不平衡資料 (Imbalanced Data)是很常見於結構化資料的情境之一。比如說我們有一筆保險客戶的資料,有非常多的客戶基本資料(如:居住地、學歷等等),以及一個對應的反應變數:是否有投保,而這個變量有極大的可能多數為非投保狀態,這種情況就稱為Imbalanced Data,因為最近遇到這個類型的資料分析問題,因此從數篇文章中整理幾個常見的解決方法,這裡主要針對反應變數為binary classificaion的狀態。

1.常見的分類問題
因為極度不平衡的資料,將導致我們在訓練分類模型的時候 有過度去預測某一類的情況。比如說上述的保險資料,我們持有10萬筆客戶訓練資料,但僅有2000筆資料為投保情況,因此我們如果有個分類模型將所有結果預測為非投保,該模型的準確率也將高達98%,但實際上它並無法為我們做出想要的預測結果,因此這種情形之下,預測準確率將不再是個好用的指標。接下來討論一下常用於Imbalanced Data的指標。
2.常見於Imbalanced Data的指標
常看見的指標例如:ROC/AUC、F-index等等,一般來說這些指標都有一個特性,主要是將兩類的預測結果分開評分再做合併,因此可能會有準確率比較低但AUC卻比較高的模型,這種情況有人稱之為Accuracy Paradox,以AUC的計算為例,我們會使用(參考下表)
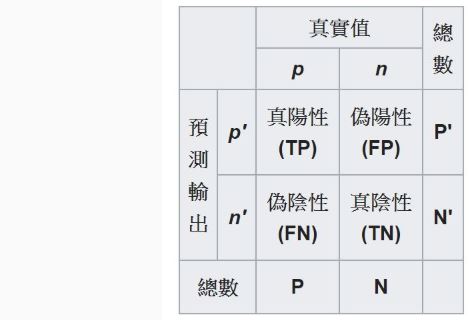
Recall = TP / (TP + FN)
Specificity = TN / (TN +FP)
來當作ROC的縱軸以及橫軸,並計算Area under the Curve of ROC
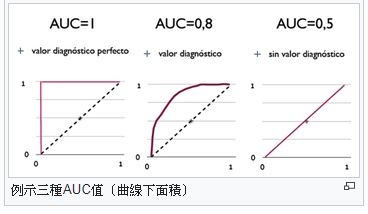
因此縱使我們有個模型將全部的預測結果皆預測為非投保
該模型的AUC也僅僅0.5,因此這種Imbalanced Data比起一般的accuracy來說,AUC可能更適合當作參考指標。
3.常見於處理Imbalanced Data的方法
主要有兩個出發的思考方向:從資料處理的方向與演算法的方向。
3.1 資料處理方法
主要有抽取樣本以及合成樣本兩大方向,常見的抽樣方法有:
●Oversampling:隨機複製陽性個體,使陽性與陰性在訓練集合的比例達到 1:1,這種方法最大的缺點是很容易讓 Specificity 下降。
●Unsersampling:隨機刪除陰性個體,使陽性與陰性在訓練集合的比例達到 1:1,這種方法最大的缺點是很容易缺失某些陰性個體的資訊。
●easy ensemble:多次Unsersampling,產生多個不同的訓練集並訓練多個不同的分類器,最後整合。
而在抽樣方法中,我們應當使用交叉驗證的方式,只有重複取樣資料可以將隨機性引入到資料集中,以確保不會出現過擬合問題。
而常見的合成樣本 (Synthetic Sample)則有:
●SMOTE / AdaSyn 等利用「最近鄰點」(Nearest Neighbors) 為出發的方法產生新資料
●利用貝氏網絡 (Bayesian Network) 產生具有相似變數結構的新資料
●GAN:利用生成與對抗模型產生相似分配的資料
3.2 演算法處理方法
●BalanceCascade演算法:先使用Unsersampling的資料訓練一個分類器,並將分類正確的陰性樣本不放回,然後放入尚未分類的樣本進入模型,並逐次調整分類器。
●One Class Learning:對於正負樣本極不平衡的場景,我們可以換一個完全不同的角度來看待問題:把它看做一分類(One Class Learning)或異常檢測(NoveltyDetection)問題。這類方法的重點不在於捕捉類間的差別,而是為其中一類進行建模,經典的工作包括One-class SVM等。藉由調整SVM以懲罰稀有類別的錯誤分類。
●Cost-sensitive Classification:將一般機器學習的損失函數 (loss function) 改為成本導向的損失函數。舉個常見的AdaCost演算法,憶Adaboost演算法是通過反覆迭代,根據當前分類器的表現更新樣本的權重,其策略為正確分類樣本權重降低,錯誤分類樣本權重加大,最終的模型是多次迭代模型的一個加權線性組合,分類越準確的分類器將會獲得越大的權重。而AdaCost演算法修改了Adaboost演算法的權重更新策略,其基本思想是對於代價高的誤分類樣本大大地提高其權重,而對於代價高的正確分類樣本適當地降低其權重,使其權重降低相對較小。總體思想是代價高樣本權重增加得大降低得慢。