上次在挑選變數並建立分類模型的loocv時(link :https://hermitlin.netlify.com/post/2020/02/14/cre-features-selection/) ,最高的準確率來自adaboost的結果,且落在使用60~70個randomforest importance的變數,但當時多個模型準確率為0.989473684,即存在一個樣本預測錯誤,因此想知道是否在這些模型中,預測錯誤的皆為同一筆樣本。本次將預測的結果先行挑出,並將錯誤的樣本index建立成表,以方便觀察多為那些樣本為容易預測失敗的樣本。
Part1. Import the data and R’S randomforest importance
先讀入資料與之前R的importance結果:
import pandas as pd
import numpy as np
df = pd.read_csv('C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/NSYSU/fu_chung/bacterial/123.csv')impor = pd.read_csv('C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/NSYSU/fu_chung/bacterial - PCA/A.csv')
impo = np.array(impor['names'])
impoarray(['V994', 'V1428', 'V1426', ..., 'V1469', 'V1470', 'V1471'],
dtype=object)Part2. Classifiers Building
建立此次會用到adaboost的function,並加入找出預測錯誤樣本index的code:
※測試尋找index的code
bbc = [1,2,3,4,5,6,7,9,8,1]
bbc.index(1)
[i for i,v in enumerate(bbc) if v==1][0, 9]#ADABOOST
def adaloocv(ldf):
ldf = ldf.reset_index(drop=True)
cv = []
for i in range(len(ldf)):
dtrain = ldf.drop([i])
dtest = ldf.iloc[i:i+1,:]
train_X = dtrain.iloc[:,0:ldf.shape[1]-1]
test_X = dtest.iloc[:,0:ldf.shape[1]-1]
train_y = dtrain["CRE"]
test_y = dtest["CRE"]
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostClassifier(n_estimators=100)
clf_fit = clf.fit(train_X, train_y)
test_y_predicted = clf.predict(test_X)
accuracy_rf = metrics.accuracy_score(test_y, test_y_predicted)
cv += [accuracy_rf]
loocv = np.mean(cv)
av = [i for i,v in enumerate(cv) if v==0]
return "adaboost",sum(cv),loocv,sum(cv[0:46]),sum(cv[46:95]),sum(cv[0:46])/46,sum(cv[46:95])/49,avPart 3. Processing
這次使用的變數個數為前51個至前151個importances,執行並畫出統計圖表:
#ADABOOST
import time
import sys
lada = []
for i in range (100):
ldf = df.loc[:,impo[0:51+i]]
ldf['CRE'] = df['CRE']
lada += [adaloocv(ldf)]
sys.stdout.write('\r')
sys.stdout.write("[%-50s] %d%%" % ('='*i, (100/(100-1))*i))
sys.stdout.flush()
time.sleep(0.00000000000001)[================================================] 100%data = pd.DataFrame(lada)
data| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [12, 33, 35, 41] |
| 1 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [12, 33, 35, 41] |
| 2 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [12, 33, 35, 41] |
| 3 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [12, 33, 35] |
| 4 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [12, 33, 35] |
| 5 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [12, 33, 35, 41] |
| 6 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [12, 33, 35, 41] |
| 7 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [12, 33, 35] |
| 8 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [33, 35, 38] |
| 9 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [12, 33, 35, 38] |
| 10 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [11, 12, 33, 35] |
| 11 | adaboost | 91.0 | 0.957895 | 43.0 | 48.0 | 0.934783 | 0.979592 | [12, 33, 35, 82] |
| 12 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [12, 33, 35] |
| 13 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [12, 33, 35] |
| 14 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [12, 33, 35] |
| 15 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [12, 33, 35] |
| 16 | adaboost | 94.0 | 0.989474 | 45.0 | 49.0 | 0.978261 | 1.000000 | [35] |
| 17 | adaboost | 94.0 | 0.989474 | 45.0 | 49.0 | 0.978261 | 1.000000 | [35] |
| 18 | adaboost | 94.0 | 0.989474 | 45.0 | 49.0 | 0.978261 | 1.000000 | [35] |
| 19 | adaboost | 94.0 | 0.989474 | 45.0 | 49.0 | 0.978261 | 1.000000 | [35] |
| 20 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [33, 35] |
| 21 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [33, 35] |
| 22 | adaboost | 94.0 | 0.989474 | 45.0 | 49.0 | 0.978261 | 1.000000 | [35] |
| 23 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [12, 35, 41] |
| 24 | adaboost | 94.0 | 0.989474 | 45.0 | 49.0 | 0.978261 | 1.000000 | [35] |
| 25 | adaboost | 92.0 | 0.968421 | 44.0 | 48.0 | 0.956522 | 0.979592 | [35, 41, 82] |
| 26 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [33, 35, 41, 43] |
| 27 | adaboost | 91.0 | 0.957895 | 43.0 | 48.0 | 0.934783 | 0.979592 | [35, 41, 43, 59] |
| 28 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [12, 33, 35, 41] |
| 29 | adaboost | 91.0 | 0.957895 | 42.0 | 49.0 | 0.913043 | 1.000000 | [12, 33, 35, 41] |
| … | … | … | … | … | … | … | … | … |
| 70 | adaboost | 94.0 | 0.989474 | 45.0 | 49.0 | 0.978261 | 1.000000 | [35] |
| 71 | adaboost | 94.0 | 0.989474 | 45.0 | 49.0 | 0.978261 | 1.000000 | [35] |
| 72 | adaboost | 92.0 | 0.968421 | 45.0 | 47.0 | 0.978261 | 0.959184 | [35, 58, 59] |
| 73 | adaboost | 92.0 | 0.968421 | 45.0 | 47.0 | 0.978261 | 0.959184 | [35, 58, 59] |
| 74 | adaboost | 92.0 | 0.968421 | 45.0 | 47.0 | 0.978261 | 0.959184 | [35, 58, 59] |
| 75 | adaboost | 92.0 | 0.968421 | 45.0 | 47.0 | 0.978261 | 0.959184 | [35, 58, 59] |
| 76 | adaboost | 90.0 | 0.947368 | 43.0 | 47.0 | 0.934783 | 0.959184 | [35, 41, 43, 58, 59] |
| 77 | adaboost | 90.0 | 0.947368 | 43.0 | 47.0 | 0.934783 | 0.959184 | [35, 41, 43, 58, 59] |
| 78 | adaboost | 92.0 | 0.968421 | 44.0 | 48.0 | 0.956522 | 0.979592 | [35, 43, 58] |
| 79 | adaboost | 92.0 | 0.968421 | 44.0 | 48.0 | 0.956522 | 0.979592 | [35, 43, 59] |
| 80 | adaboost | 92.0 | 0.968421 | 44.0 | 48.0 | 0.956522 | 0.979592 | [35, 43, 59] |
| 81 | adaboost | 92.0 | 0.968421 | 44.0 | 48.0 | 0.956522 | 0.979592 | [35, 43, 59] |
| 82 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 83 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 84 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 85 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 86 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 87 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 88 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 89 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 90 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 91 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 92 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [35, 43] |
| 93 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [33, 35, 43] |
| 94 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [33, 35, 43] |
| 95 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [33, 35, 43] |
| 96 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [33, 35, 43] |
| 97 | adaboost | 92.0 | 0.968421 | 43.0 | 49.0 | 0.934783 | 1.000000 | [33, 35, 43] |
| 98 | adaboost | 93.0 | 0.978947 | 44.0 | 49.0 | 0.956522 | 1.000000 | [33, 35] |
| 99 | adaboost | 92.0 | 0.968421 | 44.0 | 48.0 | 0.956522 | 0.979592 | [33, 35, 84] |
100 rows × 8 columns
將wrong index的值做list並串接:
c = data.iloc[:,7:8]
c1 = []
for i in range(100):
c1 = c1+c[7][i]
c1[12, 33, 35, 41, 12, 33, 35, 41, 12, 33, 35, 41, 12, 33, 35, 12, 33, 35, 12, 33, 35, 41, 12, 33, 35, 41, 12, 33, 35, 33, 35, 38, 12, 33, 35, 38, 11, 12, 33, 35, 12, 33, 35, 82, 12, 33, 35, 12, 33, 35, 12, 33, 35, 12, 33, 35, 35, 35, 35, 35, 33, 35, 33, 35, 35, 12, 35, 41, 35, 35, 41, 82, 33, 35, 41, 43, 35, 41, 43, 59, 12, 33, 35, 41, 12, 33, 35, 41, 12, 33, 35, 41, 43, 33, 35, 43, 12, 33, 35, 43, 12, 33, 35, 43, 12, 33, 35, 43, 33, 35, 43, 33, 35, 43, 35, 33, 35, 41, 33, 35, 41, 33, 35, 41, 33, 35, 41, 33, 35, 41, 35, 41, 33, 35, 41, 35, 41, 35, 41, 35, 35, 41, 35, 41, 35, 35, 41, 35, 41, 35, 41, 58, 82, 85, 58, 82, 85, 58, 82, 85, 58, 82, 85, 35, 41, 82, 35, 41, 35, 41, 35, 41, 48, 58, 85, 35, 41, 48, 58, 85, 35, 41, 48, 58, 85, 35, 41, 48, 58, 11, 35, 41, 58, 11, 35, 41, 58, 11, 35, 33, 35, 41, 33, 35, 41, 35, 35, 35, 58, 59, 35, 58, 59, 35, 58, 59, 35, 58, 59, 35, 41, 43, 58, 59, 35, 41, 43, 58, 59, 35, 43, 58, 35, 43, 59, 35, 43, 59, 35, 43, 59, 35, 43, 35, 43, 35, 43, 35, 43, 35, 43, 35, 43, 35, 43, 35, 43, 35, 43, 35, 43, 35, 43, 33, 35, 43, 33, 35, 43, 33, 35, 43, 33, 35, 43, 33, 35, 43, 33, 35, 33, 35, 84]
用dict的方式計算出現次數:
values = c1
value_cnt = {} # 將結果用一個字典存儲
for value in values:
# get(value, num)函數的作用是獲取字典中value對應的鍵值, num=0指示初始值大小。
value_cnt[value] = value_cnt.get(value, 0) + 1
# 輸出結果
print(value_cnt)
#print([key for key in value_cnt.keys()])
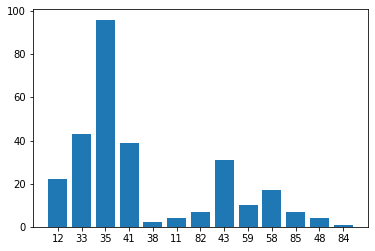
#print([value for value in value_cnt.values()]){12: 22, 33: 43, 35: 96, 41: 39, 38: 2, 11: 4, 82: 7, 43: 31, 59: 10, 58: 17, 85: 7, 48: 4, 84: 1}
使用51個到151個變數建立的預測模型中,預測樣本錯誤的次數結果為:
35出現 96次
33出現 43次
41出現 39次
43出現 31次
12出現 22次
58出現 17次
59出現 10次
82出現 7次
85出現 7次
11出現 4次
48出現 4次
38出現 2次
84出現 1次
畫出dict儲存的資料:
import matplotlib.pyplot as plt
plt.bar(range(len(value_cnt)), list(value_cnt.values()), align='center')
plt.xticks(range(len(value_cnt)), list(value_cnt.keys()))
# # for python 2.x:
# plt.bar(range(len(D)), D.values(), align='center') # python 2.x
# plt.xticks(range(len(D)), D.keys()) # in python 2.x
plt.show()