這禮拜看完一篇有關生成對抗網路與One Class Learning 結合的論文(Source Link:https://arxiv.org/abs/1903.08550) ,其名稱為<
 作者提出了一種稱為OCGAN的檢測模型,其目的是確定是否樣本來自同一個種類。作者的方案是基於使用auto-encoder network來學習神經網路單類樣本的潛在表示。而本篇文章的模型可明確限制潛在空間。為了實現這一目標,首先迫使潛在空間通過以tanh的激活函數引入編碼器的輸出。其次,利用adversariallyr鑑別潛在空間,確保同類的編碼表示類似於從相同的有界空間引出的均勻隨機樣本。第三,使用在輸入空間中第二對抗性鑑別,我們保證所有隨機抽取的樣本潛伏產生的例子看起來真實。最後,我們引入一個基於採樣技術的梯度下降,在潛在空間探索點產生出例子,以進一步訓練它產生這些近似於實體的例子。
作者提出了一種稱為OCGAN的檢測模型,其目的是確定是否樣本來自同一個種類。作者的方案是基於使用auto-encoder network來學習神經網路單類樣本的潛在表示。而本篇文章的模型可明確限制潛在空間。為了實現這一目標,首先迫使潛在空間通過以tanh的激活函數引入編碼器的輸出。其次,利用adversariallyr鑑別潛在空間,確保同類的編碼表示類似於從相同的有界空間引出的均勻隨機樣本。第三,使用在輸入空間中第二對抗性鑑別,我們保證所有隨機抽取的樣本潛伏產生的例子看起來真實。最後,我們引入一個基於採樣技術的梯度下降,在潛在空間探索點產生出例子,以進一步訓練它產生這些近似於實體的例子。
1. Novelty Detection
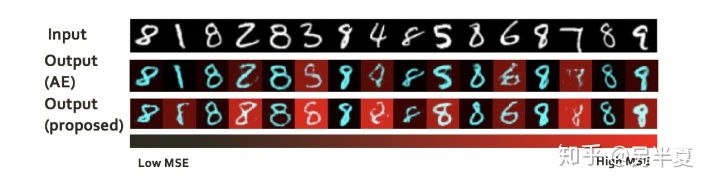
中文翻譯過來 新奇檢測,不完全等同於異常檢測。通俗來講就是訓練樣本中只有單類(one-class)樣本,測試中需要檢測到不屬於該類的樣本。常用的方法有基於差異度量(重構誤差)和基於分佈(GMM)。對於基於距離度量方法,常用就是auto-encoder,通過單類樣本訓練一個AE,我們期望它對該類重構的誤差越小越好,同時對於其他類樣本,由於訓練過程中沒有見過,產生的重構誤差應該較大。
但這有個問題,AE的capacity比較強,很難保證對於其他類樣本重構較差,這在其他文獻中也有出現。該文作者發現,我們不僅需要(1)單類樣本在隱空間(latent space)中被很好表示,(2)同時希望其他類樣本在該空間不能被很好表示。之前的工作大部分局限在前半部分(1),而忽視了後半部分(2)。基於此,作者提出自己的構想—>>如果整個隱空間被限制為表示給定類的圖像,那麼其他類(out-of-class)樣本的表示將認為在該空間幾乎不存在(minimal)— —從而為它們產生很高重構誤差。
2. OCGAN
OCGAN有四部分組成:
1.去噪編碼器(denoising ae)
2.隱判別器(latent discriminator)
3.圖像判別器(visual discriminator)
4.分類器(classifier)

接下來講解各部分作用:
1.去噪編碼器(denoising ae)
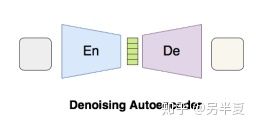
AE的主要作用就是學習特徵表示(feature representation)。其瓶頸層的輸出即為表示,其所在空間即為隱空間。為了使得隱空間有界,作者使用了tanh,將其空間的值限定在[-1,1]。該AE的loss即為均方誤差(mse)。使用去噪AE的原因是因為去噪AE可以降低過擬合,提高泛化能力。
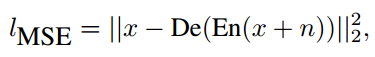
2. 隱判別器(latent discriminator)
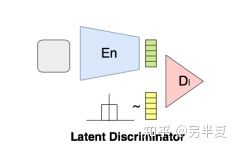
如前所述,該動機是獲得一個隱空間,空間中的每個實例表示給定類的圖像。如果給定類的表示僅限於潛在空間的子區域,則無法實現此目標。因此,我們顯式地強制給定類的表示均勻的分佈在整個隱空間。做法如下:
構建一個判別器\(D_l\),來判別給定類的表示和來在\(U(-1,1)^d\)的樣本。其損失函數:
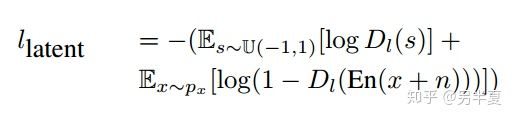
3. 圖像判別器(visual discriminator)
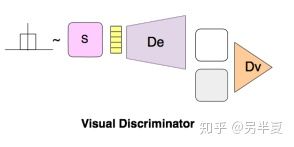
動機:隱空間的所有樣本通過decoder(或者叫generator)生成的圖像應該來自於給定類的圖像的空間。為了滿足這個約束,構建第二個判別器\(D_v\),來判別給定類的圖像和從隱空間隨機採樣通過decoder之後生成的圖像。損失函數如下:
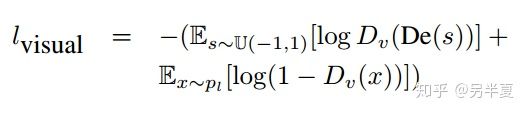
至此構成整個論文的核心。但是作者發現,即使這樣,從隱空間中採樣生成的圖像有時候也很難對應於給定類圖像。這是因為隱空間太大了,完全採樣到是不可能的。於是不如主動去發現隱空間中的那些產生poor的圖像的區域。
- 分類器
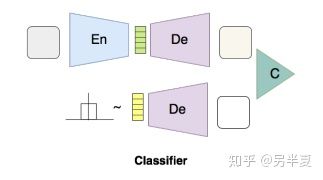
分類器的作用是判別生成的圖像和給定類的圖像的相似度。使用給定類圖像作為正樣本,生成圖像作為負樣本。該分類器的損失函數為二類交叉熵(BCE)。
- 最終結構
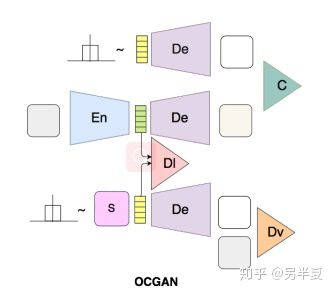
訓練方式如下:

交替優化的方式:
第一步固定住除分類器之外的所有部件,並優化分類器。
第二部固定分類器,優化AE和判別器。
3. Experiment
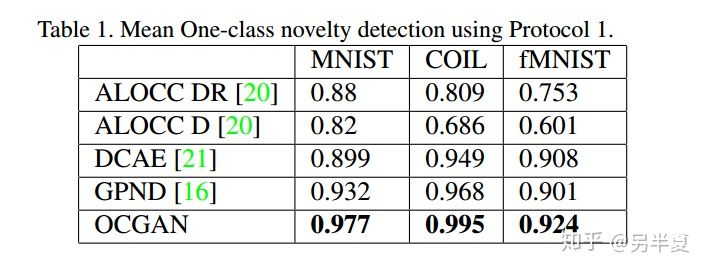
來列一些實驗結果,
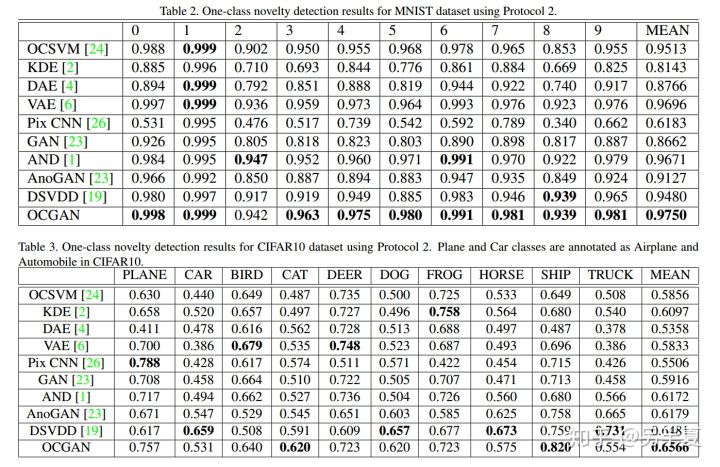
消融實驗:
