這次使用之前分析過的CRE資料,來嘗試使用OCGAN,但因原先資料CRE:NON比數為46:49,為了達到不平衡的效果,因此最後採用16:49的比例,從46個CRE中取隨機16個,而資料的訓練集以及驗證集比例為下:
Train Set(CRE:Non): 6:19
Validation Set(CRE:Non): 10:30
接著我們將分為有使用OCGAN平衡數據集的資料以及未平衡數據集的資料進行分別建模,兩者皆使用SVM的方式建模,並且先透過LOOCV的方式在數據集Tuning模型,最後套入驗證集計算總準確率、f1 score、auc等,比較有無平衡的效果。
讀入資料
import pandas as pd
import numpy as np
df = pd.read_csv('C:/Users/User/OneDrive - student.nsysu.edu.tw/Educations/NSYSU/fu_chung/bacterial/123.csv')%matplotlib inline
by_fraud = df.groupby('CRE')
by_fraud.size().plot(kind = 'bar')<matplotlib.axes._subplots.AxesSubplot at 0x238556a6dd8>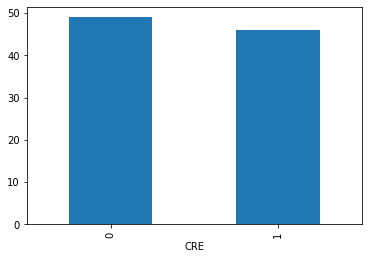
Train vs Test set
train set (0:1):20:6
test set(0:1):2.9:10
from sklearn.model_selection import train_test_split
import random
cre = df[df['CRE'].isin([1])].iloc[0:16,:]
cre['CRE'] = 1
normal = df[df['CRE'].isin([0])].iloc[:,:]
normal['CRE'] = 0
random.seed(3)
train_nor, test_nor = train_test_split(normal, test_size = 0.6)
train_cre, test_cre = train_test_split(cre, test_size = 0.6)
data_train = pd.concat([train_nor,train_cre], axis=0)
data_test = pd.concat([test_nor,test_cre], axis=0) C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\ipykernel_launcher.py:6: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
Variable Selection
這次使用Best Subsets feature selection ,因為變數大約1400個,因此運算量極大,最終挑選169個變數,並依此建立後續模型。
from sklearn.feature_selection import VarianceThreshold
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
fix_data = pd.DataFrame(sel.fit_transform(data_train))
fix_data| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | … | 1112 | 1113 | 1114 | 1115 | 1116 | 1117 | 1118 | 1119 | 1120 | 1121 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 1373136.00 | 55669.65 | 29413.53 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1849143.63 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 1 | 0.00 | 69101.06 | 3312204.50 | 43936.20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 2 | 0.00 | 55406.89 | 37459.26 | 567906.94 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 3 | 0.00 | 0.00 | 0.00 | 574.92 | 2521.91 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 4 | 0.00 | 2209497.50 | 0.00 | 332850.19 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 88801.86 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 5 | 0.00 | 0.00 | 386523.69 | 19751.14 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 474353.41 | … | 98261.75 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 445534.22 | 57997.06 | 123774.34 | 0.0 |
| 6 | 0.00 | 410000.25 | 0.00 | 3239424.25 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 7 | 0.00 | 0.00 | 22582.54 | 275360.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 8 | 0.00 | 1656135.25 | 578440.81 | 444822.34 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 835118.25 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 9 | 0.00 | 7308348.00 | 0.00 | 428864.38 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 267987.5 | 25078.88 | 143299.28 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 10 | 0.00 | 6349.39 | 44542.15 | 12410.13 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 509739.94 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 11 | 0.00 | 0.00 | 8855.12 | 617930.44 | 0.00 | 4434.14 | 535930.94 | 355806.91 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 12 | 0.00 | 77937.30 | 42382.20 | 5088.32 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 13 | 0.00 | 510357.69 | 8396.52 | 76988.38 | 0.00 | 0.00 | 81731.96 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 14 | 0.00 | 0.00 | 0.00 | 1980458.38 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 15 | 0.00 | 43712.79 | 0.00 | 9753.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 16 | 0.00 | 13922.24 | 0.00 | 19162.79 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 4851091.5 | 0.0 | 0.00 | 0.00 | 1199.36 | 0.00 | 0.00 | 0.00 | 0.0 |
| 17 | 0.00 | 7889.80 | 215028.61 | 10020.09 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 18 | 0.00 | 1614557.63 | 234533.52 | 496465.50 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 |
| 19 | 0.00 | 237456.30 | 489450.28 | 317787.66 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.0 |
| 20 | 850345.94 | 0.00 | 1142041.75 | 0.00 | 22913.52 | 83391.35 | 132192.95 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.0 |
| 21 | 0.00 | 60298.57 | 242256.88 | 0.00 | 0.00 | 0.00 | 28529.95 | 0.00 | 577876.63 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.0 |
| 22 | 404748.19 | 97165.77 | 800137.44 | 134355.13 | 0.00 | 285973.69 | 152992.25 | 0.00 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.0 |
| 23 | 458382.13 | 136389.20 | 412460.16 | 294669.03 | 46850.84 | 470360.91 | 70784.13 | 52197.92 | 0.00 | 0.00 | … | 0.00 | 0.0 | 0.0 | 3268253.75 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.0 |
| 24 | 0.00 | 0.00 | 39572.38 | 102085.48 | 0.00 | 0.00 | 0.00 | 0.00 | 37461.19 | 0.00 | … | 0.00 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.0 |
25 rows × 1122 columns
from sklearn.datasets import load_boston
import pandas as pd
import numpy as np
import statsmodels.api as sm
def stepwise_selection(X, y,
initial_list=[],
threshold_in=0.01,
threshold_out = 0.05,
verbose=True):
""" Perform a forward-backward feature selection
based on p-value from statsmodels.api.OLS
Arguments:
X - pandas.DataFrame with candidate features
y - list-like with the target
initial_list - list of features to start with (column names of X)
threshold_in - include a feature if its p-value < threshold_in
threshold_out - exclude a feature if its p-value > threshold_out
verbose - whether to print the sequence of inclusions and exclusions
Returns: list of selected features
Always set threshold_in < threshold_out to avoid infinite looping.
See https://en.wikipedia.org/wiki/Stepwise_regression for the details
"""
included = list(initial_list)
while True:
changed=False
# forward step
excluded = list(set(X.columns)-set(included))
new_pval = pd.Series(index=excluded)
for new_column in excluded:
model = sm.OLS(y, sm.add_constant(pd.DataFrame(X[included+[new_column]]))).fit()
new_pval[new_column] = model.pvalues[new_column]
best_pval = new_pval.min()
if best_pval < threshold_in:
best_feature = new_pval.argmin()
included.append(best_feature)
changed=True
if verbose:
print('Add {:30} with p-value {:.6}'.format(best_feature, best_pval))
# backward step
model = sm.OLS(y, sm.add_constant(pd.DataFrame(X[included]))).fit()
# use all coefs except intercept
pvalues = model.pvalues.iloc[1:]
worst_pval = pvalues.max() # null if pvalues is empty
if worst_pval > threshold_out:
changed=True
worst_feature = pvalues.argmax()
included.remove(worst_feature)
if verbose:
print('Drop {:30} with p-value {:.6}'.format(worst_feature, worst_pval))
if not changed:
break
return includedX = data_train.iloc[:,0:1471]
y = data_train.iloc[:,1471:1472]
result = stepwise_selection(X, y)
print('resulting features:')
result[‘V993’, ‘V322’, ‘V864’, ‘V689’, ‘V598’, ‘V1156’, ‘V240’, ‘V395’, ‘V1255’, ‘V1218’, ‘V634’, ‘V529’, ‘V869’, ‘V410’, ‘V521’, ‘V32’, ‘V1201’, ‘V478’, ‘V306’, ‘V964’, ‘V1122’, ‘V485’, ‘V690’, ‘V947’, ‘V677’, ‘V1444’, ‘V832’, ‘V1’, ‘V517’, ‘V351’, ‘V9’, ‘V109’, ‘V872’, ‘V518’, ‘V1239’, ‘V270’, ‘V695’, ‘V147’, ‘V524’, ‘V679’, ‘V320’, ‘V356’, ‘V232’, ‘V687’, ‘V112’, ‘V983’, ‘V146’, ‘V345’, ‘V520’, ‘V198’, ‘V59’, ‘V408’, ‘V110’, ‘V250’, ‘V1275’, ‘V60’, ‘V1253’, ‘V459’, ‘V522’, ‘V889’, ‘V403’, ‘V269’, ‘V87’, ‘V530’, ‘V839’, ‘V399’, ‘V861’, ‘V242’, ‘V823’, ‘V58’, ‘V627’, ‘V84’, ‘V321’, ‘V50’, ‘V483’, ‘V475’, ‘V1396’, ‘V1411’, ‘V1285’, ‘V1093’, ‘V1378’, ‘V413’, ‘V525’, ‘V671’, ‘V30’, ‘V95’, ‘V1199’, ‘V767’, ‘V809’, ‘V1404’, ‘V1401’, ‘V113’, ‘V1198’, ‘V1405’, ‘V1398’, ‘V1209’, ‘V1407’, ‘V1352’, ‘V271’, ‘V528’, ‘V805’, ‘V1397’, ‘V753’, ‘V200’, ‘V1400’, ‘V1408’, ‘V1394’, ‘V593’, ‘V1157’, ‘V233’, ‘V268’, ‘V576’, ‘V181’, ‘V1395’, ‘V820’, ‘V1257’, ‘V514’, ‘V669’, ‘V943’, ‘V489’, ‘V937’, ‘V486’, ‘V513’, ‘V1143’, ‘V966’, ‘V980’, ‘V1274’, ‘V1403’, ‘V343’, ‘V686’, ‘V653’, ‘V1281’, ‘V234’, ‘V1279’, ‘V523’, ‘V870’, ‘V959’, ‘V1278’, ‘V871’, ‘V5’, ‘V775’, ‘V845’, ‘V1211’, ‘V1110’, ‘V1273’, ‘V995’, ‘V1276’, ‘V873’, ‘V595’, ‘V1280’, ‘V1034’, ‘V1228’, ‘V1012’, ‘V1226’, ‘V1094’, ‘V511’, ‘V944’, ‘V1068’, ‘V1146’, ‘V313’, ‘V821’, ‘V122’, ‘V1227’, ‘V386’, ‘V771’, ‘V551’, ‘V538’, ‘V1220’, ‘V1179’]
result = ['V993', 'V322', 'V864', 'V689', 'V598', 'V1156', 'V240', 'V395', 'V1255', 'V1218', 'V634', 'V529', 'V869', 'V410', 'V521', 'V32', 'V1201', 'V478', 'V306', 'V964', 'V1122', 'V485', 'V690', 'V947', 'V677', 'V1444', 'V832', 'V1', 'V517', 'V351', 'V9', 'V109', 'V872', 'V518', 'V1239', 'V270', 'V695', 'V147', 'V524', 'V679', 'V320', 'V356', 'V232', 'V687', 'V112', 'V983', 'V146', 'V345', 'V520', 'V198', 'V59', 'V408', 'V110', 'V250', 'V1275', 'V60', 'V1253', 'V459', 'V522', 'V889', 'V403', 'V269', 'V87', 'V530', 'V839', 'V399', 'V861', 'V242', 'V823', 'V58', 'V627', 'V84', 'V321', 'V50', 'V483', 'V475', 'V1396', 'V1411', 'V1285', 'V1093', 'V1378', 'V413', 'V525', 'V671', 'V30', 'V95', 'V1199', 'V767', 'V809', 'V1404', 'V1401', 'V113', 'V1198', 'V1405', 'V1398', 'V1209', 'V1407', 'V1352', 'V271', 'V528', 'V805', 'V1397', 'V753', 'V200', 'V1400', 'V1408', 'V1394', 'V593', 'V1157', 'V233', 'V268', 'V576', 'V181', 'V1395', 'V820', 'V1257', 'V514', 'V669', 'V943', 'V489', 'V937', 'V486', 'V513', 'V1143', 'V966', 'V980', 'V1274', 'V1403', 'V343', 'V686', 'V653', 'V1281', 'V234', 'V1279', 'V523', 'V870', 'V959', 'V1278', 'V871', 'V5', 'V775', 'V845', 'V1211', 'V1110', 'V1273', 'V995', 'V1276', 'V873', 'V595', 'V1280', 'V1034', 'V1228', 'V1012', 'V1226', 'V1094', 'V511', 'V944', 'V1068', 'V1146', 'V313', 'V821', 'V122', 'V1227', 'V386', 'V771', 'V551', 'V538', 'V1220', 'V1179']train = data_train.loc[:,result]
test = data_test.loc[:,result]
train_X = new_data_train.iloc[:,:]
test_X = data_test.iloc[:,:]
train_y = new_data_train["CRE"]
test_y = data_test["CRE"]
d_nor = train_nor.loc[:,result]
d_cre = train_cre.loc[:,result]
d_test = pd.concat([test_nor.loc[:,result],test_cre.loc[:,result]], axis=0)non sampling
loocv
def loocv(ldf):
ldf = ldf.reset_index(drop=True)
cv = []
for i in range(len(ldf)):
dtrain = ldf.drop([i])
dtest = ldf.iloc[i:i+1,:]
train_X = dtrain.iloc[:,0:ldf.shape[1]-1]
test_X = dtest.iloc[:,0:ldf.shape[1]-1]
train_y = dtrain["CRE"]
test_y = dtest["CRE"]
clf = svm.SVC(kernel = 'linear') #SVM模組,svc,線性核函式
clf_fit = clf.fit(train_X, train_y)
test_y_predicted = clf.predict(test_X)
accuracy_rf = metrics.accuracy_score(test_y, test_y_predicted)
cv += [accuracy_rf]
loocv = np.mean(cv)
return loocvdf1 = train
df1["CRE"] = data_train["CRE"]
loocv(df1)0.96
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import ensemble
from sklearn import metrics
from sklearn import svm
train_X = train
test_X = test
train_y = data_train["CRE"]
test_y = data_test["CRE"]
#forest = ensemble.RandomForestClassifier(n_estimators = 10)
#forest_fit = forest.fit(train_X, train_y)
clf = svm.SVC(kernel = 'linear') #SVM模組,svc,線性核函式
clf_fit = clf.fit(train_X, train_y)
test_y_predicted = clf.predict(test_X)
accuracy_rf = metrics.accuracy_score(test_y, test_y_predicted)
print(accuracy_rf)
test_auc = metrics.roc_auc_score(test_y, test_y_predicted)
print (test_auc)
import sklearn
f1 = sklearn.metrics.f1_score(test_y, test_y_predicted)
print(f1)1.0
1.0
1.0
OCGAN for balance data
### import modules
%matplotlib inline
import os
import random
import keras
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm_notebook as tqdm
from keras.models import Model
from keras.layers import Input, Reshape
from keras.layers.core import Dense, Activation, Dropout, Flatten
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import UpSampling1D, Conv1D
from keras.layers.advanced_activations import LeakyReLU
from keras.optimizers import Adam, SGD,RMSprop
from keras.callbacks import TensorBoard
from sklearn.preprocessing import StandardScaler
# set parameters
dim = 169
num = 6
g_data = d_cre
# Standard Scaler
ss = StandardScaler()
g_data = pd.DataFrame(ss.fit_transform(g_data))
# wasserstein_loss
from keras import backend
# implementation of wasserstein loss
def wasserstein_loss(y_true, y_pred):
return backend.mean(y_true * y_pred)
# generator
def get_generative(G_in, dense_dim=200, out_dim= dim, lr=1e-3):
x = Dense(dense_dim)(G_in)
x = Activation('tanh')(x)
G_out = Dense(out_dim, activation='tanh')(x)
G = Model(G_in, G_out)
opt = keras.optimizers.RMSprop(lr=lr)#原先為SGD
G.compile(loss=wasserstein_loss, optimizer=opt)#原loss為binary_crossentropy
return G, G_out
G_in = Input(shape=[10])
G, G_out = get_generative(G_in)
G.summary()
# discriminator
def get_discriminative(D_in, lr=1e-3, drate=.25, n_channels= dim, conv_sz=5, leak=.2):#lr=1e-3, drate=.25, n_channels= dim, conv_sz=5, leak=.2
x = Reshape((-1, 1))(D_in)
