與上禮拜那篇文章一樣,只是這次將資料改為CRE data,希望也有良好的表現。
1. 讀入資料
import pandas as pd
import numpy as np
from sklearn import datasets
# import some data to play with
df = pd.read_csv('C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/NSYSU/fu_chung/bacterial/123.csv')
x = df.iloc[:,0:1471]
y = pd.DataFrame(df['CRE'])impor = pd.read_csv('C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/NSYSU/fu_chung/bacterial - PCA/A.csv')
impo = np.array(impor['names'])
impoarray(['V994', 'V1428', 'V1426', ..., 'V1469', 'V1470', 'V1471'],
dtype=object)print(x.shape)
x.head()(95, 1471)| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | … | V1462 | V1463 | V1464 | V1465 | V1466 | V1467 | V1468 | V1469 | V1470 | V1471 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 251357.70 | 0.00 | 494285.53 | 114879.43 | 31439.26 | 0.00 | 94049.75 | 0.00 | 0.0 | 0.0 | … | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 394550.19 | 65408.65 | 2186094.75 | 137296.91 | 0.00 | 401122.91 | 350882.59 | 0.00 | 0.0 | 0.0 | … | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.00 | 129236.21 | 675608.81 | 182865.20 | 16074.49 | 0.00 | 0.00 | 49122.42 | 0.0 | 0.0 | … | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 137403.30 | 0.00 | 818021.25 | 0.00 | 0.00 | 0.00 | 0.00 | 24273.09 | 0.0 | 0.0 | … | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 377358.78 | 327564.66 | 532502.63 | 0.00 | 0.00 | 913255.00 | 0.00 | 0.00 | 0.0 | 0.0 | … | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 1471 columns
y.describe()| CRE | |
|---|---|
| count | 95.000000 |
| mean | 0.484211 |
| std | 0.502402 |
| min | 0.000000 |
| 25% | 0.000000 |
| 50% | 0.000000 |
| 75% | 1.000000 |
| max | 1.000000 |
%matplotlib inline
by_fraud = y.groupby('CRE')
by_fraud.size().plot(kind = 'bar')<matplotlib.axes._subplots.AxesSubplot at 0x1a79ebc9e80>
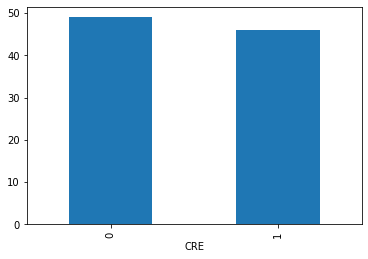
2. 建構分類器
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn import ensemble
from sklearn import metrics
import random
random.seed(1)
arr = np.arange(95)
np.random.shuffle(arr)
x = x.loc[:,impo[0:66]]
train_X = x.iloc[arr[0:67],:]
test_X = x.iloc[arr[67:95],:]
train_y = y.iloc[arr[0:67],:]
test_y = y.iloc[arr[67:95],:]
clf = AdaBoostClassifier(n_estimators=100)
#forest = ensemble.RandomForestClassifier(n_estimators = 100)
fit = clf.fit(train_X, train_y)
test_y_predicted = clf.predict(test_X)
accuracy_rf = metrics.accuracy_score(test_y, test_y_predicted)
print(accuracy_rf)1.0
C:3-gpu-packages.py:724: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel(). y = column_or_1d(y, warn=True)
3. 生成資料
f_x = x[y['CRE'].isin([1])]
f_y = y[y['CRE'].isin([1])]
print(f_x.shape)
print(f_y.shape)(46, 66) (46, 1)
f_x.head()| V994 | V1428 | V1426 | V172 | V931 | V1380 | V609 | V205 | V1232 | V1228 | … | V220 | V541 | V831 | V179 | V222 | V20 | V46 | V5 | V376 | V838 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.00 | 1771528.63 | 0.0 | 0.0 | 34648996.00 | 0.00 | 0.0 | … | 2811579.25 | 0.0 | 0.00 | 1320076.50 | 1703159.75 | 0.00 | 278172.31 | 31439.26 | 0.00 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.00 | 2974296.75 | 0.0 | 0.0 | 15947273.00 | 6531.42 | 0.0 | … | 12315243.00 | 0.0 | 101713.74 | 5010689.50 | 5576199.00 | 72396.62 | 159735.28 | 0.00 | 0.00 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.00 | 1624149.75 | 0.0 | 12143.2 | 45838852.00 | 0.00 | 0.0 | … | 3341006.50 | 0.0 | 0.00 | 1664652.63 | 988186.19 | 306535.81 | 259147.75 | 16074.49 | 0.00 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 11023.45 | 3516034.75 | 0.0 | 0.0 | 18172.75 | 0.00 | 0.0 | … | 8821420.00 | 0.0 | 0.00 | 3170263.50 | 3228012.25 | 0.00 | 0.00 | 0.00 | 16622.36 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.00 | 4416865.00 | 0.0 | 0.0 | 4918602.00 | 0.00 | 0.0 | … | 0.00 | 0.0 | 310930.25 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 25615.47 | 0.0 |
5 rows × 66 columns
3.1 OCWGAN setting
# import modules
%matplotlib inline
import os
import random
import keras
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm_notebook as tqdm
from keras.models import Model
from keras.layers import Input, Reshape
from keras.layers.core import Dense, Activation, Dropout, Flatten
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import UpSampling1D, Conv1D
from keras.layers.advanced_activations import LeakyReLU
from keras.optimizers import Adam, SGD,RMSprop
from keras.callbacks import TensorBoard
from sklearn.preprocessing import StandardScaler
# set parameters
dim = f_x.shape[1]
num = f_x.shape[0]
g_data = f_x
# Standard Scaler
ss = StandardScaler()
g_data = pd.DataFrame(ss.fit_transform(g_data))
# wasserstein_loss
from keras import backend
# implementation of wasserstein loss
def wasserstein_loss(y_true, y_pred):
return backend.mean(y_true * y_pred)
# generator
def get_generative(G_in, dense_dim=200, out_dim= dim, lr=1e-3):
x = Dense(dense_dim)(G_in)
x = Activation('tanh')(x)
G_out = Dense(out_dim, activation='tanh')(x)
G = Model(G_in, G_out)
opt = keras.optimizers.RMSprop(lr=lr)#原先為SGD
G.compile(loss=wasserstein_loss, optimizer=opt)#原loss為binary_crossentropy
return G, G_out
G_in = Input(shape=[10])
G, G_out = get_generative(G_in)
G.summary()
# discriminator
def get_discriminative(D_in, lr=1e-3, drate=.25, n_channels= dim, conv_sz=5, leak=.2):#lr=1e-3, drate=.25, n_channels= dim, conv_sz=5, leak=.2
x = Reshape((-1, 1))(D_in)
x = Conv1D(n_channels, conv_sz, activation='relu')(x)
x = Dropout(drate)(x)
x = Flatten()(x)
x = Dense(n_channels)(x)
D_out = Dense(2, activation='linear')(x)#sigmoid
D = Model(D_in, D_out)
dopt = keras.optimizers.RMSprop(lr=lr)#原先為Adam
D.compile(loss=wasserstein_loss, optimizer=dopt)
return D, D_out
D_in = Input(shape=[dim])
D, D_out = get_discriminative(D_in)
D.summary()
# set up gan
def set_trainability(model, trainable=False):
model.trainable = trainable
for layer in model.layers:
layer.trainable = trainable
def make_gan(GAN_in, G, D):
set_trainability(D, False)
x = G(GAN_in)
GAN_out = D(x)
GAN = Model(GAN_in, GAN_out)
GAN.compile(loss=wasserstein_loss, optimizer=G.optimizer)#元loss為binary_crossentropy
return GAN, GAN_out
GAN_in = Input([10])
GAN, GAN_out = make_gan(GAN_in, G, D)
GAN.summary()
# pre train
def sample_data_and_gen(G, noise_dim=10, n_samples= num):
XT = np.array(g_data)
XN_noise = np.random.uniform(0, 1, size=[n_samples, noise_dim])
XN = G.predict(XN_noise)
X = np.concatenate((XT, XN))
y = np.zeros((2*n_samples, 2))
y[:n_samples, 1] = 1
y[n_samples:, 0] = 1
return X, y
def pretrain(G, D, noise_dim=10, n_samples = num, batch_size=32):
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
D.fit(X, y, epochs=1, batch_size=batch_size)
pretrain(G, D)
def sample_noise(G, noise_dim=10, n_samples=num):
X = np.random.uniform(0, 1, size=[n_samples, noise_dim])
y = np.zeros((n_samples, 2))
y[:, 1] = 1
return X, y
# one class detector
def oneclass(data,kernel = 'rbf',gamma = 'auto'):
num1 = int(len(data)/2)
num2 = int(len(data)+1)
from sklearn import svm
clf = svm.OneClassSVM(kernel=kernel, gamma=gamma).fit(data[0:num1])
origin = pd.DataFrame(clf.score_samples(data[0:num1]))
new = pd.DataFrame(clf.score_samples(data[num1:num2]))
occ = pd.concat([pd.DataFrame(new[0] < origin[0].min()),pd.DataFrame(new[0] > origin[0].max())], axis=1)
occ['ava'] = pd.DataFrame(occ.iloc[:,1:2] == occ.iloc[:,0:1])
err = sum(occ['ava'] == False)/len(occ['ava'])
return err
# productor
def gen(GAN, G, D, times=50, n_samples= num, noise_dim=10, batch_size=32, verbose=False, v_freq=dim,):
data = pd.DataFrame()
for epoch in range(times):
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
xx,yy = X,y
err = oneclass(xx)
num1 = int(len(xx)/2)
num2 = int(len(xx)+1)
xx = ss.inverse_transform(xx)
data = pd.concat([data,pd.DataFrame(xx[num1:num2])],axis = 0)
print("The %d times generator one class svm Error Rate=%f" %(epoch, err))
return data
# training
def train(GAN, G, D, epochs=1, n_samples= num, noise_dim=10, batch_size=32, verbose=False, v_freq=dim,):
d_loss = []
g_loss = []
e_range = range(epochs)
if verbose:
e_range = tqdm(e_range)
for epoch in e_range:
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
d_loss.append(D.train_on_batch(X, y))
xx,yy = X,y
err = oneclass(xx)
print("The %d times epoch one class svm Error Rate=%f" %(epoch, err))
X, y = sample_noise(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, False)
g_loss.append(GAN.train_on_batch(X, y))
if verbose and (epoch + 1) % v_freq == 0:
print("Epoch #{}: Generative Loss: {}, Discriminative Loss: {}".format(epoch + 1, g_loss[-1], d_loss[-1]))
return d_loss, g_loss, xx, yyUsing TensorFlow backend.
WARNING:tensorflow:From C:3-gpu-packages_backend.py:74: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From C:3-gpu-packages_backend.py:517: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
WARNING:tensorflow:From C:3-gpu-packages_backend.py:4138: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
WARNING:tensorflow:From C:3-gpu-packages.py:790: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 10) 0
_________________________________________________________________
dense_1 (Dense) (None, 200) 2200
_________________________________________________________________
activation_1 (Activation) (None, 200) 0
_________________________________________________________________
dense_2 (Dense) (None, 66) 13266
=================================================================
Total params: 15,466
Trainable params: 15,466
Non-trainable params: 0
_________________________________________________________________
WARNING:tensorflow:From C:3-gpu-packages_backend.py:133: The name tf.placeholder_with_default is deprecated. Please use tf.compat.v1.placeholder_with_default instead.
WARNING:tensorflow:From C:3-gpu-packagesbackend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use rate instead of keep_prob. Rate should be set to rate = 1 - keep_prob.
________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 66) 0
_________________________________________________________________
reshape_1 (Reshape) (None, 66, 1) 0
_________________________________________________________________
conv1d_1 (Conv1D) (None, 62, 66) 396
_________________________________________________________________
dropout_1 (Dropout) (None, 62, 66) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 4092) 0
_________________________________________________________________
dense_3 (Dense) (None, 66) 270138
_________________________________________________________________
dense_4 (Dense) (None, 2) 134
=================================================================
Total params: 270,668
Trainable params: 270,668
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) (None, 10) 0
_________________________________________________________________
model_1 (Model) (None, 66) 15466
_________________________________________________________________
model_2 (Model) (None, 2) 270668
=================================================================
Total params: 286,134
Trainable params: 15,466
Non-trainable params: 270,668
_________________________________________________________________
WARNING:tensorflow:From C:3-gpu-packages_backend.py:2741: The name tf.Session is deprecated. Please use tf.compat.v1.Session instead.
Epoch 1/1 92/92 [==============================] - ETA: 0s - loss: 0.044 - 0s 3ms/step - loss: -1.2661
3.2 OCGAN setting
# import modules
%matplotlib inline
import os
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm_notebook as tqdm
from keras.models import Model
from keras.layers import Input, Reshape
from keras.layers.core import Dense, Activation, Dropout, Flatten
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import UpSampling1D, Conv1D
from keras.layers.advanced_activations import LeakyReLU
from keras.optimizers import Adam, SGD
from keras.callbacks import TensorBoard
from sklearn.preprocessing import StandardScaler
# set parameters
dim = f_x.shape[1]
num = f_x.shape[0]
g_data = f_x
# Standard Scaler
ss = StandardScaler()
g_data = pd.DataFrame(ss.fit_transform(g_data))
# generator
def get_generative(G_in, dense_dim=200, out_dim= dim, lr=1e-3):
x = Dense(dense_dim)(G_in)
x = Activation('tanh')(x)
G_out = Dense(out_dim, activation='tanh')(x)
G = Model(G_in, G_out)
opt = SGD(lr=lr)
G.compile(loss='binary_crossentropy', optimizer=opt)
return G, G_out
G_in = Input(shape=[10])
G, G_out = get_generative(G_in)
G.summary()
# discriminator
def get_discriminative(D_in, lr=1e-3, drate=.25, n_channels= dim, conv_sz=5, leak=.2):
x = Reshape((-1, 1))(D_in)
x = Conv1D(n_channels, conv_sz, activation='relu')(x)
x = Dropout(drate)(x)
x = Flatten()(x)
x = Dense(n_channels)(x)
D_out = Dense(2, activation='sigmoid')(x)
D = Model(D_in, D_out)
dopt = Adam(lr=lr)
D.compile(loss='binary_crossentropy', optimizer=dopt)
return D, D_out
D_in = Input(shape=[dim])
D, D_out = get_discriminative(D_in)
D.summary()
# set up gan
def set_trainability(model, trainable=False):
model.trainable = trainable
for layer in model.layers:
layer.trainable = trainable
def make_gan(GAN_in, G, D):
set_trainability(D, False)
x = G(GAN_in)
GAN_out = D(x)
GAN = Model(GAN_in, GAN_out)
GAN.compile(loss='binary_crossentropy', optimizer=G.optimizer)
return GAN, GAN_out
GAN_in = Input([10])
GAN, GAN_out = make_gan(GAN_in, G, D)
GAN.summary()
# pre train
def sample_data_and_gen(G, noise_dim=10, n_samples= num):
XT = np.array(g_data)
XN_noise = np.random.uniform(0, 1, size=[n_samples, noise_dim])
XN = G.predict(XN_noise)
X = np.concatenate((XT, XN))
y = np.zeros((2*n_samples, 2))
y[:n_samples, 1] = 1
y[n_samples:, 0] = 1
return X, y
def pretrain(G, D, noise_dim=10, n_samples = num, batch_size=32):
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
D.fit(X, y, epochs=1, batch_size=batch_size)
pretrain(G, D)
def sample_noise(G, noise_dim=10, n_samples=num):
X = np.random.uniform(0, 1, size=[n_samples, noise_dim])
y = np.zeros((n_samples, 2))
y[:, 1] = 1
return X, y
# one class detector
def oneclass(data,kernel = 'rbf',gamma = 'auto'):
num1 = int(len(data)/2)
num2 = int(len(data)+1)
from sklearn import svm
clf = svm.OneClassSVM(kernel=kernel, gamma=gamma).fit(data[0:num1])
origin = pd.DataFrame(clf.score_samples(data[0:num1]))
new = pd.DataFrame(clf.score_samples(data[num1:num2]))
occ = pd.concat([pd.DataFrame(new[0] < origin[0].min()),pd.DataFrame(new[0] > origin[0].max())], axis=1)
occ['ava'] = pd.DataFrame(occ.iloc[:,1:2] == occ.iloc[:,0:1])
err = sum(occ['ava'] == False)/len(occ['ava'])
return err
# training
def train1(GAN, G, D, epochs=1, n_samples= num, noise_dim=10, batch_size=32, verbose=False, v_freq=dim,):
d_loss = []
g_loss = []
e_range = range(epochs)
if verbose:
e_range = tqdm(e_range)
for epoch in e_range:
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
d_loss.append(D.train_on_batch(X, y))
xx,yy = X,y
err = oneclass(xx)
print("The %d times epoch one class svm Error Rate=%f" %(epoch, err))
X, y = sample_noise(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, False)
g_loss.append(GAN.train_on_batch(X, y))
if verbose and (epoch + 1) % v_freq == 0:
print("Epoch #{}: Generative Loss: {}, Discriminative Loss: {}".format(epoch + 1, g_loss[-1], d_loss[-1]))
return d_loss, g_loss, xx, yyWARNING:tensorflow:From C:3-gpu-packagesimpl.py:180: add_dispatch_support.
=================================================================
input_4 (InputLayer) (None, 10) 0
_________________________________________________________________
dense_5 (Dense) (None, 200) 2200
_________________________________________________________________
activation_2 (Activation) (None, 200) 0
_________________________________________________________________
dense_6 (Dense) (None, 66) 13266
=================================================================
Total params: 15,466
Trainable params: 15,466
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) (None, 66) 0
_________________________________________________________________
reshape_2 (Reshape) (None, 66, 1) 0
_________________________________________________________________
conv1d_2 (Conv1D) (None, 62, 66) 396
_________________________________________________________________
dropout_2 (Dropout) (None, 62, 66) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 4092) 0
_________________________________________________________________
dense_7 (Dense) (None, 66) 270138
_________________________________________________________________
dense_8 (Dense) (None, 2) 134
=================================================================
Total params: 270,668
Trainable params: 270,668
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_6 (InputLayer) (None, 10) 0
_________________________________________________________________
model_4 (Model) (None, 66) 15466
_________________________________________________________________
model_5 (Model) (None, 2) 270668
=================================================================
Total params: 286,134
Trainable params: 15,466
Non-trainable params: 270,668
_________________________________________________________________
Epoch 1/1
92/92 [==============================] - ETA: 1s - loss: 0.667 - 1s 6ms/step - loss: 0.5688
3.3 SMOTE setting
因正負樣本相差過小,且smote function為自動平衡方法,也就是說它會自動抓取正負樣本差距給予平衡,但因差距僅三樣,因此我將資料0的部分重複貼上依次,使其差距擴大至49+3 = 52,下一步驟的adaysn也採用相同的更動資料。
x0 = x[y['CRE'].isin([0])]
y0 = y[y['CRE'].isin([0])]
x0 = pd.concat([x,x0],axis = 0)
y0 = pd.concat([y,y0],axis = 0) from imblearn.over_sampling import SMOTE
smo = SMOTE()
X_smo, y_smo = smo.fit_sample(x0, y0)
X_smo = pd.DataFrame(X_smo)
y_smo = pd.DataFrame(y_smo)C:3-gpu-packages.py:724: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel(). y = column_or_1d(y, warn=True)
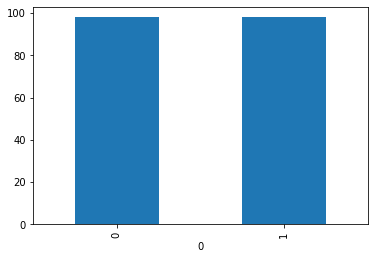
%matplotlib inline
by_fraud = y_smo.groupby(0)
by_fraud.size().plot(kind = 'bar')<matplotlib.axes._subplots.AxesSubplot at 0x1a7c68d49e8>
3. 4 ADASYN setting
from imblearn.over_sampling import ADASYN
ada = ADASYN()
X_ada, y_ada = ada.fit_sample(x0, y0)
X_ada = pd.DataFrame(X_ada)
y_ada = pd.DataFrame(y_ada)C:3-gpu-packages.py:724: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel(). y = column_or_1d(y, warn=True)
4. 比較效果
4.1 OCWGAN
ocwgan epoch 1
d_loss, g_loss ,xx,yy= train(GAN, G, D, epochs=1, verbose=True)
new_data = gen(GAN, G, D, times = 100,verbose=True)
test_y_predicted = clf.predict(new_data)
print(test_y_predicted,'acc = ',np.mean(test_y_predicted))HBox(children=(IntProgress(value=0, max=1), HTML(value=’’)))
The 0 times epoch one class svm Error Rate=1.000000
The 0 times generator one class svm Error Rate=1.000000 The 1 times generator one class svm Error Rate=1.000000 The 2 times generator one class svm Error Rate=1.000000 The 3 times generator one class svm Error Rate=1.000000 The 4 times generator one class svm Error Rate=1.000000 The 5 times generator one class svm Error Rate=1.000000 The 6 times generator one class svm Error Rate=1.000000 The 7 times generator one class svm Error Rate=1.000000 The 8 times generator one class svm Error Rate=1.000000 The 9 times generator one class svm Error Rate=1.000000 The 10 times generator one class svm Error Rate=1.000000 The 11 times generator one class svm Error Rate=1.000000 The 12 times generator one class svm Error Rate=0.978261 The 13 times generator one class svm Error Rate=1.000000 The 14 times generator one class svm Error Rate=1.000000 The 15 times generator one class svm Error Rate=0.978261 The 16 times generator one class svm Error Rate=1.000000 The 17 times generator one class svm Error Rate=1.000000 The 18 times generator one class svm Error Rate=1.000000 The 19 times generator one class svm Error Rate=0.978261 The 20 times generator one class svm Error Rate=1.000000 The 21 times generator one class svm Error Rate=1.000000 The 22 times generator one class svm Error Rate=1.000000 The 23 times generator one class svm Error Rate=1.000000 The 24 times generator one class svm Error Rate=1.000000 The 25 times generator one class svm Error Rate=0.978261 The 26 times generator one class svm Error Rate=1.000000 The 27 times generator one class svm Error Rate=1.000000 The 28 times generator one class svm Error Rate=1.000000 The 29 times generator one class svm Error Rate=0.978261 The 30 times generator one class svm Error Rate=1.000000 The 31 times generator one class svm Error Rate=0.978261 The 32 times generator one class svm Error Rate=1.000000 The 33 times generator one class svm Error Rate=1.000000 The 34 times generator one class svm Error Rate=1.000000 The 35 times generator one class svm Error Rate=1.000000 The 36 times generator one class svm Error Rate=1.000000 The 37 times generator one class svm Error Rate=1.000000 The 38 times generator one class svm Error Rate=1.000000 The 39 times generator one class svm Error Rate=0.978261 The 40 times generator one class svm Error Rate=1.000000 The 41 times generator one class svm Error Rate=1.000000 The 42 times generator one class svm Error Rate=1.000000 The 43 times generator one class svm Error Rate=1.000000 The 44 times generator one class svm Error Rate=1.000000 The 45 times generator one class svm Error Rate=1.000000 The 46 times generator one class svm Error Rate=1.000000 The 47 times generator one class svm Error Rate=1.000000 The 48 times generator one class svm Error Rate=0.978261 The 49 times generator one class svm Error Rate=1.000000 The 50 times generator one class svm Error Rate=1.000000 The 51 times generator one class svm Error Rate=1.000000 The 52 times generator one class svm Error Rate=1.000000 The 53 times generator one class svm Error Rate=1.000000 The 54 times generator one class svm Error Rate=1.000000 The 55 times generator one class svm Error Rate=1.000000 The 56 times generator one class svm Error Rate=1.000000 The 57 times generator one class svm Error Rate=1.000000 The 58 times generator one class svm Error Rate=0.978261 The 59 times generator one class svm Error Rate=1.000000 The 60 times generator one class svm Error Rate=0.956522 The 61 times generator one class svm Error Rate=1.000000 The 62 times generator one class svm Error Rate=1.000000 The 63 times generator one class svm Error Rate=1.000000 The 64 times generator one class svm Error Rate=1.000000 The 65 times generator one class svm Error Rate=1.000000 The 66 times generator one class svm Error Rate=1.000000 The 67 times generator one class svm Error Rate=1.000000 The 68 times generator one class svm Error Rate=1.000000 The 69 times generator one class svm Error Rate=1.000000 The 70 times generator one class svm Error Rate=1.000000 The 71 times generator one class svm Error Rate=1.000000 The 72 times generator one class svm Error Rate=1.000000 The 73 times generator one class svm Error Rate=1.000000 The 74 times generator one class svm Error Rate=1.000000 The 75 times generator one class svm Error Rate=0.978261 The 76 times generator one class svm Error Rate=1.000000 The 77 times generator one class svm Error Rate=1.000000 The 78 times generator one class svm Error Rate=1.000000 The 79 times generator one class svm Error Rate=1.000000 The 80 times generator one class svm Error Rate=1.000000 The 81 times generator one class svm Error Rate=1.000000 The 82 times generator one class svm Error Rate=1.000000 The 83 times generator one class svm Error Rate=1.000000 The 84 times generator one class svm Error Rate=1.000000 The 85 times generator one class svm Error Rate=0.978261 The 86 times generator one class svm Error Rate=1.000000 The 87 times generator one class svm Error Rate=1.000000 The 88 times generator one class svm Error Rate=1.000000 The 89 times generator one class svm Error Rate=1.000000 The 90 times generator one class svm Error Rate=1.000000 The 91 times generator one class svm Error Rate=1.000000 The 92 times generator one class svm Error Rate=1.000000 The 93 times generator one class svm Error Rate=0.978261 The 94 times generator one class svm Error Rate=1.000000 The 95 times generator one class svm Error Rate=1.000000 The 96 times generator one class svm Error Rate=0.978261 The 97 times generator one class svm Error Rate=1.000000 The 98 times generator one class svm Error Rate=1.000000 The 99 times generator one class svm Error Rate=0.978261 [1 1 1 … 1 1 1] acc = 1.0
ocwgan epoch 2
d_loss, g_loss ,xx,yy= train(GAN, G, D, epochs=5, verbose=True)
new_data = gen(GAN, G, D, times = 100,verbose=True)
test_y_predicted = clf.predict(new_data)
test_y_predicted
print(test_y_predicted,'acc = ',np.mean(test_y_predicted))HBox(children=(IntProgress(value=0, max=5), HTML(value=’’)))
The 0 times epoch one class svm Error Rate=1.000000 The 1 times epoch one class svm Error Rate=0.673913 The 2 times epoch one class svm Error Rate=0.217391 The 3 times epoch one class svm Error Rate=0.000000 The 4 times epoch one class svm Error Rate=0.021739
The 0 times generator one class svm Error Rate=0.000000 The 1 times generator one class svm Error Rate=0.021739 The 2 times generator one class svm Error Rate=0.000000 The 3 times generator one class svm Error Rate=0.021739 The 4 times generator one class svm Error Rate=0.021739 The 5 times generator one class svm Error Rate=0.000000 The 6 times generator one class svm Error Rate=0.000000 The 7 times generator one class svm Error Rate=0.000000 The 8 times generator one class svm Error Rate=0.021739 The 9 times generator one class svm Error Rate=0.021739 The 10 times generator one class svm Error Rate=0.000000 The 11 times generator one class svm Error Rate=0.000000 The 12 times generator one class svm Error Rate=0.000000 The 13 times generator one class svm Error Rate=0.000000 The 14 times generator one class svm Error Rate=0.000000 The 15 times generator one class svm Error Rate=0.000000 The 16 times generator one class svm Error Rate=0.021739 The 17 times generator one class svm Error Rate=0.000000 The 18 times generator one class svm Error Rate=0.000000 The 19 times generator one class svm Error Rate=0.000000 The 20 times generator one class svm Error Rate=0.000000 The 21 times generator one class svm Error Rate=0.000000 The 22 times generator one class svm Error Rate=0.000000 The 23 times generator one class svm Error Rate=0.000000 The 24 times generator one class svm Error Rate=0.000000 The 25 times generator one class svm Error Rate=0.000000 The 26 times generator one class svm Error Rate=0.000000 The 27 times generator one class svm Error Rate=0.000000 The 28 times generator one class svm Error Rate=0.021739 The 29 times generator one class svm Error Rate=0.000000 The 30 times generator one class svm Error Rate=0.021739 The 31 times generator one class svm Error Rate=0.000000 The 32 times generator one class svm Error Rate=0.000000 The 33 times generator one class svm Error Rate=0.021739 The 34 times generator one class svm Error Rate=0.000000 The 35 times generator one class svm Error Rate=0.000000 The 36 times generator one class svm Error Rate=0.000000 The 37 times generator one class svm Error Rate=0.000000 The 38 times generator one class svm Error Rate=0.000000 The 39 times generator one class svm Error Rate=0.000000 The 40 times generator one class svm Error Rate=0.000000 The 41 times generator one class svm Error Rate=0.000000 The 42 times generator one class svm Error Rate=0.000000 The 43 times generator one class svm Error Rate=0.000000 The 44 times generator one class svm Error Rate=0.000000 The 45 times generator one class svm Error Rate=0.000000 The 46 times generator one class svm Error Rate=0.000000 The 47 times generator one class svm Error Rate=0.000000 The 48 times generator one class svm Error Rate=0.000000 The 49 times generator one class svm Error Rate=0.000000 The 50 times generator one class svm Error Rate=0.000000 The 51 times generator one class svm Error Rate=0.000000 The 52 times generator one class svm Error Rate=0.000000 The 53 times generator one class svm Error Rate=0.000000 The 54 times generator one class svm Error Rate=0.000000 The 55 times generator one class svm Error Rate=0.021739 The 56 times generator one class svm Error Rate=0.000000 The 57 times generator one class svm Error Rate=0.021739 The 58 times generator one class svm Error Rate=0.000000 The 59 times generator one class svm Error Rate=0.000000 The 60 times generator one class svm Error Rate=0.000000 The 61 times generator one class svm Error Rate=0.000000 The 62 times generator one class svm Error Rate=0.000000 The 63 times generator one class svm Error Rate=0.000000 The 64 times generator one class svm Error Rate=0.000000 The 65 times generator one class svm Error Rate=0.000000 The 66 times generator one class svm Error Rate=0.000000 The 67 times generator one class svm Error Rate=0.000000 The 68 times generator one class svm Error Rate=0.000000 The 69 times generator one class svm Error Rate=0.021739 The 70 times generator one class svm Error Rate=0.000000 The 71 times generator one class svm Error Rate=0.000000 The 72 times generator one class svm Error Rate=0.000000 The 73 times generator one class svm Error Rate=0.000000 The 74 times generator one class svm Error Rate=0.000000 The 75 times generator one class svm Error Rate=0.000000 The 76 times generator one class svm Error Rate=0.000000 The 77 times generator one class svm Error Rate=0.000000 The 78 times generator one class svm Error Rate=0.000000 The 79 times generator one class svm Error Rate=0.000000 The 80 times generator one class svm Error Rate=0.000000 The 81 times generator one class svm Error Rate=0.000000 The 82 times generator one class svm Error Rate=0.000000 The 83 times generator one class svm Error Rate=0.000000 The 84 times generator one class svm Error Rate=0.000000 The 85 times generator one class svm Error Rate=0.000000 The 86 times generator one class svm Error Rate=0.000000 The 87 times generator one class svm Error Rate=0.000000 The 88 times generator one class svm Error Rate=0.000000 The 89 times generator one class svm Error Rate=0.000000 The 90 times generator one class svm Error Rate=0.000000 The 91 times generator one class svm Error Rate=0.000000 The 92 times generator one class svm Error Rate=0.000000 The 93 times generator one class svm Error Rate=0.000000 The 94 times generator one class svm Error Rate=0.000000 The 95 times generator one class svm Error Rate=0.021739 The 96 times generator one class svm Error Rate=0.000000 The 97 times generator one class svm Error Rate=0.000000 The 98 times generator one class svm Error Rate=0.000000 The 99 times generator one class svm Error Rate=0.000000 [1 1 1 … 1 1 1] acc = 1.0
ocwgan epoch 3
d_loss, g_loss ,xx,yy= train(GAN, G, D, epochs=3, verbose=True)
new_data = gen(GAN, G, D, times = 1,verbose=True)
test_y_predicted = clf.predict(new_data)
print(test_y_predicted,'acc = ',np.mean(test_y_predicted))HBox(children=(IntProgress(value=0, max=3), HTML(value=’’)))
The 0 times epoch one class svm Error Rate=0.021739 The 1 times epoch one class svm Error Rate=0.000000 The 2 times epoch one class svm Error Rate=0.000000
The 0 times generator one class svm Error Rate=0.000000 [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] acc = 1.0
4.2 OCGAN
ocgan epoch 1
d_loss, g_loss ,xx,yy= train1(GAN, G, D, epochs=1, verbose=True)
new_data = gen(GAN, G, D, times = 10,verbose=True)
test_y_predicted = clf.predict(new_data)
print(test_y_predicted,'acc = ',np.mean(test_y_predicted))HBox(children=(IntProgress(value=0, max=1), HTML(value=’’)))
The 0 times epoch one class svm Error Rate=1.000000
The 0 times generator one class svm Error Rate=1.000000 The 1 times generator one class svm Error Rate=1.000000 The 2 times generator one class svm Error Rate=1.000000 The 3 times generator one class svm Error Rate=1.000000 The 4 times generator one class svm Error Rate=1.000000 The 5 times generator one class svm Error Rate=1.000000 The 6 times generator one class svm Error Rate=1.000000 The 7 times generator one class svm Error Rate=1.000000 The 8 times generator one class svm Error Rate=1.000000 The 9 times generator one class svm Error Rate=1.000000 [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] acc = 1.0
ocgan epoch 2
d_loss, g_loss ,xx,yy= train1(GAN, G, D, epochs=100, verbose=True)
new_data = gen(GAN, G, D, times = 10,verbose=True)
test_y_predicted = clf.predict(new_data)
print(test_y_predicted,'error = ',np.mean(test_y_predicted))HBox(children=(IntProgress(value=0), HTML(value=’’)))
The 0 times epoch one class svm Error Rate=1.000000 The 1 times epoch one class svm Error Rate=1.000000 The 2 times epoch one class svm Error Rate=1.000000 The 3 times epoch one class svm Error Rate=1.000000 The 4 times epoch one class svm Error Rate=1.000000 The 5 times epoch one class svm Error Rate=1.000000 The 6 times epoch one class svm Error Rate=1.000000 The 7 times epoch one class svm Error Rate=1.000000 The 8 times epoch one class svm Error Rate=1.000000 The 9 times epoch one class svm Error Rate=1.000000 The 10 times epoch one class svm Error Rate=1.000000 The 11 times epoch one class svm Error Rate=1.000000 The 12 times epoch one class svm Error Rate=1.000000 The 13 times epoch one class svm Error Rate=1.000000 The 14 times epoch one class svm Error Rate=1.000000 The 15 times epoch one class svm Error Rate=1.000000 The 16 times epoch one class svm Error Rate=1.000000 The 17 times epoch one class svm Error Rate=1.000000 The 18 times epoch one class svm Error Rate=1.000000 The 19 times epoch one class svm Error Rate=1.000000 The 20 times epoch one class svm Error Rate=1.000000 The 21 times epoch one class svm Error Rate=1.000000 The 22 times epoch one class svm Error Rate=1.000000 The 23 times epoch one class svm Error Rate=1.000000 The 24 times epoch one class svm Error Rate=1.000000 The 25 times epoch one class svm Error Rate=1.000000 The 26 times epoch one class svm Error Rate=1.000000 The 27 times epoch one class svm Error Rate=1.000000 The 28 times epoch one class svm Error Rate=1.000000 The 29 times epoch one class svm Error Rate=1.000000 The 30 times epoch one class svm Error Rate=1.000000 The 31 times epoch one class svm Error Rate=1.000000 The 32 times epoch one class svm Error Rate=1.000000 The 33 times epoch one class svm Error Rate=1.000000 The 34 times epoch one class svm Error Rate=1.000000 The 35 times epoch one class svm Error Rate=1.000000 The 36 times epoch one class svm Error Rate=1.000000 The 37 times epoch one class svm Error Rate=1.000000 The 38 times epoch one class svm Error Rate=1.000000 The 39 times epoch one class svm Error Rate=1.000000 The 40 times epoch one class svm Error Rate=1.000000 The 41 times epoch one class svm Error Rate=1.000000 The 42 times epoch one class svm Error Rate=1.000000 The 43 times epoch one class svm Error Rate=1.000000 The 44 times epoch one class svm Error Rate=1.000000 The 45 times epoch one class svm Error Rate=1.000000 The 46 times epoch one class svm Error Rate=1.000000 The 47 times epoch one class svm Error Rate=1.000000 The 48 times epoch one class svm Error Rate=1.000000 The 49 times epoch one class svm Error Rate=1.000000 The 50 times epoch one class svm Error Rate=1.000000 The 51 times epoch one class svm Error Rate=1.000000 The 52 times epoch one class svm Error Rate=1.000000 The 53 times epoch one class svm Error Rate=1.000000 The 54 times epoch one class svm Error Rate=1.000000 The 55 times epoch one class svm Error Rate=1.000000 The 56 times epoch one class svm Error Rate=1.000000 The 57 times epoch one class svm Error Rate=1.000000 The 58 times epoch one class svm Error Rate=1.000000 The 59 times epoch one class svm Error Rate=1.000000 The 60 times epoch one class svm Error Rate=1.000000 The 61 times epoch one class svm Error Rate=1.000000 The 62 times epoch one class svm Error Rate=1.000000 The 63 times epoch one class svm Error Rate=1.000000 The 64 times epoch one class svm Error Rate=1.000000 The 65 times epoch one class svm Error Rate=1.000000 Epoch #66: Generative Loss: 4.731652736663818, Discriminative Loss: 0.021196838468313217 The 66 times epoch one class svm Error Rate=1.000000 The 67 times epoch one class svm Error Rate=1.000000 The 68 times epoch one class svm Error Rate=1.000000 The 69 times epoch one class svm Error Rate=1.000000 The 70 times epoch one class svm Error Rate=1.000000 The 71 times epoch one class svm Error Rate=1.000000 The 72 times epoch one class svm Error Rate=1.000000 The 73 times epoch one class svm Error Rate=1.000000 The 74 times epoch one class svm Error Rate=1.000000 The 75 times epoch one class svm Error Rate=1.000000 The 76 times epoch one class svm Error Rate=1.000000 The 77 times epoch one class svm Error Rate=1.000000 The 78 times epoch one class svm Error Rate=1.000000 The 79 times epoch one class svm Error Rate=1.000000 The 80 times epoch one class svm Error Rate=1.000000 The 81 times epoch one class svm Error Rate=1.000000 The 82 times epoch one class svm Error Rate=1.000000 The 83 times epoch one class svm Error Rate=0.978261 The 84 times epoch one class svm Error Rate=0.913043 The 85 times epoch one class svm Error Rate=0.934783 The 86 times epoch one class svm Error Rate=0.869565 The 87 times epoch one class svm Error Rate=0.782609 The 88 times epoch one class svm Error Rate=0.782609 The 89 times epoch one class svm Error Rate=0.673913 The 90 times epoch one class svm Error Rate=0.478261 The 91 times epoch one class svm Error Rate=0.478261 The 92 times epoch one class svm Error Rate=0.347826 The 93 times epoch one class svm Error Rate=0.521739 The 94 times epoch one class svm Error Rate=0.152174 The 95 times epoch one class svm Error Rate=0.217391 The 96 times epoch one class svm Error Rate=0.195652 The 97 times epoch one class svm Error Rate=0.130435 The 98 times epoch one class svm Error Rate=0.130435 The 99 times epoch one class svm Error Rate=0.217391
The 0 times generator one class svm Error Rate=0.043478 The 1 times generator one class svm Error Rate=0.086957 The 2 times generator one class svm Error Rate=0.043478 The 3 times generator one class svm Error Rate=0.108696 The 4 times generator one class svm Error Rate=0.108696 The 5 times generator one class svm Error Rate=0.021739 The 6 times generator one class svm Error Rate=0.065217 The 7 times generator one class svm Error Rate=0.021739 The 8 times generator one class svm Error Rate=0.086957 The 9 times generator one class svm Error Rate=0.043478 [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] error = 1.0
ocgan epoch 3
d_loss, g_loss ,xx,yy= train1(GAN, G, D, epochs=10, verbose=True)
new_data = gen(GAN, G, D, times = 10,verbose=True)
test_y_predicted = clf.predict(new_data)
print(test_y_predicted,'acc = ',np.mean(test_y_predicted))HBox(children=(IntProgress(value=0, max=10), HTML(value=’’)))
The 0 times epoch one class svm Error Rate=0.065217 The 1 times epoch one class svm Error Rate=0.152174 The 2 times epoch one class svm Error Rate=0.000000 The 3 times epoch one class svm Error Rate=0.065217 The 4 times epoch one class svm Error Rate=0.021739 The 5 times epoch one class svm Error Rate=0.021739 The 6 times epoch one class svm Error Rate=0.021739 The 7 times epoch one class svm Error Rate=0.021739 The 8 times epoch one class svm Error Rate=0.000000 The 9 times epoch one class svm Error Rate=0.000000
The 0 times generator one class svm Error Rate=0.000000 The 1 times generator one class svm Error Rate=0.000000 The 2 times generator one class svm Error Rate=0.000000 The 3 times generator one class svm Error Rate=0.021739 The 4 times generator one class svm Error Rate=0.021739 The 5 times generator one class svm Error Rate=0.000000 The 6 times generator one class svm Error Rate=0.000000 The 7 times generator one class svm Error Rate=0.000000 The 8 times generator one class svm Error Rate=0.000000 The 9 times generator one class svm Error Rate=0.000000 [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] acc = 1.0
4.3 SMOTE
new_data = X_smo.iloc[144:196,:]
test_y_predicted = clf.predict(new_data)
print(test_y_predicted)
print('acc = ',np.mean(test_y_predicted))[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] acc = 1.0
y_smo.shape(196, 1)
from sklearn import svm
oclf = svm.OneClassSVM(kernel="rbf", gamma="auto").fit(x)
origin = pd.DataFrame(oclf.score_samples(x))
new = pd.DataFrame(oclf.score_samples(new_data))
occ = pd.concat([pd.DataFrame(new[0] < origin[0].min()),pd.DataFrame(new[0] > origin[0].max())], axis=1)
occ['ava'] = pd.DataFrame(occ.iloc[:,1:2] == occ.iloc[:,0:1])
err = sum(occ['ava'] == False)/len(occ['ava'])
err1.0
4.4 ADASYN
new_data = X_ada.iloc[144:196,:]
test_y_predicted = clf.predict(new_data)
print(test_y_predicted)
print('acc = ',np.mean(test_y_predicted))[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1] acc = 0.9615384615384616
from sklearn import svm
oclf = svm.OneClassSVM(kernel="rbf", gamma="auto").fit(x)
origin = pd.DataFrame(oclf.score_samples(x))
new = pd.DataFrame(oclf.score_samples(new_data))
occ = pd.concat([pd.DataFrame(new[0] < origin[0].min()),pd.DataFrame(new[0] > origin[0].max())], axis=1)
occ['ava'] = pd.DataFrame(occ.iloc[:,1:2] == occ.iloc[:,0:1])
err = sum(occ['ava'] == False)/len(occ['ava'])
err1.0
結論上來看,gan與smote的補植也皆為正確模擬樣本,而adaysn的效果則來的比較偏移一些。