我會在這次使用R-package:“rvest”來執行網路爬蟲。
這次要爬取的網站: https://heavenlyfood.cn/books/menu.php?id=2021 (国度的操练为着教会的建造)
這個網頁是用簡體中文寫的,所以我會將最後輸出的語言轉換為繁體中文。
我將使用R-package:“ropencc”來完成這項工作,它可以在Github上下載“ropencc”。
最後後將章節的故事輸出到每個txt文本文件,並且以章節名稱為檔案命名。
Link the website
if (!require(rvest))install.packages("rvest")
library(rvest)
if (!require(ropencc))devtools::install_github("qinwf/ropencc")
library(ropencc)
#read the html
bible <- read_html("https://heavenlyfood.cn/books/menu.php?id=2021")
#get the title
bible_title <- html_nodes(bible,"#title")
title <- html_text(bible_title)
title <- title[2:9]
trans <- converter(S2TWP)
title <- run_convert(trans, title) #trans simple chinese to traditional chinese
#get the chapter's url
url <- html_nodes(bible,"div a")
url <- data.frame(html_attr(url,"href"))
url <- t(data.frame(url[80:87,1])) #transpose the url dataContent Grabbing
for(i in c(1:length(title))){
#link to the chapter url
chapter_url <- paste0("https://heavenlyfood.cn/", url[i])
bible1 <- read_html(chapter_url)
#grab the content
bible_cont <- html_nodes(bible1,".cont")
cont <- html_text(bible_cont,trim = TRUE)
#trans simple Chinese to traditional Chinese
cont[1] <- title[i] #name the title
cont <- run_convert(trans, cont)
#output the txt for each chapter
nam <- paste(title[i],".txt", sep=" ")
write.table(cont,nam)
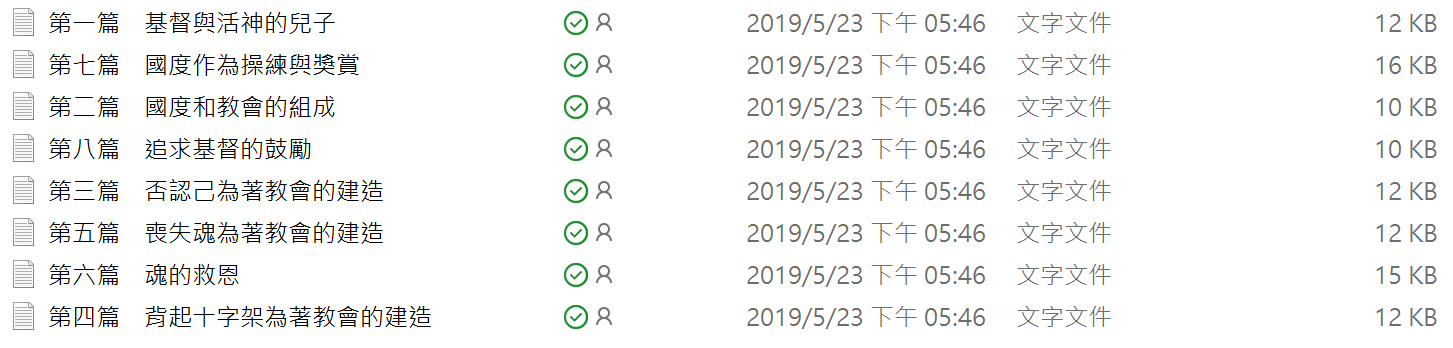
}代碼運行後將獲得八個文本文件。
結果如下: