I read some paper about GAN for generate synthetic sample data. Then I find a paper it’s framework works similar with my one-class-GAN. So I want to record the paper’s marrows this time.
There is the paper resource link: https://www.sciencedirect.com/science/article/abs/pii/S0925231219309257?dgcid=rss_sd_all
In this paper, we propose an approach based on a generative adversarial network (GAN) combined with a deep neural network (DNN). First, the original samples were divided into a training set and a test set. The GAN was trained with the training set to generate synthetic sample data, which enlarged the training set. Next, the DNN classifier was trained with the synthetic samples. Finally, the classifier was tested with the test set, and the effectiveness of the approach for multi-classification with a small sample size was validated by the indicators.
1. Introduction and background
在很多時候,我們的樣本獲取可能成本極高,此外, 資料可能也存在高維度的問題,而這種維度高於樣本的情況我們稱之為‘‘the small sample size problem”。而在以前,其實也已經有多種over sampling的方法存在了,這些方法的主要優點是,他們能自我產生。在早期階段,訓練集可以通過擴大少數類的訓練集如有不同類的實例是不平衡,或通過添加random noise到現有新的數據集,而最廣為人知的大概便是synthetic minority oversampling technique (SMOTE)。
近年來,隨著人工智能和大數據的迅速發展,使用基於深層神經網絡(DNN)的generative adversarial Network(GAN)提供了新的可能,創造新型求解值數據問題的方法。而它即使在小樣本大小的情況下,也有可應用的能力。
為了解決由小樣本所帶來的多分類問題,我們提出了一個方法,結合了GAN與DNN。在最開始我們將原始資料分為訓練集以及驗證集,最後用一些指標,比較SMOTE以及GAN對於生成資料的效果。
2. Methodology
2.1. Workflow of the study
為了解決一個小樣本提出的監督學習問題規模和延長深度學習的應用範圍,這本文提出了一種GaN結合了DNN的多分類方法。這種方法可以作如下概括(圖。1):
(1)除以原始樣品放入一個訓練集和測試集。使用訓練集訓練GAN和調整其超參數。
(2)使用GAN的訓練生成器來生成合成樣本,並使用鑑別過濾這些樣品。
(3)使用合成樣品訓練DNN分類器,和使用測試設置來測試DNN分類。
