因為修統計書報的關係,這次也被分配要報告一個章節,雖然那本書是工具書取向,但是發現該作者有在2004年寫了一篇有關logistic regression的演算法,他稱之為LOTUS,主要是希望可以解決當時logistic regression的一些問題。

Logistic Regression主要優勢是在他算法快、存處資源低;缺點是如果模型存在共線性、非線性、或交互作用存在,則模型並不好解釋。
為了克服以上問題,作者提出了一種模型:LOTUS(Logistic Regression with Unbiasd Selection) 通過樹狀分割數據並且fit不同的Logistic Regression 在每個partition,因為樹狀結構包含了完整模型的描述,因此產生的模型較容易解釋。
書中提到:
LOTUS has five properties that make it desirable for analysis and interpretation of large datasets:
- negligible bias in split variable selection,
- relatively fast training speed
- applicability to quantitative and categorical variables
- choice of multiple or simple linear logistic node models, and
- suitability for datasets with missing values.
————————————————————————————————————————————– 書這邊有個UCI上面的荷蘭保險資料範例(data link:https://archive.ics.uci.edu/ml/datasets/Insurance+Company+Benchmark+%28COIL+2000%29 ),這邊做個簡單的資料描述:
1.5,822 筆顧客資料. 一共85個解釋變數
2.反應變數為caravan,1表示客戶擁有車輛保險
3.5,822 customers only 348 (or 6%) own caravan insurance policies.
LOTUS的呈現結果如下圖:
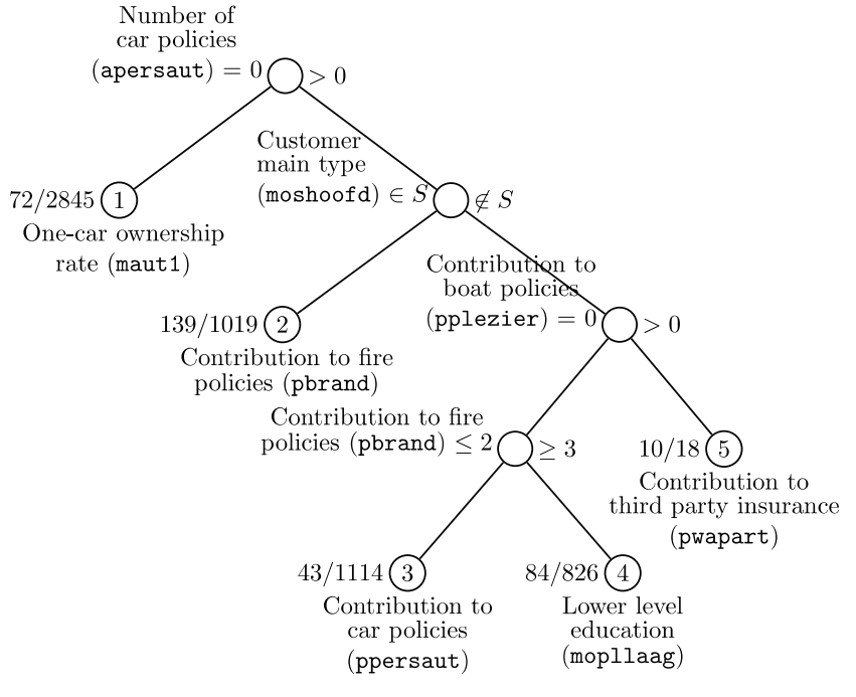
LOTUS的 terminal node logistic regression 如下圖:
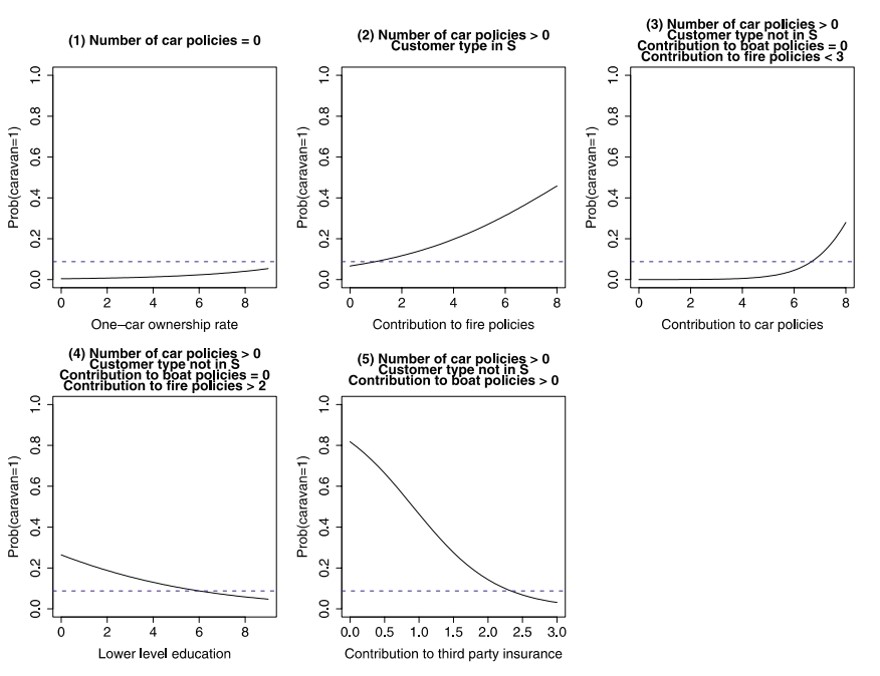
在有這棵樹的情況下,我們模型的解釋程度相對就提升了許多,因此若是需要解釋、資料存在不想處裡的遺失值等需求,則這將會是一個很好的模型選擇。