生成對抗網路實現
這次我將考慮一個非常簡單的問題,在非圖像資料上實驗生成對抗網路。在這次的實驗中,將生成隨機正弦曲線,並且將嘗試使GAN生成正確的正弦曲線。
%matplotlib inline
import os
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm_notebook as tqdm
from keras.models import Model
from keras.layers import Input, Reshape
from keras.layers.core import Dense, Activation, Dropout, Flatten
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import UpSampling1D, Conv1D
from keras.layers.advanced_activations import LeakyReLU
from keras.optimizers import Adam, SGD
from keras.callbacks import TensorBoardUsing TensorFlow backend.隨機生成資料
def sample_data(n_samples=10000, x_vals=np.arange(0, 5, .1), max_offset=100, mul_range=[1, 2]):
vectors = []
for i in range(n_samples):
offset = np.random.random() * max_offset
mul = mul_range[0] + np.random.random() * (mul_range[1] - mul_range[0])
vectors.append(
np.sin(offset + x_vals * mul) / 2 + .5
)
return np.array(vectors)
ax = pd.DataFrame(np.transpose(sample_data(5))).plot()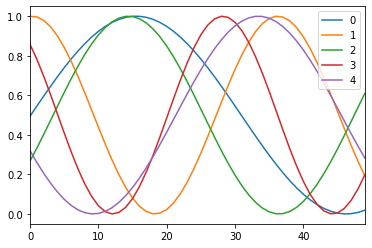
創建模型
需要創建一個模型,該模型將訓練資料以從某些隨機數字生成結果,以及一個應該從生成的數據中檢測真實數據的模型。
生成模型
使用tanh當激活函數並用密集層來創建生成模型。模型將匯入隨機數字並嘗試從中生成正弦曲線。模型不會直接進行訓練,而是通過GAN進行訓練。
def get_generative(G_in, dense_dim=200, out_dim=50, lr=1e-3):
x = Dense(dense_dim)(G_in)
x = Activation('tanh')(x)
G_out = Dense(out_dim, activation='tanh')(x)
G = Model(G_in, G_out)
opt = SGD(lr=lr)
G.compile(loss='binary_crossentropy', optimizer=opt)
return G, G_out
G_in = Input(shape=[10])
G, G_out = get_generative(G_in)
G.summary()WARNING:tensorflow:From C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\keras\backend\tensorflow_backend.py:74: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\keras\backend\tensorflow_backend.py:517: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
WARNING:tensorflow:From C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\keras\backend\tensorflow_backend.py:4138: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
WARNING:tensorflow:From C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\keras\optimizers.py:790: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
WARNING:tensorflow:From C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\keras\backend\tensorflow_backend.py:3376: The name tf.log is deprecated. Please use tf.math.log instead.
WARNING:tensorflow:From C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\tensorflow\python\ops\nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 10) 0
_________________________________________________________________
dense_1 (Dense) (None, 200) 2200
_________________________________________________________________
activation_1 (Activation) (None, 200) 0
_________________________________________________________________
dense_2 (Dense) (None, 50) 10050
=================================================================
Total params: 12,250
Trainable params: 12,250
Non-trainable params: 0
_________________________________________________________________判別模型
創建判別模型,模型將定義曲線是真實的還是生成模型輸出的。這模型將直接進行培訓。
def get_discriminative(D_in, lr=1e-3, drate=.25, n_channels=50, conv_sz=5, leak=.2):
x = Reshape((-1, 1))(D_in)
x = Conv1D(n_channels, conv_sz, activation='relu')(x)
x = Dropout(drate)(x)
x = Flatten()(x)
x = Dense(n_channels)(x)
D_out = Dense(2, activation='sigmoid')(x)
D = Model(D_in, D_out)
dopt = Adam(lr=lr)
D.compile(loss='binary_crossentropy', optimizer=dopt)
return D, D_out
D_in = Input(shape=[50])
D, D_out = get_discriminative(D_in)
D.summary()WARNING:tensorflow:From C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\keras\backend\tensorflow_backend.py:133: The name tf.placeholder_with_default is deprecated. Please use tf.compat.v1.placeholder_with_default instead.
