MLB 球隊資料 爬蟲
這次參與工研院資料科學的課程,課程中分配的小組必須進行一個完整資料分析的報告,題目自訂。
因為球類的open data相對完整,基本上較少遺失值的問體,因此我們決定以mlb的球隊資料來當分析對象。
而主要分析目標則分為兩大類:第一、對例行賽勝率進行迴歸分析找出影響勝率的主因;第二、對”明年是否進入季後賽”做二項分類的預測。
這篇文章主要是介紹如何爬取並建立可分析的csv檔案。 主要使用pandas套件,並透過for迴圈去進行多個網頁的爬取,最後合併多年的投打資料,並以csv格式輸出。
因2004-2005之間有球隊更換隊名,因此為了”方便”資料合併,因此抓取範圍為2005-2018年間例行賽的球隊投打資料。
爬取網站為:https://www.baseball-reference.com/
爬蟲作業
import pandas as pd
下面我們先令一個空個list來存放各年的資料,因為打擊跟投球資料是分開的表格,因此在存放至df前會有合併的動作 (這一步會run有點久,時間大約3-5分鐘)。
#2005-2018 MLB url
df = list()#設一個空list來存放各年資料
df1 = pd.DataFrame()#預設dataframe做暫存
for i in range(5,19):
j = 2000+i
bat1 = ("https://www.baseball-reference.com/leagues/MLB/"+str(j)+"-standard-batting.shtml")#爬取第2000+i年的打擊資料
pitch1 = ("https://www.baseball-reference.com/leagues/MLB/"+str(j)+"-standard-pitching.shtml")#爬取第2000+i年的投手資料
df1 = pd.merge(pd.read_html(bat1)[0][0:30], pd.read_html(pitch1)[0][0:30], how='left', on='Tm')#Merge multiple dataframe
df1['Year']=j #Add the year
df1["Tm"] = df1["Tm"]+df1["Year"].map(str)
df += [df1]
接下來合併各年的資料,並將資料以隊伍做排序標準,最後輸出data到mlb.csv(檔案會在電腦的使用者那一個地方)。
#Merge all years' datas
data = df[0]
for k in range(1,14):
data = pd.concat([data,df[k]],axis = 0)
#Sorting data frame by Team and then By names
data.sort_values(["Tm"], axis=0,
ascending=True, inplace=True)
#Write the csv
data.to_csv("mlb.csv",index=False,sep=',')
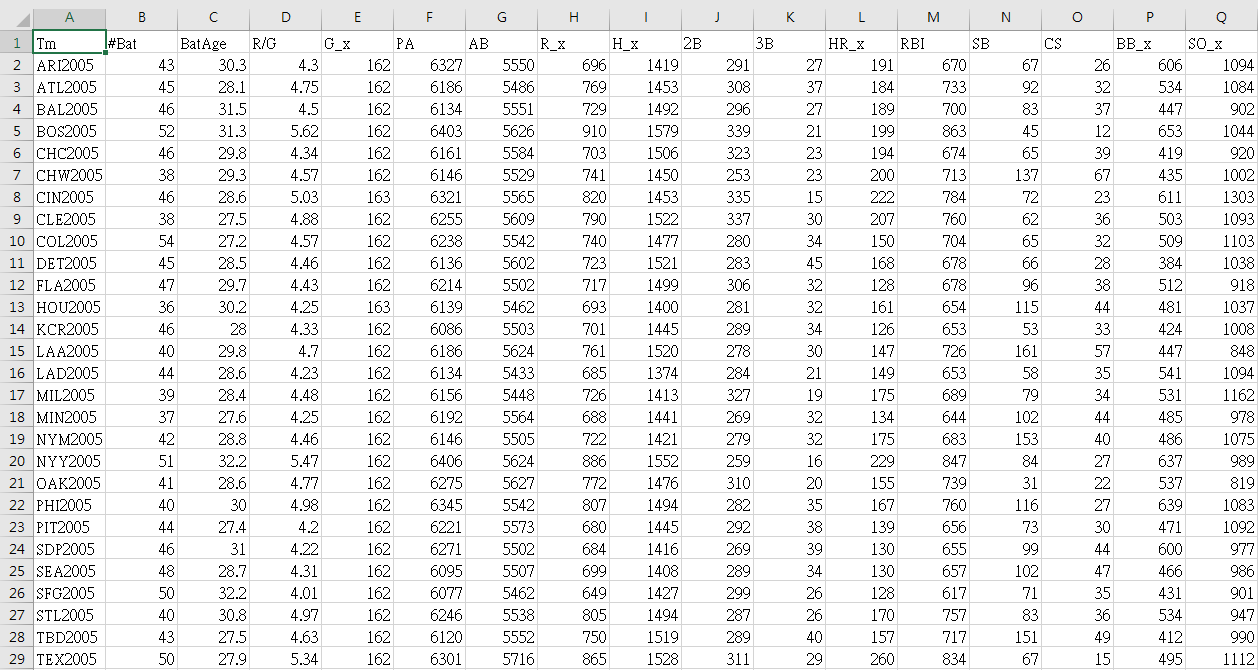
以下是最後匯出的csv: