = data[~mask].drop(['targets_names'], axis=1).values
# 設置Autoencoder的參數
# 隱藏層節點數分別為16,8,8,16
# epoch為50,batch size為32
input_dim = X_train.shape[1]
encoding_dim = 16
num_epoch = 250
batch_size = 32
input_layer = Input(shape=(input_dim, ))
encoder = Dense(encoding_dim, activation="tanh",
activity_regularizer=regularizers.l1(10e-5))(input_layer)
encoder = Dense(int(encoding_dim / 2), activation="relu")(encoder)
decoder = Dense(int(encoding_dim / 2), activation='tanh')(encoder)
decoder = Dense(input_dim, activation='relu')(decoder)
autoencoder = Model(inputs=input_layer, outputs=decoder)
autoencoder.compile(optimizer='adam',loss='mean_squared_error',metrics=['mae'])
# 模型保存為hermit_model,並開始訓練模型
checkpointer = ModelCheckpoint(filepath="hermit_model",verbose=0,save_best_only=True)
history = autoencoder.fit(X_train, X_train,
epochs=num_epoch,
batch_size=batch_size,
shuffle=True,
validation_data=(X_test, X_test),
verbose=1,
callbacks=[checkpointer]).history
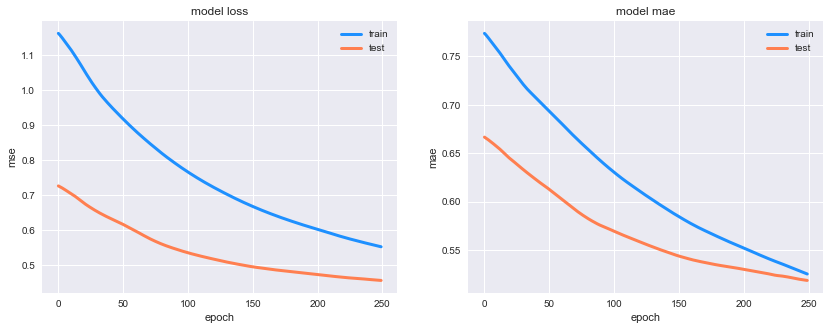
# 畫出損失函數曲線
plt.figure(figsize=(14, 5))
plt.subplot(121)
plt.plot(history['loss'], c='dodgerblue', lw=3)
plt.plot(history['val_loss'], c='coral', lw=3)
plt.title('model loss')
plt.ylabel('mse'); plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
plt.subplot(122)
plt.plot(history['mean_absolute_error'], c='dodgerblue', lw=3)
plt.plot(history['val_mean_absolute_error'], c='coral', lw=3)
plt.title('model mae')
plt.ylabel('mae'); plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right');Train on 32 samples, validate on 33 samples
Epoch 1/250
32/32 [==============================] - 1s 41ms/step - loss: 1.1633 - mean_absolute_error: 0.7738 - val_loss: 0.7262 - val_mean_absolute_error: 0.6667
Epoch 2/250
32/32 [==============================] - 0s 93us/step - loss: 1.1595 - mean_absolute_error: 0.7725 - val_loss: 0.7242 - val_mean_absolute_error: 0.6658
Epoch 3/250
32/32 [==============================] - 0s 93us/step - loss: 1.1550 - mean_absolute_error: 0.7709 - val_loss: 0.7222 - val_mean_absolute_error: 0.6649
Epoch 4/250
32/32 [==============================] - 0s 62us/step - loss: 1.1502 - mean_absolute_error: 0.7692 - val_loss: 0.7201 - val_mean_absolute_error: 0.6639
Epoch 5/250
32/32 [==============================] - 0s 94us/step - loss: 1.1453 - mean_absolute_error: 0.7674 - val_loss: 0.7179 - val_mean_absolute_error: 0.6629
Epoch 6/250
32/32 [==============================] - 0s 93us/step - loss: 1.1402 - mean_absolute_error: 0.7657 - val_loss: 0.7155 - val_mean_absolute_error: 0.6619
Epoch 7/250
32/32 [==============================] - 0s 95us/step - loss: 1.1352 - mean_absolute_error: 0.7639 - val_loss: 0.7131 - val_mean_absolute_error: 0.6608
Epoch 8/250
32/32 [==============================] - 0s 94us/step - loss: 1.1303 - mean_absolute_error: 0.7622 - val_loss: 0.7107 - val_mean_absolute_error: 0.6597
Epoch 9/250
32/32 [==============================] - 0s 94us/step - loss: 1.1254 - mean_absolute_error: 0.7605 - val_loss: 0.7083 - val_mean_absolute_error: 0.6586
Epoch 10/250
32/32 [==============================] - 0s 94us/step - loss: 1.1203 - mean_absolute_error: 0.7588 - val_loss: 0.7061 - val_mean_absolute_error: 0.6576
Epoch 11/250
32/32 [==============================] - 0s 93us/step - loss: 1.1150 - mean_absolute_error: 0.7570 - val_loss: 0.7038 - val_mean_absolute_error: 0.6565
Epoch 12/250
32/32 [==============================] - 0s 93us/step - loss: 1.1095 - mean_absolute_error: 0.7552 - val_loss: 0.7013 - val_mean_absolute_error: 0.6554
Epoch 13/250
32/32 [==============================] - 0s 94us/step - loss: 1.1039 - mean_absolute_error: 0.7534 - val_loss: 0.6988 - val_mean_absolute_error: 0.6542
Epoch 14/250
32/32 [==============================] - 0s 125us/step - loss: 1.0982 - mean_absolute_error: 0.7516 - val_loss: 0.6961 - val_mean_absolute_error: 0.6530
Epoch 15/250
32/32 [==============================] - 0s 94us/step - loss: 1.0925 - mean_absolute_error: 0.7497 - val_loss: 0.6933 - val_mean_absolute_error: 0.6517
Epoch 16/250
32/32 [==============================] - 0s 93us/step - loss: 1.0868 - mean_absolute_error: 0.7479 - val_loss: 0.6904 - val_mean_absolute_error: 0.6504
Epoch 17/250
32/32 [==============================] - 0s 94us/step - loss: 1.0809 - mean_absolute_error: 0.7459 - val_loss: 0.6875 - val_mean_absolute_error: 0.6491
Epoch 18/250
32/32 [==============================] - 0s 94us/step - loss: 1.0748 - mean_absolute_error: 0.7439 - val_loss: 0.6845 - val_mean_absolute_error: 0.6478
Epoch 19/250