x = Conv1D(n_channels, conv_sz, activation='relu')(x)
x = Dropout(drate)(x)
x = Flatten()(x)
x = Dense(n_channels)(x)
D_out = Dense(2, activation='linear')(x)#sigmoid
D = Model(D_in, D_out)
dopt = keras.optimizers.RMSprop(lr=lr)#原先為Adam
D.compile(loss=wasserstein_loss, optimizer=dopt)
return D, D_out
D_in = Input(shape=[dim])
D, D_out = get_discriminative(D_in)
D.summary()
# set up gan
def set_trainability(model, trainable=False):
model.trainable = trainable
for layer in model.layers:
layer.trainable = trainable
def make_gan(GAN_in, G, D):
set_trainability(D, False)
x = G(GAN_in)
GAN_out = D(x)
GAN = Model(GAN_in, GAN_out)
GAN.compile(loss=wasserstein_loss, optimizer=G.optimizer)#元loss為binary_crossentropy
return GAN, GAN_out
GAN_in = Input([10])
GAN, GAN_out = make_gan(GAN_in, G, D)
GAN.summary()
# pre train
def sample_data_and_gen(G, noise_dim=10, n_samples= num):
XT = np.array(g_data)
XN_noise = np.random.uniform(0, 1, size=[n_samples, noise_dim])
XN = G.predict(XN_noise)
X = np.concatenate((XT, XN))
y = np.zeros((2*n_samples, 2))
y[:n_samples, 1] = 1
y[n_samples:, 0] = 1
return X, y
def pretrain(G, D, noise_dim=10, n_samples = num, batch_size=32):
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
D.fit(X, y, epochs=1, batch_size=batch_size)
pretrain(G, D)
def sample_noise(G, noise_dim=10, n_samples=num):
X = np.random.uniform(0, 1, size=[n_samples, noise_dim])
y = np.zeros((n_samples, 2))
y[:, 1] = 1
return X, y
# one class detector
def oneclass(data,kernel = 'rbf',gamma = 'auto'):
num1 = int(len(data)/2)
num2 = int(len(data)+1)
from sklearn import svm
clf = svm.OneClassSVM(kernel=kernel, gamma=gamma).fit(data[0:num1])
origin = pd.DataFrame(clf.score_samples(data[0:num1]))
new = pd.DataFrame(clf.score_samples(data[num1:num2]))
occ = pd.concat([pd.DataFrame(new[0] < origin[0].min()),pd.DataFrame(new[0] > origin[0].max())], axis=1)
occ['ava'] = pd.DataFrame(occ.iloc[:,1:2] == occ.iloc[:,0:1])
err = sum(occ['ava'] == False)/len(occ['ava'])
return err
# productor
def gen(GAN, G, D, times=50, n_samples= num, noise_dim=10, batch_size=32, verbose=False, v_freq=dim,):
data = pd.DataFrame()
for epoch in range(times):
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
xx,yy = X,y
err = oneclass(xx)
num1 = int(len(xx)/2)
num2 = int(len(xx)+1)
data = pd.concat([data,pd.DataFrame(ss.inverse_transform(xx[num1:num2]))],axis = 0)
print("The %d times generator one class svm Error Rate=%f" %(epoch, err))
return data
# training
def train(GAN, G, D, epochs=1, n_samples= num, noise_dim=10, batch_size=32, verbose=False, v_freq=dim,):
d_loss = []
g_loss = []
e_range = range(epochs)
if verbose:
e_range = tqdm(e_range)
for epoch in e_range:
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
d_loss.append(D.train_on_batch(X, y))
xx,yy = X,y
err = oneclass(xx)
print("The %d times epoch one class svm Error Rate=%f" %(epoch, err))
X, y = sample_noise(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, False)
g_loss.append(GAN.train_on_batch(X, y))
if verbose and (epoch + 1) % v_freq == 0:
print("Epoch #{}: Generative Loss: {}, Discriminative Loss: {}".format(epoch + 1, g_loss[-1], d_loss[-1]))
return d_loss, g_loss, xx, yy
