基本上生成樣本已經是可以達成的事情,目前就是調整gan各處的結構,如優化器、激活函數、損失函數等等,目前嘗試皆以randomforest(n=100)當作統一的模型。下圖是一般神經網路的結構:
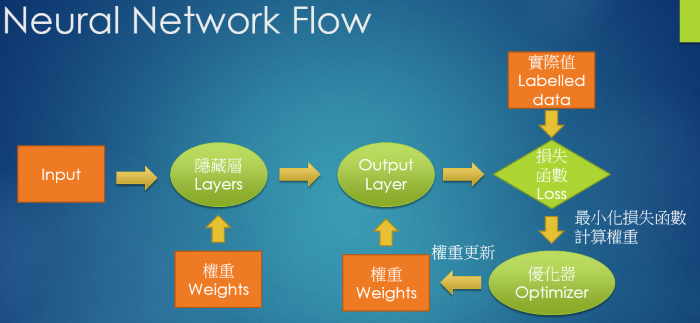
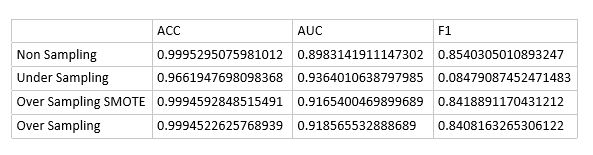
而生成對抗網路則有生成器與判別器兩個神經網路的串接,因此排列組合十分多種,且echo的次數與每個組合的效果並不一定相同,不一定回傳越多次效果越好,因此想先比較完大部分組合後再從中擇優,以下是將之前信用卡資料切分為train:test為1:1後的比較結果,比較傳統oversampling、undersampling與Non Sampling的效果,結果如下圖:
接下來與gan進行比較,gan的各種組合下表現:
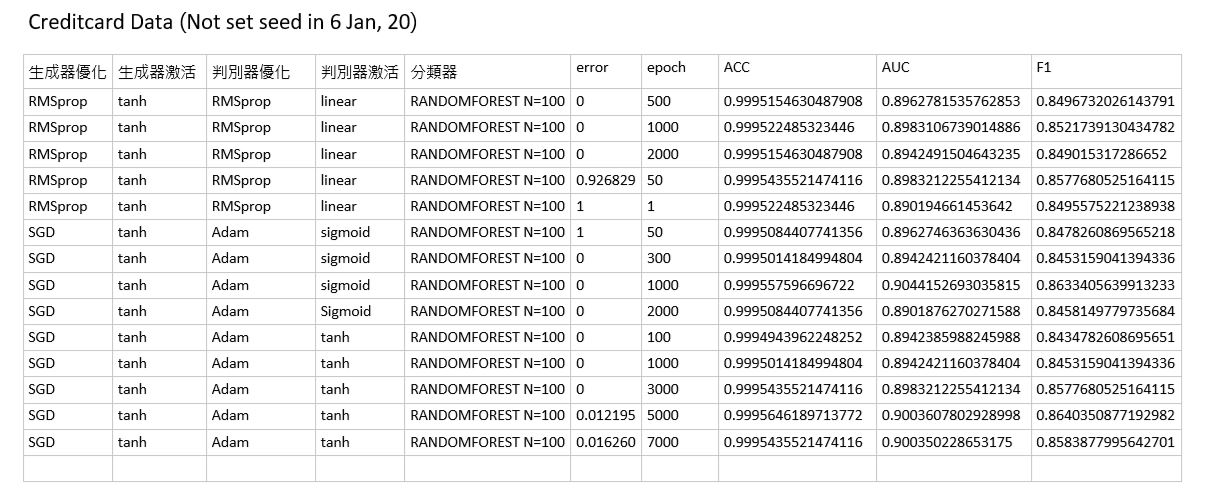
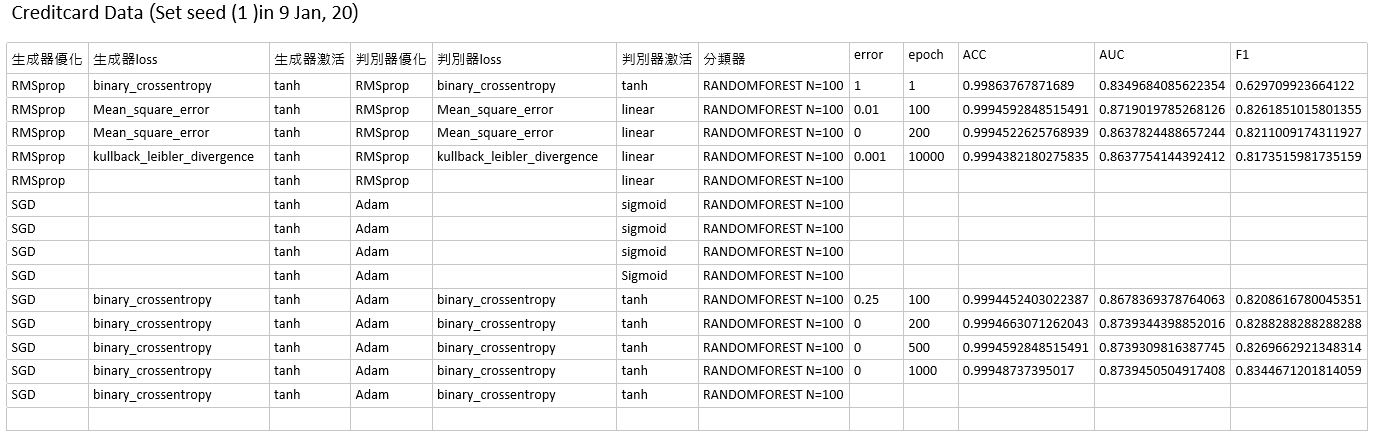
其中error即為我這裡的one class error rate,目前這些組合都是迭代到一定程度後,基本上都能讓occ-error降到0,但同為0時分類的效果依然有差別,且目前許多優化器的算法仍不明瞭,可能須花些時間比較各優化器的演算法,並調整Learning rate來確認其影響性。
而目前wgan的效果未必比較好,雖然wgan的設置可以讓兩個神經網路的loss有同時下降的可能,但從我們的結果論來看並不一定會有比較好的效果,也可能是wgan設定的Weight Clipping沒有比較好的定義,且該篇論文中提到loss不要取log,我僅將loss從binary_crossentropy改為Mean_square_error,但最終auc與f1-score也並無較好的效果,可能要嘗試其他的conditional gan的設定來traing或是來嘗試控制latent space的方式來建模比較看看,總之,繼續嘗試唄!