2.2. Generative adversarial network
本次研究是使用WGAN,這裡對WGAN做一個簡介(Resorce link: https://arxiv.org/abs/1701.07875):
1.徹底解決GAN訓練不穩定的問題,不再需要小心平衡生成器和判別器的訓練程度
2.基本解決了collapse mode的問題,確保了生成樣本的多樣性
3.訓練過程中終於有一個像交叉熵、準確率這樣的數值來指示訓練的進程,這個數值越小代表GAN訓練得越好,代表生成器產生的圖像質量越高(如題圖所示)
4.以上一切好處不需要精心設計的網絡架構,最簡單的多層全連接網絡就可以做到
相比原始GAN的算法實現流程卻只改了四點:
1.判別器最後一層去掉sigmoid
2.生成器和判別器的loss不取log
3.每次更新判別器的參數之後把它們的絕對值截斷到不超過一個固定常數c
4.不要用基於動量的優化算法(包括momentum和Adam),推薦RMSProp,SGD也行
(Resorce link: https://zhuanlan.zhihu.com/p/25071913)
2.3. Deep neural network
本研究採用DNN,這是一個基於深度學習深層的結構分類器。一個DNN分類器可以利用計算幾種模型來數據的多個層;該模型由多個處理層組成。 DNN的分類器,便使用大量由WGAN生成合成樣品的訓練,以避免over-fitting。
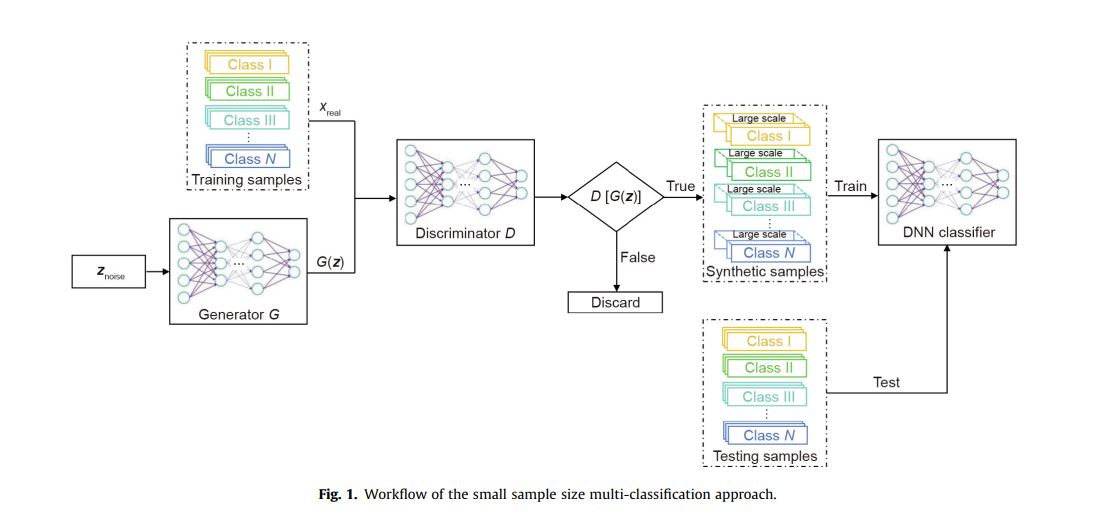 上圖為整個研究的流程,簡單來說就是以gan生成足夠的資料去建構一個dnn的分類器。
上圖為整個研究的流程,簡單來說就是以gan生成足夠的資料去建構一個dnn的分類器。
而在這篇文章中我們將以幾個指標來當作衡量標準:
1.Accuracy
2.G-mean
3.F-measure
※what is F-measure & G-mean ?
在資訊檢索領域,真陽性率被稱為 recall,
陽性預測值被稱為精確率分別定義如下:
Recall =TPrate =TP/(TP+FN),
Precision =PPvalue = TP/(TP+FP)
F-measure=2×Recall×Precision/(Recall+Precision)
F-measure是 Precision 和 Recall 的調和平均值。 兩個數值的調和平均更加接近兩個數當中較小的那個, 因此如果要使得 F-measure 很高的話那麼 Recall 和 Precision 都必須很高。
而g-mean = Precision × Recall
3. Empirical analysis and discussion
病理數據是十分昂貴獲取且數據註釋是很困難的。其結果是,病理研究經常會遇到一個小樣本的問題。因此,病理學領域中數據擴張的應用是典型的。肝細胞癌(HCC)是五年相對存活率低於15%的常見惡性腫瘤,五年相對存活率HCC的能有效地由早期治療得到改善。然而,對早期肝癌的鑑定研究限制 於缺乏樣本以及資料片段化(不同醫院,以及不同主治醫生導致資料不連續)。Glycosylation(醣基化:https://reurl.cc/qDo5ey) 是最普遍的生物作用。許多癌症相關的流程,包括致癌細胞轉移、腫瘤成長、和抗腫瘤免疫與蛋白的糖基化異常相關。此外,各種腫瘤標記物是在改變糖蛋白血清糖組學。因此,糖基化數據是一個有效用於癌症分期的預測。在這個部分,我們將使用WGAN與一個DNN結合,以識別HCC的階段,並最終用於診斷和治療肝癌。
3.1. Data collection
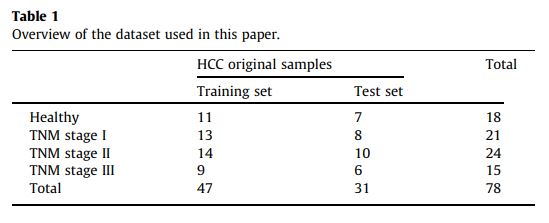
在這項研究中,血清樣本由同濟醫院(同濟大學醫學院,華中科技大學)捐贈用作實驗數據。癌症的階段是根據腫瘤淋巴結轉移(TNM)劃分。通過上述生物過程,60個HCC病例(TNM分期I 21例; TNM分期II 24例;和TNM分期III 15例),每個包含42特徵,和用作對照組18名健康的樣本。每個樣本皆有42維度的特徵向量,根據其峰分佈順序和相對強度,HCC病例分成訓練集(60%)和測試組(40%),如圖表格1。
3.2. Result analysis
根據所提出的方法,我們首先使用TNM分期I, TNM分期II,TNM分期III,與對照組的訓練集,以訓練WGAN,然後用訓練有素的WGAN生成相應的合成的樣品。對於該超參數是通過一系列的實驗來確定。該生成器具有一個隱藏層含有32整流線性單位(ReLUs),和42 sigmoid units作輸出層。該噪聲被設定為15。鑑別也有一個隱含層,其含有64 ReLUs;一個單元沒有激活函數被用作輸出層。該每個類的訓練樣本WGAN的超參數分別為相同。該WGAN的開發環境是TensorFlow1.1並通過圖形處理受訓單元(GPU)。該WGAN訓練過程包含300000迭代。在WGAN訓練的每次迭代,鑑別第一迭代100倍,然後將生成器迭代一次。
在HCC病例的合成樣本生成後,這些樣本用於訓練分類器DNN。DNN分類器是一個多層感知器(MLP),然後用HCC測試集驗證。之後在一系列的實驗DNN的超參數進行測定。分類器的輸入是42,這是等於HCC樣本中的特徵數量。該分類有三個隱藏層,每片含32ReLUs;該SOFTMAX函數被用作輸出層和交叉熵被用作損失函數。環境為TensorFlow1.1和GPU用於訓練的DNN分類,迭代次數為3000。
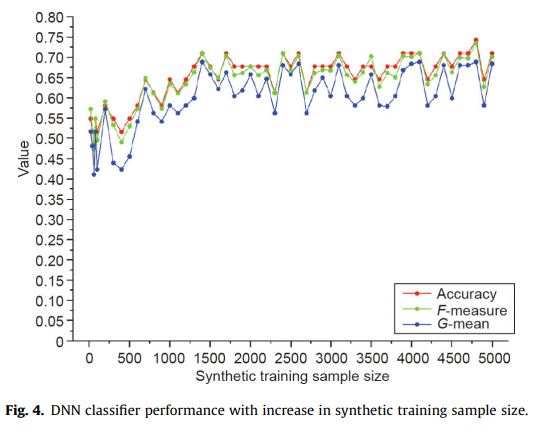
為了評估這些合成訓練樣本大小的影響DNN的分類器的性能,我們使用了不同數量合成樣品訓練分類器DNN,然後用實際的樣品測試的準確性,F值的三個指標,以及G-mean。我們逐步增加產出的樣本於DNN模型當中,而精確度,F值,和G-mean的變化示於圖4中:
這裡比較有意思的地方在於,他分類錯誤所造成的成本我們並未考慮到,以4000當作一個例子,以下是其Confusion Matrix:
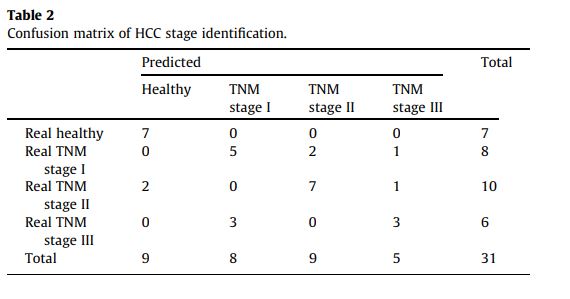
若是要考慮誤診(type1&2 error)的機會成本不同,則分類器應該要加重權重,或是數據的平衡上要有所改變。
接著我們要比較gan與smote的功效,且為了要測試dnn分類方法的有效性,將使用幾種成見的分類方法來比較。隨機森林(RF)是一個集成學習方法以更高的精度和比其他機器學習模型更好的泛化能力,而樸素貝葉斯(NB)分類器有一個簡單的原則和穩定的分類性能。這兩種算法是選擇作為經典的統計機器學習分類的代表。因此將使用smote、gan與rf、nb、dnn來進行交叉比較。結果如下表:
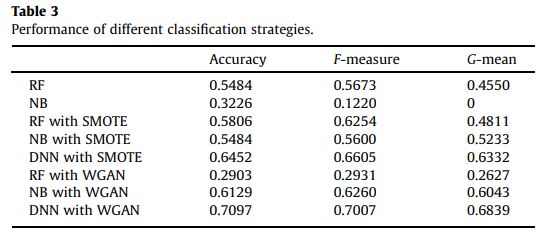
3.4. Discussion
根據上面給出的實驗結果,WGAN結合了DNN可以應用於HCC的識別階段,並使得性能與傳統方法相比是更加優異的。癌症研究大多數是受於小樣本問題受阻。這個問題導致了早期診斷和治療癌症的進展緩慢;此外,它影響癌症發病機制的探索。我們的數據增強基於WGAN方法可解決這些類型問題。所提出的方法的目的是不僅要能解決肝癌分期的問題,同時也解決了小樣本使用監督學習問題。因此,癌症分期數據基於血清樣品選擇,因為這些數據導致與傳統的統計機器性能不佳由於小樣本問題學習。