d_loss, g_loss ,xx,yy= train(GAN, G, D, verbose=True)Layer (type) Output Shape Param #
=================================================================
input_22 (InputLayer) (None, 10) 0
_________________________________________________________________
dense_29 (Dense) (None, 200) 2200
_________________________________________________________________
activation_8 (Activation) (None, 200) 0
_________________________________________________________________
dense_30 (Dense) (None, 169) 33969
=================================================================
Total params: 36,169
Trainable params: 36,169
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_23 (InputLayer) (None, 169) 0
_________________________________________________________________
reshape_8 (Reshape) (None, 169, 1) 0
_________________________________________________________________
conv1d_8 (Conv1D) (None, 165, 169) 1014
_________________________________________________________________
dropout_8 (Dropout) (None, 165, 169) 0
_________________________________________________________________
flatten_8 (Flatten) (None, 27885) 0
_________________________________________________________________
dense_31 (Dense) (None, 169) 4712734
_________________________________________________________________
dense_32 (Dense) (None, 2) 340
=================================================================
Total params: 4,714,088
Trainable params: 4,714,088
Non-trainable params: 0
_________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_24 (InputLayer) (None, 10) 0
_________________________________________________________________
model_22 (Model) (None, 169) 36169
_________________________________________________________________
model_23 (Model) (None, 2) 4714088
=================================================================
Total params: 4,750,257
Trainable params: 36,169
Non-trainable params: 4,714,088
_________________________________________________________________
Epoch 1/1
12/12 [==============================] - 1s 48ms/step - loss: -0.0091
HBox(children=(IntProgress(value=0, max=1), HTML(value=’’)))
The 0 times epoch one class svm Error Rate=1.000000
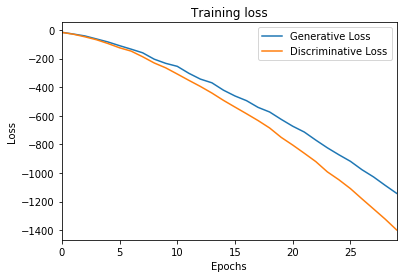
d_loss, g_loss ,xx,yy= train(GAN, G, D, epochs=300, verbose=True)loss plot
ax = pd.DataFrame(
{
'Generative Loss': g_loss,
'Discriminative Loss': d_loss,
}
).plot(title='Training loss', logy=False)
ax.set_xlabel("Epochs")
ax.set_ylabel("Loss")Text(0, 0.5, ‘Loss’)
generate and bulid models
new_data = gen(GAN, G, D, times = 2,verbose=True)
new_data.columns = d_nor.columns
new_data['CRE'] = 1
d_train = pd.concat([d_nor,d_cre],axis = 0)
d_train["CRE"] = data_train["CRE"]
new_data_train = pd.concat([d_train,new_data],axis = 0)
new_data_trainThe 0 times generator one class svm Error Rate=1.000000 The 1 times generator one class svm Error Rate=1.000000
| V993 | V322 | V864 | V689 | V598 | V1156 | V240 | V395 | V1255 | V1218 | … | V821 | V122 | V1227 | V386 | V771 | V551 | V538 | V1220 | V1179 | CRE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 84 | 0.000000e+00 | 0.000000 | 1616.050000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1524.790000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 576.870000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 59 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 93 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 49 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 89 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 46 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 532747.500000 | 0.000000 | 0 |
| 50 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 73 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 3.789579e+06 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 53 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 75932.230000 | 0.000000 | 0 |
| 90 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 120355.780000 | 0 |
| 72 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 6.081896e+04 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 55 | 0.000000e+00 | 43165.340000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 1.610336e+07 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 80 | 2.226269e+05 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 58034.680000 | 0 |
| 62 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 47390.040000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 107487.350000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 78 | 0.000000e+00 | 4350.400000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 47365.650000 | 0.000000 | 0.000000 | 0 |
| 63 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 79 | 7.658691e+05 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 6783.660000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 385997.310000 | 0.000000 | 23789.800000 | 0.000000 | 0.000000 | 17489.530000 | 0.000000 | 0.000000 | 0 |
| 75 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 31978.320000 | 0.000000 | 0.000000 | 0 |
| 88 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 4.644874e+04 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0 |
| 12 | 4.961734e+06 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 145406.670000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1 |
| 3 | 2.020681e+07 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 204892.950000 | 0.000000 | 1 |
| 2 | 4.932036e+06 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 72948.780000 | 0.000000 | 1 |
| 8 | 9.387160e+06 | 79444.560000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 5.207452e+04 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1 |
| 6 | 6.053306e+06 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1 |
| 13 | 1.272117e+07 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1 |
| 0 | 1.512491e+07 | -16218.833383 | -0.993609 | 0.995566 | -9.963942e-01 | -0.996621 | 0.994142 | 0.998140 | -0.995715 | -0.996149 | … | -1.062502e+04 | -29740.948329 | -0.998415 | 0.997263 | 0.994520 | -0.997255 | -0.993365 | 121635.468003 | -0.993095 | 1 |
| 1 | 1.506312e+07 | -16018.118402 | -0.985025 | 0.989016 | -9.891991e-01 | -0.990969 | 0.981192 | 0.993236 | -0.987260 | -0.986484 | … | -1.056079e+04 | -29401.546549 | -0.991166 | 0.994364 | 0.985471 | -0.986429 | -0.985721 | 120628.955686 | -0.984401 | 1 |
| 2 | 1.511217e+07 | -16203.647890 | -0.992818 | 0.993807 | -9.955698e-01 | -0.995253 | 0.990759 | 0.996745 | -0.993857 | -0.993840 | … | -1.061835e+04 | -29667.786330 | -0.996489 | 0.996588 | 0.992731 | -0.993555 | -0.990812 | 121295.633443 | -0.992025 | 1 |
| 3 | 1.496042e+07 | -15581.279153 | -0.966205 | 0.968444 | -9.806563e-01 | -0.977659 | 0.957520 | 0.980549 | -0.969081 | -0.972953 | … | -1.025045e+04 | -28607.187664 | -0.987470 | 0.981976 | 0.964365 | -0.969920 | -0.963239 | 118564.882265 | -0.971673 | 1 |
| 4 | 1.513735e+07 | -16285.360136 | -0.997202 | 0.997497 | -9.974456e-01 | -0.997892 | 0.997145 | 0.998738 | -0.998016 | -0.997765 | … | -1.067976e+04 | -29855.686473 | -0.999103 | 0.998467 | 0.996284 | -0.997739 | -0.997499 | 121800.363942 | -0.996244 | 1 |
| 5 | 1.507087e+07 | -15967.363031 | -0.976027 | 0.983896 | -9.862480e-01 | -0.986026 | 0.980322 | 0.993358 | -0.987903 | -0.982607 | … | -1.038747e+04 | -29348.452340 | -0.988892 | 0.990501 | 0.981182 | -0.988225 | -0.981214 | 120886.994780 | -0.974020 | 1 |
| 0 | 1.508056e+07 | -15925.283069 | -0.987930 | 0.987971 | -9.846137e-01 | -0.990841 | 0.990818 | 0.993492 | -0.989569 | -0.989493 | … | -1.049298e+04 | -29527.114775 | -0.993623 | 0.992465 | 0.983135 | -0.987305 | -0.993185 | 121117.700984 | -0.977792 | 1 |
| 1 | 1.514196e+07 | -16296.326162 | -0.996452 | 0.996435 | -9.980265e-01 | -0.998247 | 0.996632 | 0.998864 | -0.996634 | -0.997642 | … | -1.066461e+04 | -29840.008210 | -0.998694 | 0.998259 | 0.995150 | -0.998254 | -0.996857 | 121828.771543 | -0.995327 | 1 |
| 2 | 1.512663e+07 | -16255.855632 | -0.994796 | 0.996507 | -9.964558e-01 | -0.997275 | 0.993639 | 0.998080 | -0.995786 | -0.996104 | … | -1.067495e+04 | -29788.474074 | -0.997894 | 0.998463 | 0.995382 | -0.994885 | -0.995674 | 121512.002636 | -0.994164 | 1 |
| 3 | 1.512467e+07 | -16237.220094 | -0.993826 | 0.994421 | -9.969582e-01 | -0.996626 | 0.993722 | 0.997794 | -0.995277 | -0.995618 | … | -1.063710e+04 | -29764.659522 | -0.998138 | 0.997284 | 0.993458 | -0.995569 | -0.994352 | 121550.172951 | -0.993698 | 1 |
| 4 | 1.514689e+07 | -16320.480008 | -0.997326 | 0.998062 | -9.979978e-01 | -0.998915 | 0.997715 | 0.999290 | -0.997620 | -0.998389 | … | -1.069688e+04 | -29884.836932 | -0.999016 | 0.999236 | 0.997096 | -0.998345 | -0.998637 | 121884.855218 | -0.995719 | 1 |
| 5 | 1.513991e+07 | -16296.945582 | -0.996303 | 0.997118 | -9.973860e-01 | -0.998098 | 0.996116 | 0.998822 | -0.996933 | -0.997412 | … | -1.067624e+04 | -29835.214938 | -0.998451 | 0.998534 | 0.995529 | -0.998190 | -0.996817 | 121807.697267 | -0.995231 | 1 |
37 rows × 170 columns
loocv(new_data_train)1.0
from sklearn.model_selection import train_test_split
from sklearn import ensemble
from sklearn import metrics
train_X = new_data_train.iloc[:,0:169]
test_X = test.iloc[:,:]
train_y = new_data_train["CRE"]
test_y = data_test["CRE"]
forest = ensemble.RandomForestClassifier(n_estimators = 10)
forest_fit = forest.fit(train_X, train_y)
test_y_predicted = forest.predict(test_X)
accuracy_rf = metrics.accuracy_score(test_y, test_y_predicted)
print(accuracy_rf)
test_auc = metrics.roc_auc_score(test_y, test_y_predicted)
print (test_auc)
import sklearn
f1 = sklearn.metrics.f1_score(test_y, test_y_predicted)
print(f1)1.0
1.0
1.0