32/32 [==============================] - 0s 93us/step - loss: 1.0687 - mean_absolute_error: 0.7419 - val_loss: 0.6817 - val_mean_absolute_error: 0.6465
Epoch 20/250
32/32 [==============================] - 0s 125us/step - loss: 1.0624 - mean_absolute_error: 0.7402 - val_loss: 0.6789 - val_mean_absolute_error: 0.6454
Epoch 21/250
32/32 [==============================] - 0s 62us/step - loss: 1.0563 - mean_absolute_error: 0.7384 - val_loss: 0.6762 - val_mean_absolute_error: 0.6442
Epoch 22/250
32/32 [==============================] - 0s 62us/step - loss: 1.0504 - mean_absolute_error: 0.7367 - val_loss: 0.6735 - val_mean_absolute_error: 0.6431
Epoch 23/250
32/32 [==============================] - 0s 94us/step - loss: 1.0445 - mean_absolute_error: 0.7350 - val_loss: 0.6710 - val_mean_absolute_error: 0.6421
Epoch 24/250
32/32 [==============================] - 0s 62us/step - loss: 1.0387 - mean_absolute_error: 0.7332 - val_loss: 0.6685 - val_mean_absolute_error: 0.6410
Epoch 25/250
32/32 [==============================] - 0s 94us/step - loss: 1.0328 - mean_absolute_error: 0.7314 - val_loss: 0.6661 - val_mean_absolute_error: 0.6399
Epoch 26/250
32/32 [==============================] - 0s 94us/step - loss: 1.0271 - mean_absolute_error: 0.7297 - val_loss: 0.6637 - val_mean_absolute_error: 0.6388
Epoch 27/250
32/32 [==============================] - 0s 94us/step - loss: 1.0216 - mean_absolute_error: 0.7279 - val_loss: 0.6613 - val_mean_absolute_error: 0.6376
Epoch 28/250
32/32 [==============================] - 0s 125us/step - loss: 1.0161 - mean_absolute_error: 0.7262 - val_loss: 0.6591 - val_mean_absolute_error: 0.6365
Epoch 29/250
32/32 [==============================] - 0s 94us/step - loss: 1.0108 - mean_absolute_error: 0.7244 - val_loss: 0.6568 - val_mean_absolute_error: 0.6354
Epoch 30/250
32/32 [==============================] - 0s 94us/step - loss: 1.0057 - mean_absolute_error: 0.7227 - val_loss: 0.6546 - val_mean_absolute_error: 0.6343
Epoch 31/250
32/32 [==============================] - 0s 94us/step - loss: 1.0006 - mean_absolute_error: 0.7210 - val_loss: 0.6525 - val_mean_absolute_error: 0.6331
Epoch 32/250
32/32 [==============================] - 0s 93us/step - loss: 0.9955 - mean_absolute_error: 0.7194 - val_loss: 0.6504 - val_mean_absolute_error: 0.6320
Epoch 33/250
32/32 [==============================] - 0s 93us/step - loss: 0.9906 - mean_absolute_error: 0.7179 - val_loss: 0.6483 - val_mean_absolute_error: 0.6310
Epoch 34/250
32/32 [==============================] - 0s 124us/step - loss: 0.9858 - mean_absolute_error: 0.7164 - val_loss: 0.6463 - val_mean_absolute_error: 0.6299
Epoch 35/250
32/32 [==============================] - 0s 93us/step - loss: 0.9813 - mean_absolute_error: 0.7149 - val_loss: 0.6444 - val_mean_absolute_error: 0.6289
Epoch 36/250
32/32 [==============================] - 0s 94us/step - loss: 0.9769 - mean_absolute_error: 0.7136 - val_loss: 0.6424 - val_mean_absolute_error: 0.6279
Epoch 37/250
32/32 [==============================] - 0s 93us/step - loss: 0.9726 - mean_absolute_error: 0.7122 - val_loss: 0.6405 - val_mean_absolute_error: 0.6268
Epoch 38/250
32/32 [==============================] - 0s 93us/step - loss: 0.9684 - mean_absolute_error: 0.7109 - val_loss: 0.6386 - val_mean_absolute_error: 0.6258
Epoch 39/250
32/32 [==============================] - 0s 93us/step - loss: 0.9643 - mean_absolute_error: 0.7095 - val_loss: 0.6368 - val_mean_absolute_error: 0.6247
Epoch 40/250
32/32 [==============================] - 0s 94us/step - loss: 0.9602 - mean_absolute_error: 0.7082 - val_loss: 0.6350 - val_mean_absolute_error: 0.6237
Epoch 41/250
32/32 [==============================] - 0s 94us/step - loss: 0.9561 - mean_absolute_error: 0.7068 - val_loss: 0.6333 - val_mean_absolute_error: 0.6226
Epoch 42/250
32/32 [==============================] - 0s 93us/step - loss: 0.9521 - mean_absolute_error: 0.7054 - val_loss: 0.6315 - val_mean_absolute_error: 0.6216
Epoch 43/250
32/32 [==============================] - 0s 94us/step - loss: 0.9482 - mean_absolute_error: 0.7041 - val_loss: 0.6297 - val_mean_absolute_error: 0.6206
Epoch 44/250
32/32 [==============================] - 0s 94us/step - loss: 0.9444 - mean_absolute_error: 0.7028 - val_loss: 0.6280 - val_mean_absolute_error: 0.6196
Epoch 45/250
32/32 [==============================] - 0s 94us/step - loss: 0.9405 - mean_absolute_error: 0.7015 - val_loss: 0.6263 - val_mean_absolute_error: 0.6187
Epoch 46/250
32/32 [==============================] - 0s 94us/step - loss: 0.9367 - mean_absolute_error: 0.7001 - val_loss: 0.6246 - val_mean_absolute_error: 0.6177
Epoch 47/250
32/32 [==============================] - 0s 94us/step - loss: 0.9329 - mean_absolute_error: 0.6988 - val_loss: 0.6229 - val_mean_absolute_error: 0.6168
Epoch 48/250
32/32 [==============================] - 0s 93us/step - loss: 0.9291 - mean_absolute_error: 0.6975 - val_loss: 0.6212 - val_mean_absolute_error: 0.6158
Epoch 49/250
32/32 [==============================] - 0s 94us/step - loss: 0.9253 - mean_absolute_error: 0.6961 - val_loss: 0.6194 - val_mean_absolute_error: 0.6148
Epoch 50/250
32/32 [==============================] - 0s 125us/step - loss: 0.9215 - mean_absolute_error: 0.6948 - val_loss: 0.6176 - val_mean_absolute_error: 0.6138此圖為訓練的損失值情況:
4.Results for MSE & MAE & both
我在這將會使用兩種方式計算誤差,並且使用兩種方式,設置自定義閥值(threshold),並用該閥值的結果來判定是否為異常資料並加以標記,最終計算AUC加以比較異常檢測效果。
# 讀取模型
autoencoder = load_model('hermit_model')
# 利用訓練好的autoencoder重建測試集
pred_test = autoencoder.predict(X_test)
pred_fraud = autoencoder.predict(X_fraud)
# 計算還原誤差MSE和MAE
mse_test = np.mean(np.power(X_test - pred_test, 2), axis=1)
mse_fraud = np.mean(np.power(X_fraud - pred_fraud, 2), axis=1)
mae_test = np.mean(np.abs(X_test - pred_test), axis=1)
mae_fraud = np.mean(np.abs(X_fraud - pred_fraud), axis=1)
mse_df = pd.DataFrame()
mse_df['targets_names'] = [0] * len(mse_test) + [1] * len(mse_fraud)
mse_df['MSE'] = np.hstack([mse_test, mse_fraud])
mse_df['MAE'] = np.hstack([mae_test, mae_fraud])
mse_df = mse_df.sample(frac=1).reset_index(drop=True)
# 計算還原誤差MSE和MAE
markers = ['o', '^']
markers = ['o', '^']
colors = ['dodgerblue', 'coral']
labels = ['Negative', 'Positive']
plt.figure(figsize=(14, 5))
plt.subplot(121)
for flag in [1, 0]:
temp = mse_df[mse_df['targets_names'] == flag]
plt.scatter(temp.index,
temp['MAE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.title('Reconstruction MAE')
plt.ylabel('Reconstruction MAE'); plt.xlabel('Index')
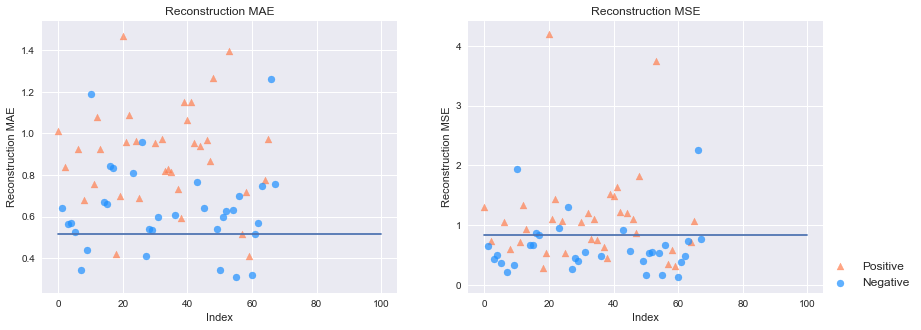
threshold = mse_df['MAE'].min()+0.8*mse_df['MAE'].std()
plt.plot([0,len(y)],[threshold,threshold])
plt.subplot(122)
for flag in [1, 0]:
temp = mse_df[mse_df['targets_names'] == flag]
plt.scatter(temp.index,
temp['MSE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.legend(loc=[1, 0], fontsize=12); plt.title('Reconstruction MSE')
threshold = mse_df['MSE'].min()+mse_df['MSE'].std()
plt.plot([0,len(y)],[threshold,threshold])
plt.ylabel('Reconstruction MSE'); plt.xlabel('Index')
plt.show()此圖左為使用MAE當作參考值的結果,線段為自定義的閥值;右圖則為MSE的結果:
用MSE的threshold的結果計算auc等統計量值
from sklearn import metrics
threshold = mse_df['MSE'].min()+mse_df['MSE'].std()
mse_df['targets_names']
mse_df['mse_y_pred'] = [1 if e > threshold else 0 for e in mse_df['MSE']]
mse_df['targets_names'].describe()
test_auc = metrics.roc_auc_score(mse_df['targets_names'], mse_df['mse_y_pred'])
print (test_auc)0.693939393939394用MAE的threshold的結果分類,計算auc等統計量值
from sklearn import metrics
threshold = mse_df['MAE'].min()+0.8*mse_df['MAE'].std()
mse_df['targets_names']
mse_df['mae_y_pred'] = [1 if e > threshold else 0 for e in mse_df['MAE']]
mse_df['targets_names'].describe()
test_auc = metrics.roc_auc_score(mse_df['targets_names'], mse_df['mae_y_pred'])
print (test_auc)0.548051948051948MSE分類結果的confusion matrix
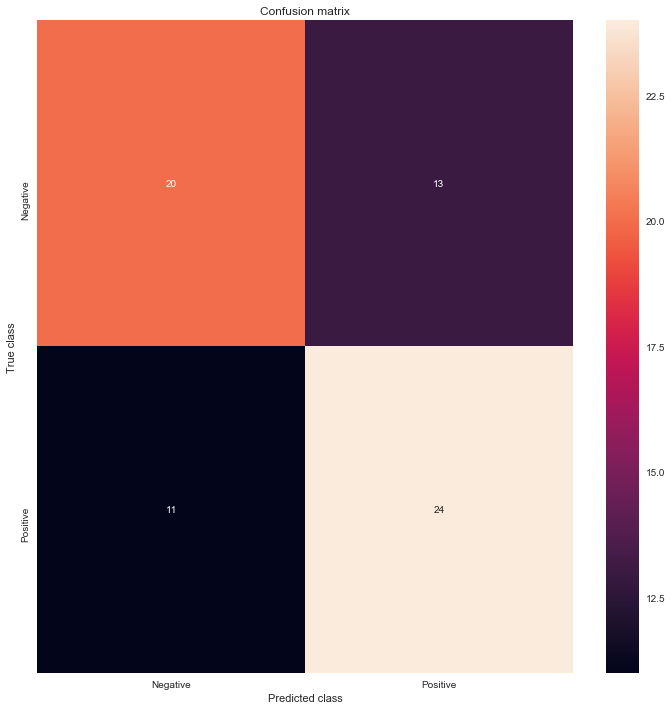
from sklearn.metrics import confusion_matrix
LABELS = ["Negative", "Positive"]
conf_matrix = confusion_matrix(mse_df['targets_names'], mse_df['mse_y_pred'])
plt.figure(figsize=(12, 12))
sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d");
plt.title("Confusion matrix")
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show()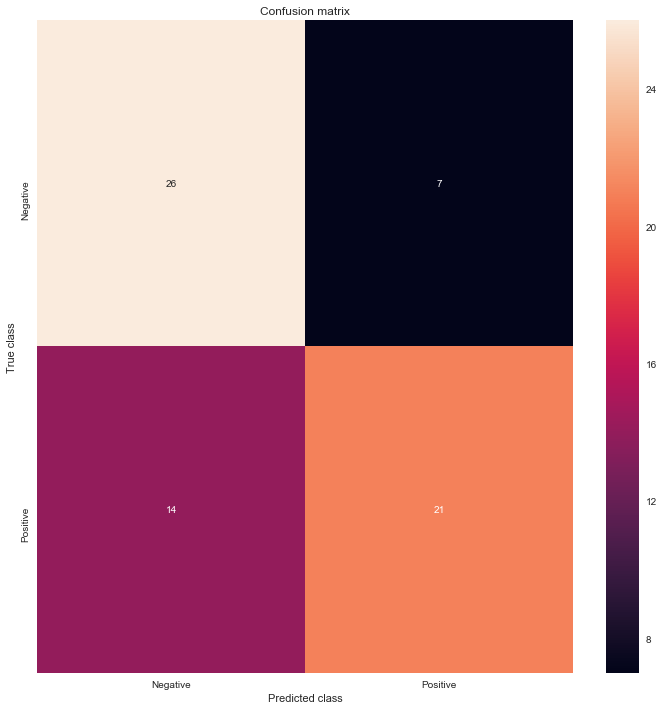
MAE分類結果的confusion matrix
from sklearn.metrics import confusion_matrix
LABELS = ["Negative", "Positive"]
conf_matrix = confusion_matrix(mse_df['targets_names'], mse_df['mae_y_pred'])
plt.figure(figsize=(12, 12))
sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d");
plt.title("Confusion matrix")
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show()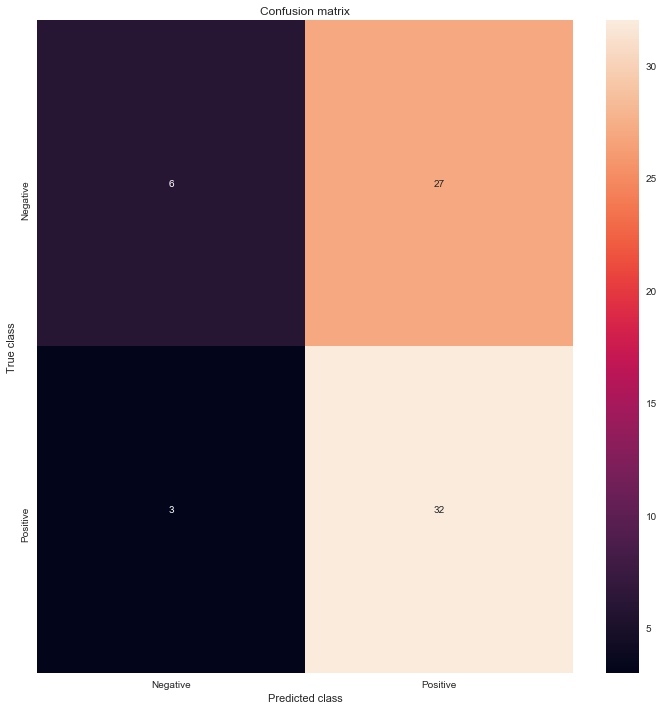
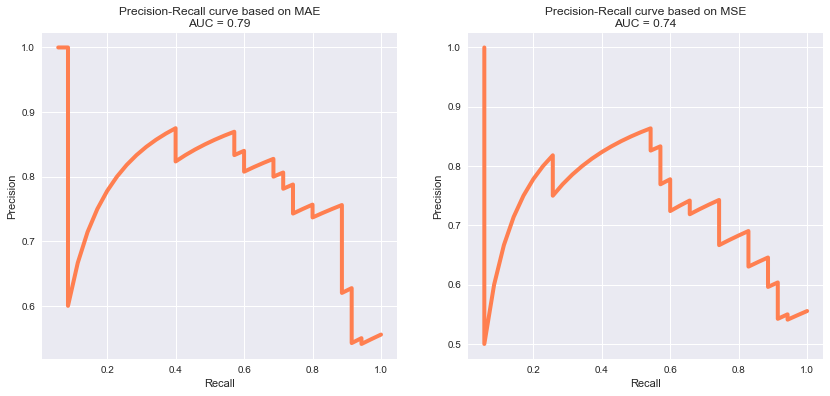
畫出Precision-Recall曲線與ROC曲線
# 畫出Precision-Recall曲線
plt.figure(figsize=(14, 6))
for i, metric in enumerate(['MAE', 'MSE']):
plt.subplot(1, 2, i+1)
precision, recall, _ = precision_recall_curve(mse_df['targets_names'], mse_df[metric])
pr_auc = auc(recall, precision)
plt.title('Precision-Recall curve based on %s\nAUC = %0.2f'%(metric, pr_auc))
plt.plot(recall[:-2], precision[:-2], c='coral', lw=4)
plt.xlabel('Recall'); plt.ylabel('Precision')
plt.show()
# 畫出ROC曲線
plt.figure(figsize=(14, 6))
for i, metric in enumerate(['MAE', 'MSE']):
plt.subplot(1, 2, i+1)
fpr, tpr, _ = roc_curve(mse_df['targets_names'], mse_df[metric])