WARNING:tensorflow:From C:\Users\User\Anaconda3\envs\Tensorflow-gpu\lib\site-packages\keras\backend\tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 50) 0
_________________________________________________________________
reshape_1 (Reshape) (None, 50, 1) 0
_________________________________________________________________
conv1d_1 (Conv1D) (None, 46, 50) 300
_________________________________________________________________
dropout_1 (Dropout) (None, 46, 50) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2300) 0
_________________________________________________________________
dense_3 (Dense) (None, 50) 115050
_________________________________________________________________
dense_4 (Dense) (None, 2) 102
=================================================================
Total params: 115,452
Trainable params: 115,452
Non-trainable params: 0
_________________________________________________________________鏈接模型:GAN
最後,我們將這兩個模型鏈接到GAN中,並且凍結鑑別器的同時訓練生成器。
為了凍結給定模型的權重,我們創建了此凍結函數,該函數將在每次訓練GAN時應用於判別模型,以訓練生成模型。
def set_trainability(model, trainable=False):
model.trainable = trainable
for layer in model.layers:
layer.trainable = trainable
def make_gan(GAN_in, G, D):
set_trainability(D, False)
x = G(GAN_in)
GAN_out = D(x)
GAN = Model(GAN_in, GAN_out)
GAN.compile(loss='binary_crossentropy', optimizer=G.optimizer)
return GAN, GAN_out
GAN_in = Input([10])
GAN, GAN_out = make_gan(GAN_in, G, D)
GAN.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) (None, 10) 0
_________________________________________________________________
model_1 (Model) (None, 50) 12250
_________________________________________________________________
model_2 (Model) (None, 2) 115452
=================================================================
Total params: 127,702
Trainable params: 12,250
Non-trainable params: 115,452
_________________________________________________________________訓練
現在我們已經完成了模型的設置,我們可以通過更改對鑑別器和鍊式模型的訓練來訓練模型。
Pre Training
現在讓我們生成一些虛假的真實數據,並在啟動gan之前對鑑別器進行pre training。這也讓我們檢查編譯後的模型是否在真實和隨機產生的資料上運行。
def sample_data_and_gen(G, noise_dim=10, n_samples=10000):
XT = sample_data(n_samples=n_samples)
XN_noise = np.random.uniform(0, 1, size=[n_samples, noise_dim])
XN = G.predict(XN_noise)
X = np.concatenate((XT, XN))
y = np.zeros((2*n_samples, 2))
y[:n_samples, 1] = 1
y[n_samples:, 0] = 1
return X, y
def pretrain(G, D, noise_dim=10, n_samples=10000, batch_size=32):
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
D.fit(X, y, epochs=1, batch_size=batch_size)
pretrain(G, D)Epoch 1/1
20000/20000 [==============================] - ETA: 4:46 - loss: 0.669 - ETA: 35s - loss: 0.400 - ETA: 19s - loss: 0.24 - ETA: 12s - loss: 0.15 - ETA: 10s - loss: 0.12 - ETA: 9s - loss: 0.1028 - ETA: 7s - loss: 0.081 - ETA: 7s - loss: 0.077 - ETA: 7s - loss: 0.070 - ETA: 7s - loss: 0.066 - ETA: 7s - loss: 0.064 - ETA: 7s - loss: 0.059 - ETA: 7s - loss: 0.057 - ETA: 7s - loss: 0.055 - ETA: 7s - loss: 0.050 - ETA: 7s - loss: 0.047 - ETA: 6s - loss: 0.044 - ETA: 7s - loss: 0.043 - ETA: 6s - loss: 0.040 - ETA: 6s - loss: 0.036 - ETA: 5s - loss: 0.033 - ETA: 5s - loss: 0.031 - ETA: 5s - loss: 0.029 - ETA: 5s - loss: 0.028 - ETA: 4s - loss: 0.026 - ETA: 4s - loss: 0.024 - ETA: 4s - loss: 0.023 - ETA: 4s - loss: 0.022 - ETA: 3s - loss: 0.021 - ETA: 3s - loss: 0.020 - ETA: 3s - loss: 0.019 - ETA: 3s - loss: 0.019 - ETA: 3s - loss: 0.018 - ETA: 3s - loss: 0.017 - ETA: 2s - loss: 0.016 - ETA: 2s - loss: 0.016 - ETA: 2s - loss: 0.015 - ETA: 2s - loss: 0.014 - ETA: 2s - loss: 0.014 - ETA: 2s - loss: 0.013 - ETA: 2s - loss: 0.013 - ETA: 2s - loss: 0.013 - ETA: 1s - loss: 0.012 - ETA: 1s - loss: 0.012 - ETA: 1s - loss: 0.011 - ETA: 1s - loss: 0.011 - ETA: 1s - loss: 0.011 - ETA: 1s - loss: 0.010 - ETA: 1s - loss: 0.010 - ETA: 1s - loss: 0.010 - ETA: 1s - loss: 0.010 - ETA: 1s - loss: 0.009 - ETA: 0s - loss: 0.009 - ETA: 0s - loss: 0.009 - ETA: 0s - loss: 0.009 - ETA: 0s - loss: 0.009 - ETA: 0s - loss: 0.008 - ETA: 0s - loss: 0.008 - ETA: 0s - loss: 0.008 - ETA: 0s - loss: 0.008 - ETA: 0s - loss: 0.008 - ETA: 0s - loss: 0.008 - ETA: 0s - loss: 0.008 - ETA: 0s - loss: 0.007 - ETA: 0s - loss: 0.007 - ETA: 0s - loss: 0.007 - 4s 202us/step - loss: 0.0075交替訓練步驟
現在,我們可以通過區分鑑別器的訓練和凍結鑑別器權重的鏈狀GAN模型的訓練來訓練GAN。
def sample_noise(G, noise_dim=10, n_samples=10000):
X = np.random.uniform(0, 1, size=[n_samples, noise_dim])
y = np.zeros((n_samples, 2))
y[:, 1] = 1
return X, y
def train(GAN, G, D, epochs=150, n_samples=10000, noise_dim=10, batch_size=32, verbose=False, v_freq=50):
d_loss = []
g_loss = []
e_range = range(epochs)
if verbose:
e_range = tqdm(e_range)
for epoch in e_range:
X, y = sample_data_and_gen(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, True)
d_loss.append(D.train_on_batch(X, y))
X, y = sample_noise(G, n_samples=n_samples, noise_dim=noise_dim)
set_trainability(D, False)
g_loss.append(GAN.train_on_batch(X, y))
if verbose and (epoch + 1) % v_freq == 0:
print("Epoch #{}: Generative Loss: {}, Discriminative Loss: {}".format(epoch + 1, g_loss[-1], d_loss[-1]))
return d_loss, g_loss
d_loss, g_loss = train(GAN, G, D, verbose=True)HBox(children=(IntProgress(value=0, max=150), HTML(value='')))
Epoch #50: Generative Loss: 5.585224628448486, Discriminative Loss: 0.055579833686351776
Epoch #100: Generative Loss: 4.101490497589111, Discriminative Loss: 0.06978452950716019
Epoch #150: Generative Loss: 3.4385266304016113, Discriminative Loss: 0.08029528707265854ax = pd.DataFrame(
{
'Generative Loss': g_loss,
'Discriminative Loss': d_loss,
}
).plot(title='Training loss', logy=True)
ax.set_xlabel("Epochs")
ax.set_ylabel("Loss")Text(0, 0.5, 'Loss')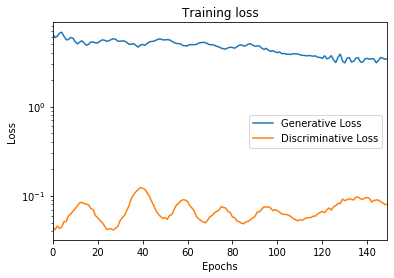
有趣的是,雙方都在互相比賽,彼此學習如何變得更好。我們看到,在某些階段,相對於另一側的損耗增益,生成器或鑑別器正在降低其損耗。
觀察模型的損失似乎對量化模型質量的進步似乎並不十分重要。實際上,我們實際上並不希望模型收斂到零太快,否則,這意味著它們設法互相欺騙。但是,每個模型相對於另一個模型變得更好的次數可能是一個有趣的指標。觀看。
結果
現在,我們可以從生成器中生成一些正弦曲線了:
N_VIEWED_SAMPLES = 2
data_and_gen, _ = sample_data_and_gen(G, n_samples=N_VIEWED_SAMPLES)
pd.DataFrame(np.transpose(data_and_gen[N_VIEWED_SAMPLES:])).plot()<matplotlib.axes._subplots.AxesSubplot at 0x2bd736e5b70>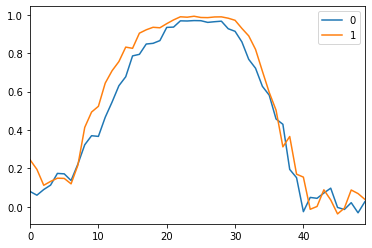
這不是完美的,但是,我們看到,如果使用滾動平均值對曲線進行一些平滑處理,則將逼近更精確的正弦形狀。
N_VIEWED_SAMPLES = 2
data_and_gen, _ = sample_data_and_gen(G, n_samples=N_VIEWED_SAMPLES)
pd.DataFrame(np.transpose(data_and_gen[N_VIEWED_SAMPLES:])).rolling(5).mean()[5:].plot()<matplotlib.axes._subplots.AxesSubplot at 0x2bd59242a58>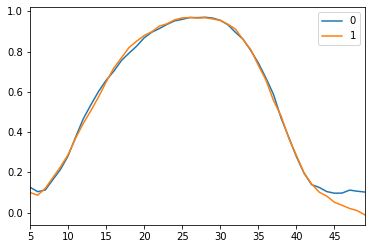
顯然,通過更多的培訓和更多的調整,我們可以獲得更好的結果。通常,可以證明在GAN上效率更高,但要在像這樣的簡單教程中運行很長。
最後我們看到產生器或多或少地輸出相同的曲線。GAN的風險很大,可以通過提供更多不同的數據來平衡,但總體上需要更多的訓練。
結論
從技術上講,在keras創建GAN並不是一項艱鉅的任務,因為要做的就是創建這3個模型並定義如何對它們進行訓練,但是根據要完成事情,將需要或多或少的調整和運算。