這學期修的資管系資料庫系統期末報告,主要是建立一個有著大資料表的資料庫系統,並且針對系統下三個查詢語句,並且進行查詢句的優化,老師有說可使用oracle或是Mongodb來完成這個project,但期中project時我們已經建立一個oracle資料庫系統,裡面的資料有六個table,其ERD如下:
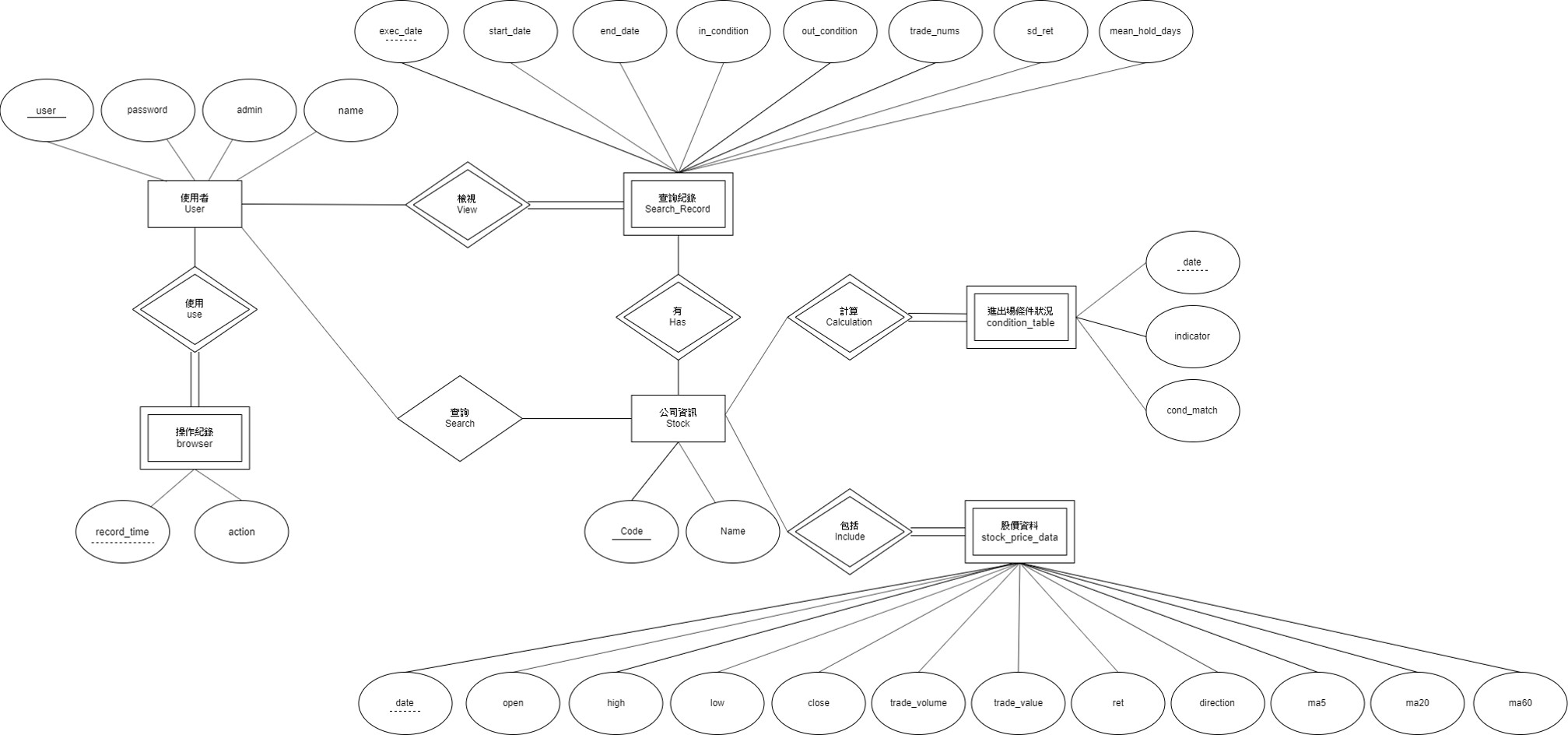
主要是一個台灣股價網頁查詢回測系統,(該網站連結:http://140.117.70.87:3838/dbproject/, 可使用訪客帳號test1,密碼test1),這邊稍微介紹一下這次專案會用到的資料型態,我們主要使用兩個table,stock_price_data以及condition_table, 第一個表內容有:股票代碼、公司名稱、日期、該日高點、該日低點、以及開收盤價格等;第二個表內容為:股票代碼、日期、何種進出場條件以及是否滿足。
我們第一個查詢句為:
SELECT code,name,date1,amplitude,RANK
FROM(SELECT code,name,date1,round(abs(HIGH - "low") / "low" * 100,2) as amplitude,
row_number() over (partition by code order by round(abs(HIGH - "low") / "low" * 100,2) desc) as rank
FROM STOCK_PRICE_DATA)
WHERE RANK <= 10主要目的是為了查詢各股票當日震盪幅度最大的前十名,列出名稱、代碼以及日期,而查詢句的cost在有沒有建立index的情況下是相同的,因此我們採用了別的方式來降低成本,因為我們原先是在查詢時計算並列出各股票在這段時間內的當日震盪排名,因此是在查詢時運算,而我們後來使用先計算當日漲跌幅度,減少查詢時的運算量的方式,相比原先平均的1.8秒,可降低0.5秒的查詢時間,平均大約為1.3秒。
我們第二個查詢句為:
SELECT NAME,CODE, COUNT(dirction)
FROM stock_price_data
WHERE dirction = ‘increasing’
AND date1 >= 20191106
AND date1 <= 20191108
HAVING COUNT(dirction) = 3
GROUP BY CODE,NAME;主要目的是為了查詢最近三天連續上漲的股票名稱及代碼,而查詢句的cost在有建立index後有明顯的降低,且查詢效率也有顯著提升,cost大約可以降低一半。
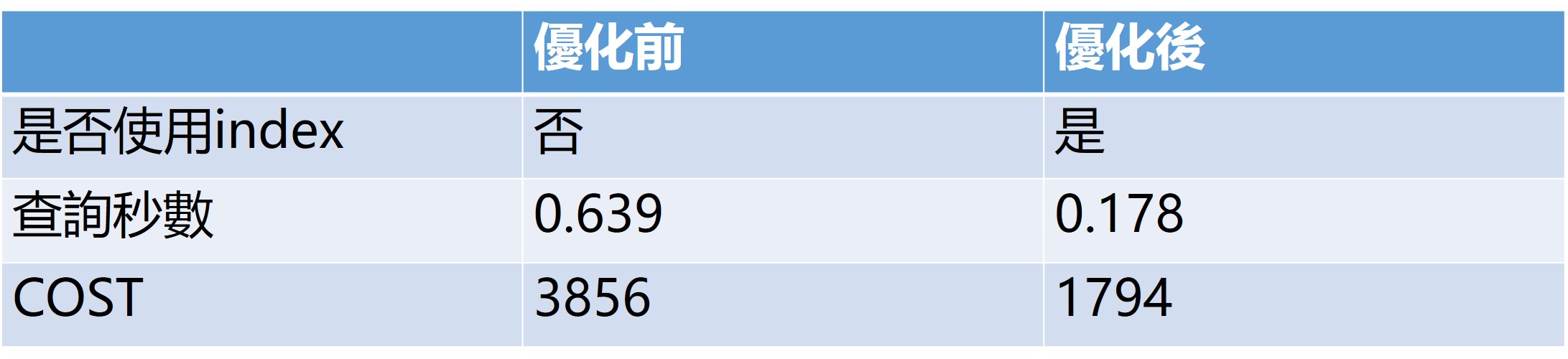
我們第三個查詢句為:
SELECT t1.code , t1.name
from (
(SELECT condition_table.CODE,condition_table.NAME ,condition_table."indicator" , condition_table.date1
FROM condition_table
WHERE condition_table.date1 = 20191108 AND condition_table.COND_MATCH = 1) t1
join
(SELECT CODE
FROM stock_price_data
WHERE dirction = 'increasing' AND date1 >= 20191106 AND date1 <= 20191108
HAVING COUNT(dirction)=3
GROUP BY CODE,NAME) t2
ON t1.code = t2.code
)主要目的是為了查詢連日上漲且符合進場標準的股票,列出名稱、代碼、以及進場條件,在這邊我們設定是三天內皆上漲,且現在正好是滿足進場條件的股票,因此這個查詢句需要join兩個表格:股價資料以及進場條件資料,而這個查詢也跟先前一樣,若是資料庫有建置index,則查詢句成本則大幅下降,且提升查詢效率。
在上面三個例子當中我們可以發現,建立index可以在許多時候提升查詢效率,但索引也不是都有建立的必要,若是資料量小則不需要使用索引,因為建立索引會使用額外的儲存空間。因此資料量大且需要頻繁查詢時,可以透過索引的方式降低來全部讀取的低效查詢。
這邊再稍微提幾個點,下面幾個情況不適合建立索引:
1.唯一性太差的字段不適合建立索引
2.更新太頻繁地字段不適合建立索引
3.不會出現於where的table