roc_auc = auc(fpr, tpr)
plt.title('Receiver Operating Characteristic based on %s\nAUC = %0.2f'%(metric, roc_auc))
plt.plot(fpr, tpr, c='coral', lw=4)
plt.plot([0,1],[0,1], c='dodgerblue', ls='--')
plt.ylabel('TPR'); plt.xlabel('FPR')
plt.show()
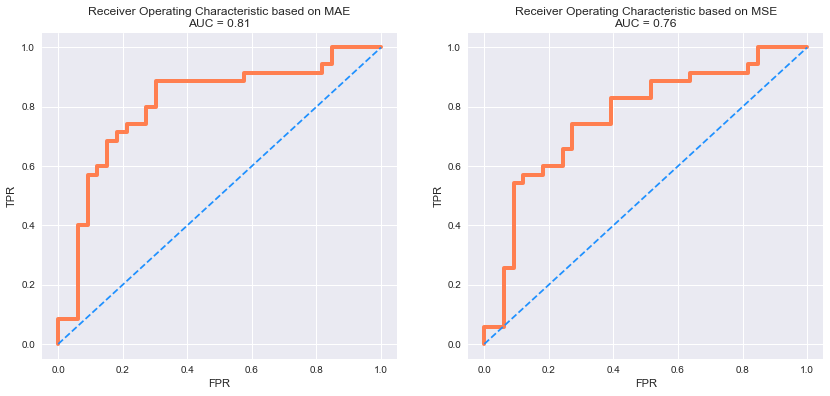
下面則為同時參考兩者MSE&MAE結果的分類情形:
#用MSE&MAE的threshold的結果分類,計算auc以及acc等統計量值
from sklearn import metrics
mse_threshold = mse_df['MSE'].min()+mse_df['MSE'].std()
mae_threshold = mse_df['MAE'].min()+0.8*mse_df['MAE'].std()
mse_df['msae_y_pred'] = 0
for i in range(len(mse_df['mse_y_pred'])):
if mse_df['mse_y_pred'][i] == mse_df['mae_y_pred'][i]:
mse_df['msae_y_pred'][i] = 1
mse_df['targets_names'].describe()
test_auc = metrics.roc_auc_score(mse_df['targets_names'], mse_df['msae_y_pred'])
print (test_auc)0.645887445887446
C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\ipykernel_launcher.py:9: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
if __name__ == '__main__':mse_df.head()| targets_names | MSE | MAE | y_pred | mse_y_pred | mae_y_pred | msae_y_pred | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1.303796 | 1.009276 | 1 | 1 | 1 | 1 |
| 1 | 0 | 0.651611 | 0.642855 | 1 | 0 | 1 | 0 |
| 2 | 1 | 0.732258 | 0.836285 | 1 | 0 | 1 | 0 |
| 3 | 0 | 0.440141 | 0.563211 | 1 | 0 | 1 | 0 |
| 4 | 0 | 0.502424 | 0.569734 | 1 | 0 | 1 | 0 |
# 畫出MSE、MAE散點圖
markers = ['o', '^']
colors = ['dodgerblue', 'coral']
labels = ['Negative', 'Positive']
plt.figure(figsize=(10, 5))
for flag in [1, 0]:
temp = mse_df[mse_df['targets_names'] == flag]
plt.scatter(temp['MAE'],
temp['MSE'],
alpha=0.7,
marker=markers[flag],
c=colors[flag],
label=labels[flag])
plt.legend(loc=[1, 0])
plt.plot([mse_threshold,mse_threshold],[0,mse_df['MSE'].max()])
plt.plot([0,mse_df['MAE'].max()],[mae_threshold,mae_threshold])
plt.ylabel('Reconstruction RMSE'); plt.xlabel('Reconstruction MAE')
plt.show()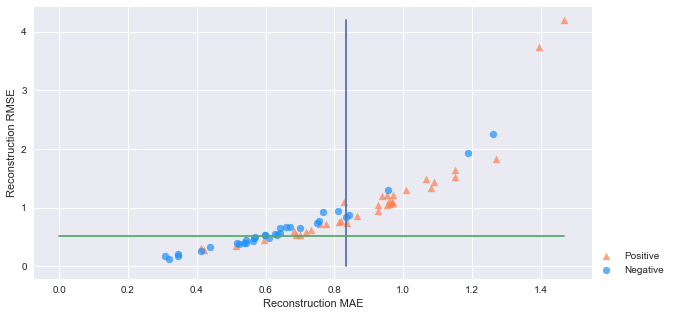
from sklearn.metrics import confusion_matrix
LABELS = ["Negative", "Positive"]
conf_matrix = confusion_matrix(mse_df['targets_names'], mse_df['msae_y_pred'])
plt.figure(figsize=(12, 12))
sns.heatmap(conf_matrix, xticklabels=LABELS, yticklabels=LABELS, annot=True, fmt="d");
plt.title("Confusion matrix")
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.show()