Drop 是由Geoff Hinton與多倫多大學的學生所開發的神經網路常規化技術之一。神經網路層的丟棄法,主要是在訓練期間隨機丟棄layer的一些輸出特徵。假設某個輸出向量為[0.2,0.5,1.3,0.8,1.1]的向量,在使用丟棄法後將隨機幾個向量的特徵歸零:[0.2,0,1.3,0,1.1],而控制丟失多少值一般是採用丟失率來計算,大約0.2~0.5的一個數值。而在test階段不會丟棄任何值,而是按照丟棄率去比例縮小,以平衡被歸零的影響。
實務上,我們可以在訓練時執行dropout然後把輸出值同比例放大,這樣做就不用再測試做任何變動了。

這個看似隨興的方法為何可以有效降低overfitting呢?核心想法是在layer的輸出加入雜訊,這樣可以打破不重要的偶然模式,因為如果沒有雜訊,神經網路就會開始死記結果,在keras中,我們可以透過add()來完成一個drop層並指定丟棄率,這樣就可以把前一個層的輸出依指定丟棄率來dropout。
model = models.Sequential()
model.add(laers.Dense(16,activation = 'relu', input_shape = (10000,)))
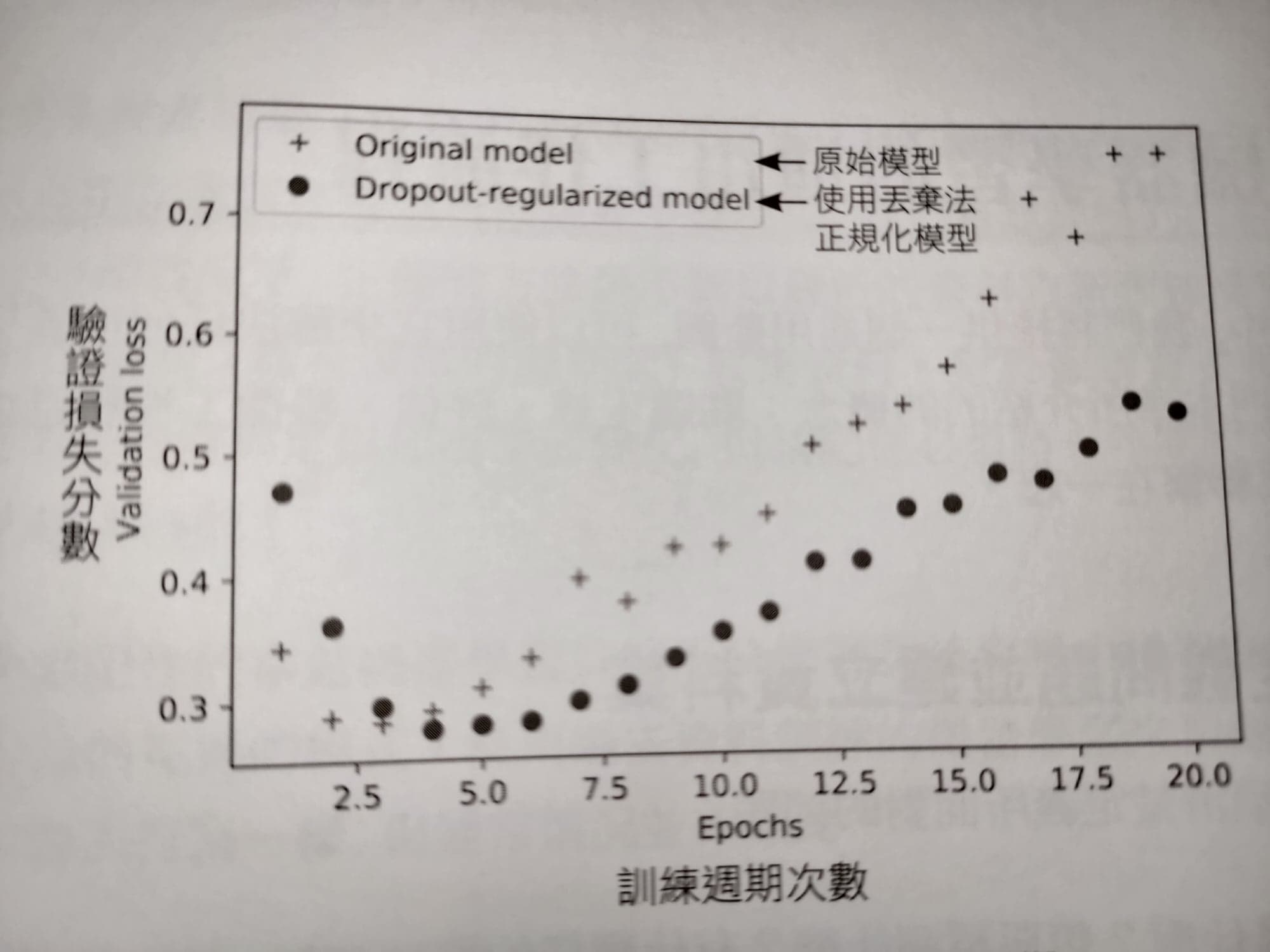
model.add(layers.Dropout(0.5)) #增加的Dropout下面是使用與未使用dropout的validation loss 比較圖: